您现在的位置是:首页 >技术杂谈 >【Linux】线程分离 | 线程库 | C++调用线程 | 线程局部存储网站首页技术杂谈
【Linux】线程分离 | 线程库 | C++调用线程 | 线程局部存储
文章目录
1. 线程分离
1. 为什么要线程分离?
使用 pthread_join 默认是阻塞的 ,即主线程等待 新线程退出
在这个过程中,主线程会直接卡住,就没办法继续向后运行,也就什么都干不了
若主线程 想做其他事情 ,所以就提出了线程分离的概念
默认情况下,新创建的线程是joinable的
即 线程默认被创建出来时,必须被join的, 若不能被join,线程对应的资源就无法释放,进而造成内存泄漏问题
若不关心线程的返回值,join是一种负担,创建一个线程时,提前告诉它,要分离这个线程
2. 具体使用
输入 man pthread_detach

参数为 要分离线程的线程id
一个线程被分离,就无法再被join,如果join,函数就会报错
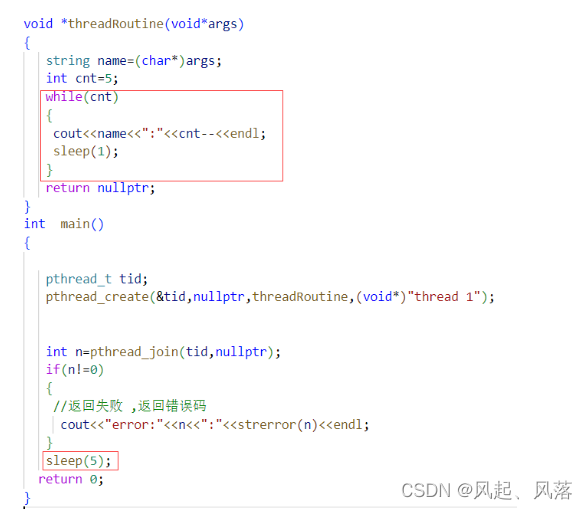
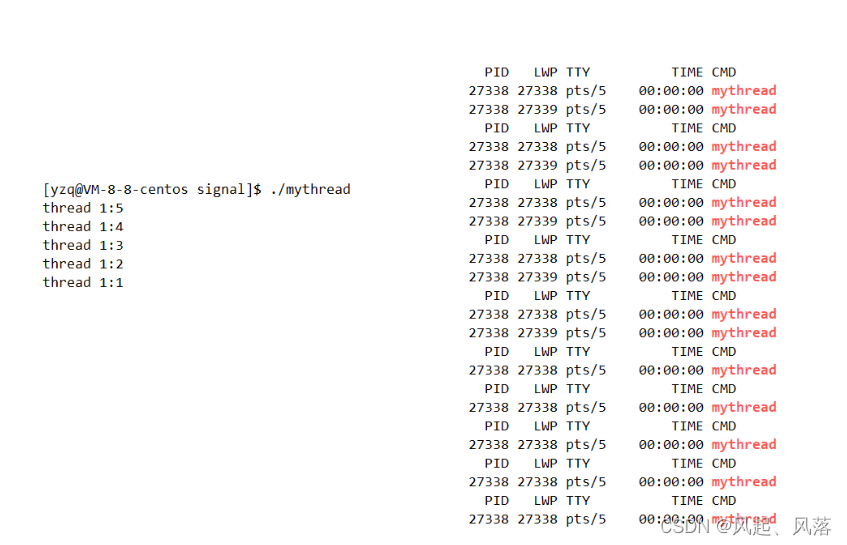
刚开始有主线程和新线程,使用pthread_join 使主线程等待新线程退出
随着自定义函数循环结束,将返回值传给join,新线程结束,
在休眠5秒后,主线程结束

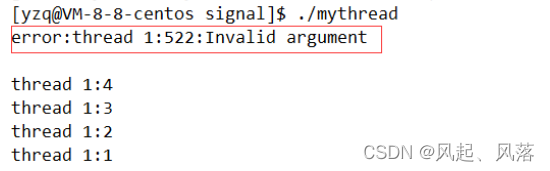
由于使用线程分离后,就不能使用pthread_join ,所以运行可执行程序后会报错
3. 为什么有时候分离在调用join 会正常运行?

