您现在的位置是:首页 >学无止境 >【医学图像】图像分割系列.1网站首页学无止境
【医学图像】图像分割系列.1
医学图像分割是一个比较有应用意义的方向,本文简单介绍三篇关于医学图像分割的论文:
UNeXt(MICCAI2022),PHTrans(MICCAI2022),DA-Net(MICCAI2022)。
目录
UNeXt: MLP-based Rapid Medical Image Segmentation Network, MICCAI 2022
UNeXt: MLP-based Rapid Medical Image Segmentation Network, MICCAI 2022
解读:MICCAI 2022:基于 MLP 的快速医学图像分割网络 UNeXt (qq.com)
论文:https://arxiv.org/abs/2203.04967
代码:https://github.com/jeya-maria-jose/UNeXt-pytorch
基于 Transformer 的 U-Net 变体是近年常用的医学图像分割方法,但是参数量往往不乐观,计算复杂,推理缓慢。本文提出了基于卷积多层感知器(MLP)改进 U 型架构的方法,可以用于图像分割。设计了一个 tokenized MLP 块有效地标记和投影卷积特征,使用 MLPs 来建模表示。这个结构被应用到 U 型架构的下两层中(这里我们假设纵向一共五层)。文章中提到,为了进一步提高性能,建议在输入到 MLP 的过程中改变输入的通道,以便专注于学习局部依赖关系特征。最终,UNeXt 将参数数量减少了 72 倍,计算复杂度降低了 68 倍,推理速度提高了 10 倍,同时还获得了更好的分割性能,如下图所示。

UNeXt 架构:
UNeXt 的设计如下图所示。纵向来看,一共有两个阶段,普通的卷积和 Tokenized MLP 阶段。其中,编码器和解码器分别设计两个 Tokenized MLP 块。每个编码器将分辨率降低两倍,解码器工作相反,还有跳跃连接结构。每个块的通道数(C1-C5)被设计成超参数为了找到不掉点情况下最小参数量的网络,对于使用 UNeXt 架构的实验,遵循 C1 = 32、C2 = 64、C3 = 128、C4 = 160 和 C5 = 256。
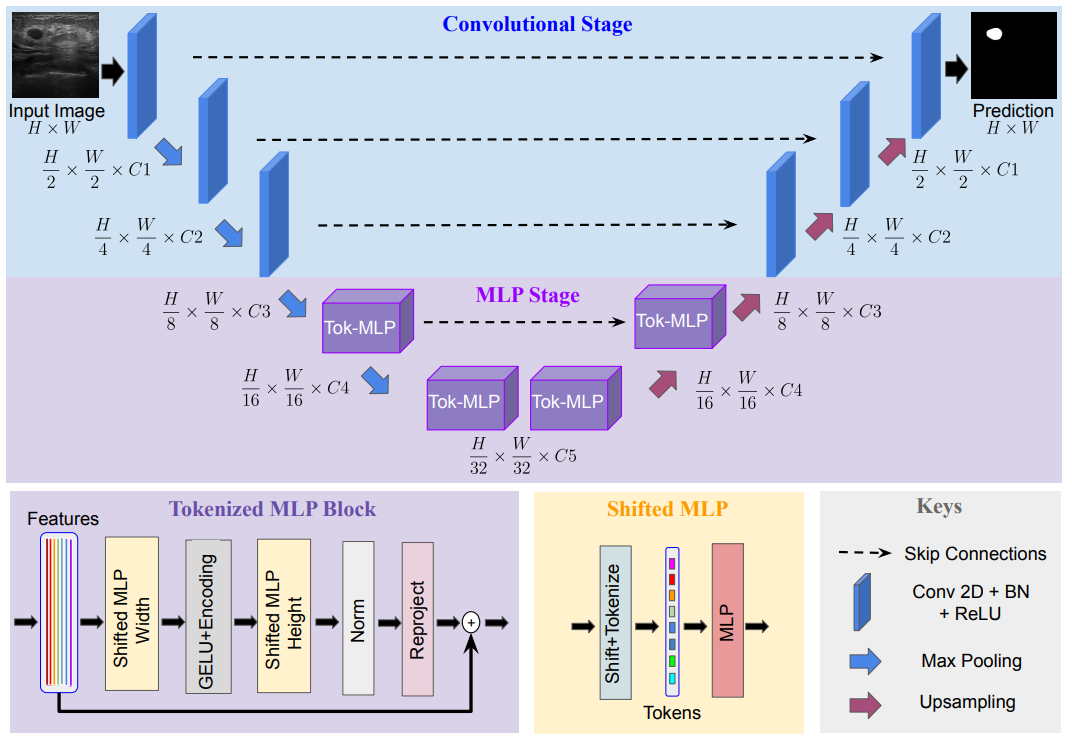
TokMLP 设计思路:
Shifted MLP ,思路类似于 Swin transformer,引入基于窗口的注意力机制,向全局模型中添加更多的局域性。Tokenized MLP 块有 2 个 MLP,在一个 MLP 中跨越宽度移动特征,在另一个 MLP 中跨越高度移动特征,即,特征在高度和宽度上依次移位。论文:“我们将特征分成 h 个不同的分区,并根据指定的轴线将它们移到 j=5 的位置”。其实就是创建了随机窗口,这个图可以理解为灰色是特征块的位置,白色是移动之后的 padding。

tokenized MLP block:

