您现在的位置是:首页 >学无止境 >【大数据之Hive】一、Hive概念及框架原理网站首页学无止境
【大数据之Hive】一、Hive概念及框架原理
1 Hive概念
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能,主要完成海量数据的分析和计算。
优点:简化数据开发流程及提高了效率。
2 Hive本质
Hive是一个Hadoop客户端,用于将HQL(Hive SQL)转化成MapReduce程序。
(1)Hive中每张表的数据存储在HDFS;
(2)Hive分析数据底层的实现是MapReduce(也可配置为Spark或者Tez) ;
(3)执行程序运行在Yarn上。
3 Hive框架原理
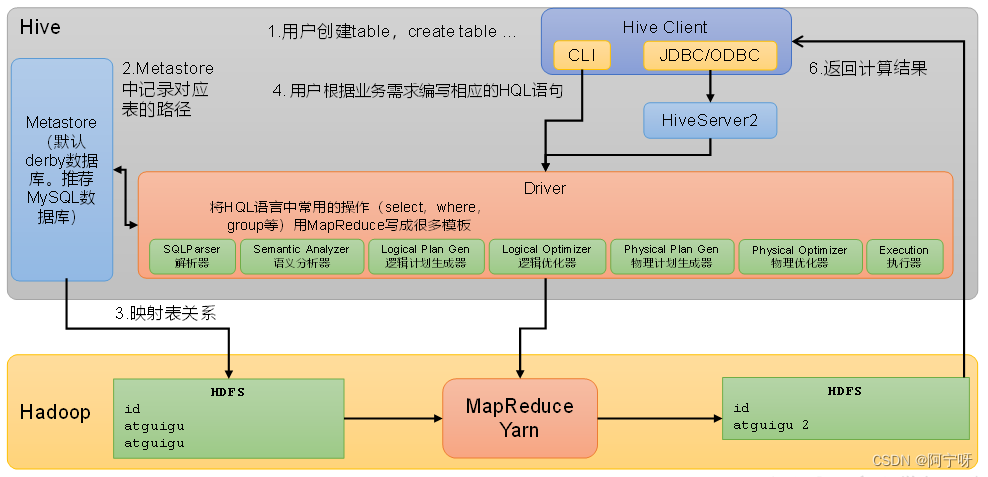
组件:
(1)用户接口:Client
Hive给客户提供了命令行客户端CLI语句(command-line interface)(CLI只能在安装了Hive的本地使用,用户进行建表等)、JDBC/ODBC。
JDBC和ODBC的区别:
1)JDBC的移植性比ODBC好;(通常情况下,安装完ODBC驱动程序之后,还需要经过确定的配置才能够应用。而不相同的配置在不相同数据库服务器之间不能够通用。所以,安装一次就需要再配置一次。JDBC只需要选取适当的JDBC数据库驱动程序,就不需要额外的配置。在安装过程中,JDBC数据库驱动程序会自己完成有关的配置。)
2)两者使用的语言不同,JDBC在Java编程时使用,ODBC一般在C/C++编程时使用。
(2)元数据:Metastore
Metastore只提供元数据的访问接口,不负责存储数据(元数据通常保存在关系型数据库中),表到路径的映射关系保存在元数据中。
元数据包括:用户创建的数据库(默认是default)、表名、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。
(3)HiveServer2
提供JDBC或ODBC的访问接口和用户认证的相关功能。
(4)驱动器:Driver
当用户使用的是命令行客户端CLI时Driver就运行在客户端中,若使用的是JDBC/ODBC客户端Driver就运行在HiveServer2中;
Driver负责编译和提交任务(将一条Hive的SQL语句即HQL编译成MapReduce的计算程序)。
具体工作:
1)解析器(SQLParser):包含词法分析(对用户输入的sql字符串进行逐个字符扫描,根据预置规则识别关键词并生成特殊符号,每个符号成为一个token)和语法分析(对词法分析中输出的token进行分析,将token组合成短句,再将短句组合成一个完整的树状语法结构),将SQL字符串转换成抽象语法树(AST);
2)语义分析(Semantic Analyzer):将AST进一步划分为QeuryBlock(先遍历解析器输出的抽象语法树,将AST中token划分成一个个的查询单元QeuryBlock(可以理解为子查询),并获取元数据信息(原表路径和目标表的路径)赋予查询单元QeuryBlock);
3)逻辑计划生成器(Logical Plan Gen):将语法树生成逻辑计划;
4)逻辑优化器(Logical Optimizer):对逻辑计划进行优化;
5)物理计划生成器(Physical Plan Gen):根据优化后的逻辑计划生成物理执行计划(如生成的MapReduce等);
6)物理优化器(Physical Optimizer):对物理执行计划进行优化(如使用map join优化);
7)执行器(Execution):执行该计划,得到查询结果并返回给客户端。
(5)Hadoop
使用HDFS进行存储,可以选择MapReduce/Tez/Spark进行计算。
Hive组件间配合工作原理:
Hive给客户提供了命令行客户端CLI语句(command-line interface)(CLI只能在安装了Hive的本地使用,)、JDBC/ODBC,用户进行建表等;
Metastore把创建的表的元数据信息保存到数据库中,如果用户在建表时指定了表的hdfs路径,且该hdfs路径下已经有文件,此时Hive表与hdfs文件的内容形成了映射关系;
当用户执行了查询语句,编译和提交任务(将一条Hive的SQL语句即HQL编译成MapReduce的计算程序)的工作由Driver完成,Driver在编译HQL的过程中需要用到元数据信息(因为给Hive提供的是对表的操作,最终编译的MR程序需要输入路径,而表到路径的映射关系保存在元数据中);
当Driver已经完成了编译任务(即得到可执行的MR程序),此时Driver会把任务提交到Yarn上运行;
当MR启动之后会读取原表数据,执行后将计算结果写到目标表的路径或者写到临时目录中;若执行的是查询语句,则查询结果也会被拉取到Hive的客户端。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结