在自定义函数中自己把自己分离

可执行程序运行后,发现并没有报错,分离和没分离是一样的
线程被创建的时候,谁先执行并不确定
当使用pthread_create 创建线程时,有可能新线程没有跑,而是主线程继续向下执行,进入join,
然后新线程才把自己分离
join时没有分离,join后才进行分离,所以会正常执行程序
2. 如何理解线程库?

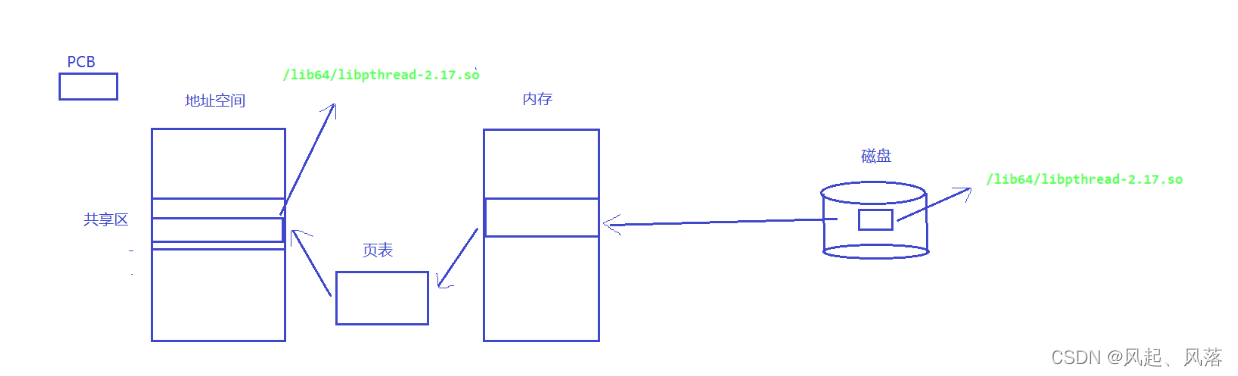
自己形成的可执行程序,要跟库文件关联起来
库要加载到内存中,经过页表映射到地址空间的共享区中
进程中的多线程,可以随时访问库中的代码和数据
每个线程也都可以访问映射过来的pthread库
线程库也需要管理线程,先描述再组织
线程库创建类似的管理线程的TCB

创建进程时,在内核中存在LWP(轻量级进程),为了更好管理LWP,没办法给用提供线程接口,就必须使用pthread库来适配,对线程做管理,与LWP产生关联,包含库中的线程属性 即TCB
在库中通过自己定义的线程控制结构,把内核中的LWP控制起来
如何理解 先描述 在组织?
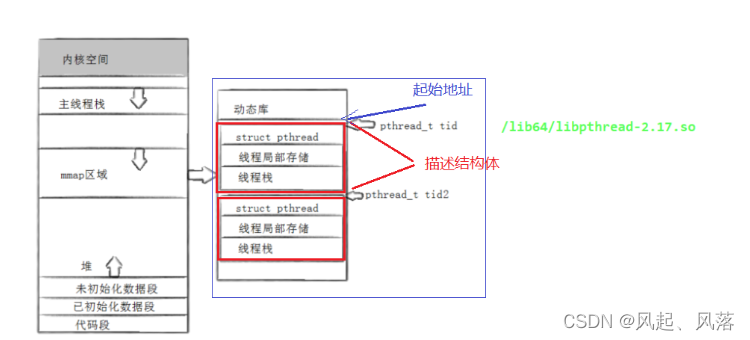
描述:
struct pthread 描述的是线程的其他的一些属性
线程局部存储 (后面会详细讲)
线程独立的栈
整体红色的框 作为一个结构体 等同于 线程的TCB 结构 进行描述
创建一个线程就有一个红色框
组织:
整体红色的框 作为一个结构体
把 每个结构体想象成数组, 可以聚合在一起
找线程,找红色框的起始地址即可 称为 线程ID
pthread_t 就是一个地址数据,用来标识线程相关属性集合、
这个地址是虚拟地址
3. C++中使用多线程
添加头文件 #include < thread>

使用 thread 创建对象th
想要执行什么方法,可以把方法传入对象中
通过对象 . 的方式 可以调用 join detach 等
c++底层是对原生线程库的封装
所以需要在makefile中添加pthread库

可执行程序即可正常运行
4. 线程局部存储

局部变量
局部变量在每个线程中是私有的

cnt在自定义函数中作为局部变量,属于栈上的
每个线程都有自己的栈,所以cnt属于每个线程都有的


三个线程对应的cnt地址是不相同的
三个线程的栈是不同的,局部变量cnt开辟到不同的栈中
cnt是同一个变量,地址绝对不一样
在自定义函数内定义的 局部变量cnt 是在运行时开辟的
编译时就把代码编译好了
局部变量会转化为汇编,以栈顶或者栈底为参考点 减去或者加上 对应数字 就代表是开辟空间
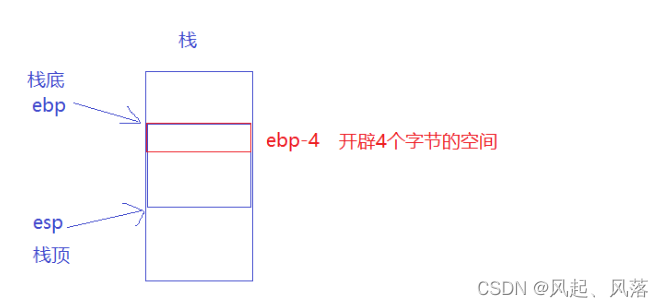
更改 ebp 和 esp 就可以切换栈
ebp 可以是 线程1 、线程2、线程3的栈底,根据调度的不同 ,在不同的栈中开辟不同的变量
全局变量
默认情况下,全局变量是所有线程共享的

创建全局变量g_val,并对其进行修改
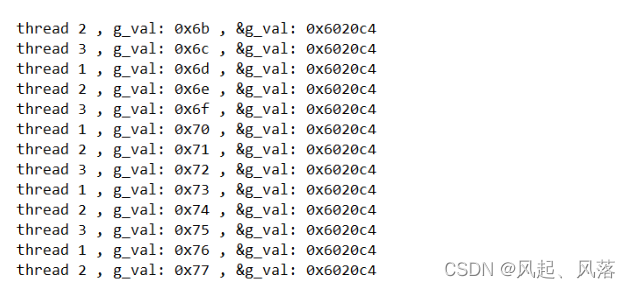
当有多个线程对全局变量修改时,地址是相同的 ,说明全局变量是所有线程共享的

全局变量在已初始化数据段处开辟的空间
若不想g_val 被全局共享 ,则加入 __thread 编译选项
可以构建每个线程之间的局部存储

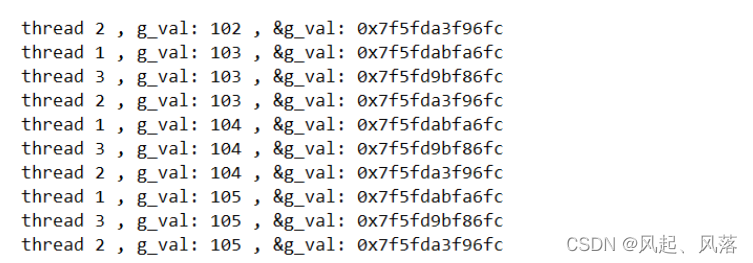
每个线程对应的地址是不一样的
说明全局变量g_val 在每个线程中各自有一份
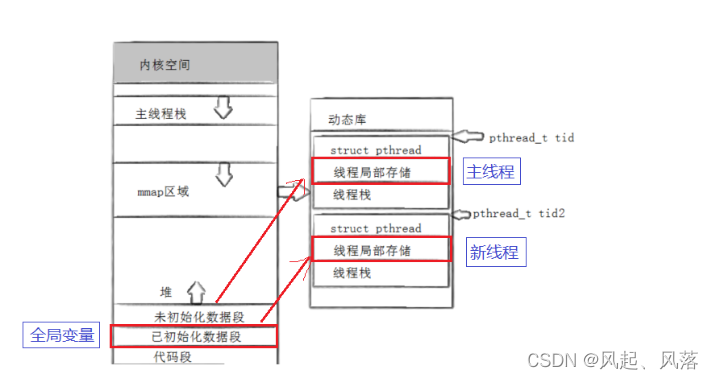
修改后的全局变量 在 线程局部存储 当中
将原来的全局变量给 主线程 以及新线程对应的 线程局部存储 都拷贝一份
每个线程都私有一份,所以地址都不一样






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结