其中 T 表示 tokens,H 表示高度,W 表示宽度。所有这些计算都是在 embedding 维度 H 上进行的,它明显小于特征图的维度 HN×HN,其中 N 取决于 block 大小。
其中,使用DWConv(DepthWise Conv)的原因:
- 有助于对 MLP 特征的位置信息进行编码。MLP 块中的卷积层足以编码位置信息,它实际上比标准的位置编码表现得更好。像 ViT 中的位置编码技术,当测试和训练的分辨率不一样时,需要进行插值,往往会导致性能下降。
- DWConv 使用的参数数量较少。
实验:


PHTrans: Parallelly Aggregating Global and Local Representations for Medical Image Segmentation, MICCAI2022
解读:【MICCAI 2022】PHTrans:并行聚合全局和局部表示以进行医学图像分割 - GiantPandaCV
论文:https://arxiv.org/abs/2203.04568
代码:https://github.com/lseventeen/PHTrans
在医学图像分割上,已经有了许多基于 CNN 和 Transformer 的优秀混合架构,并取得了很好的性能。然而,这些将模块化 Transformer 嵌入 CNN 的方法,还有可以挖掘的空间。
论文提出了一种新的医学图像分割混合架构:PHTrans,它在主要构建块中并行混合 Transformer 和 CNN,分别从全局和局部特征中生成层次表示并自适应聚合它们,旨在充分利用 Transformer 和 CNN 各自的优势以获得更好的分割性能。具体来说,PHTrans 沿用 U 形设计,在深层引入并行混合模块,其中卷积块和修改后的 3D Swin Transformer 块分别学习局部特征和全局依赖关系,然后使用 sequence-to-volume 操作统一输出维度以实现特征聚合。最后在 BCV 和 ACDC 数据集上验证了其有效性。
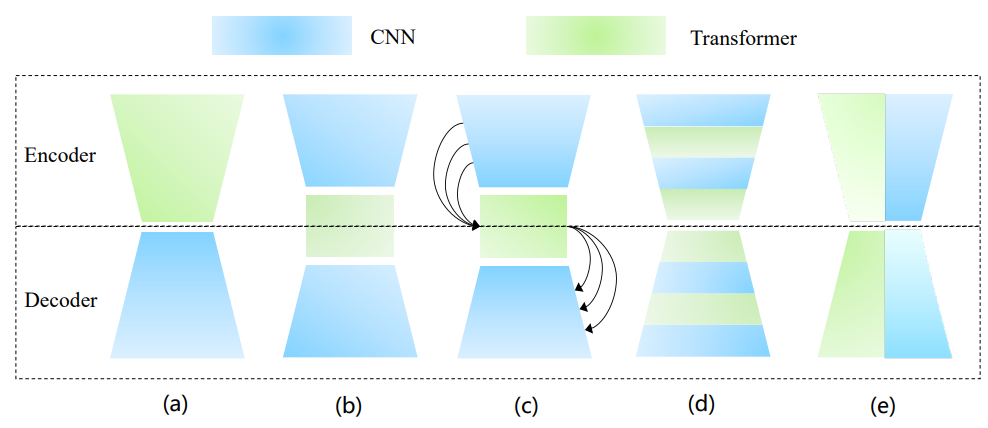
(a)~(d) 是几种流行的基于 Transformer 和 CNN 的混合架构,既将 Transformer 添加到以 CNN 为 backbone 的模型中,或替换部分组件。其中(c) 与 (b) 的区别是通过 Transformer 桥接从编码器到解码器的所有阶段,捕获多尺度全局依赖。(d) 表示将 Transformer 和 CNN 交织成一个混合模型,其中卷积编码精确的空间信息,而自注意力机制捕获全局上下文信息。
图 (e) 表示二者的并行。在串行组合中,卷积和自注意力机制无法贯穿整个网络架构,难以连续建模局部和全局表示,因此这篇论文里认为并行可以充分发挥它们的潜力。
PHTrans 架构
如图 (b),其主要构建块由 CNN 和 Swin Transformer 组成,以同时聚合全局和局部表示。图 (a) 依旧遵循的 U 形架构设计,在浅层只是普通的卷积块,在深层引入了 sequence-to-volume 操作来实现 Swin Transformer 和 CNN 在一个块中的并行组合。
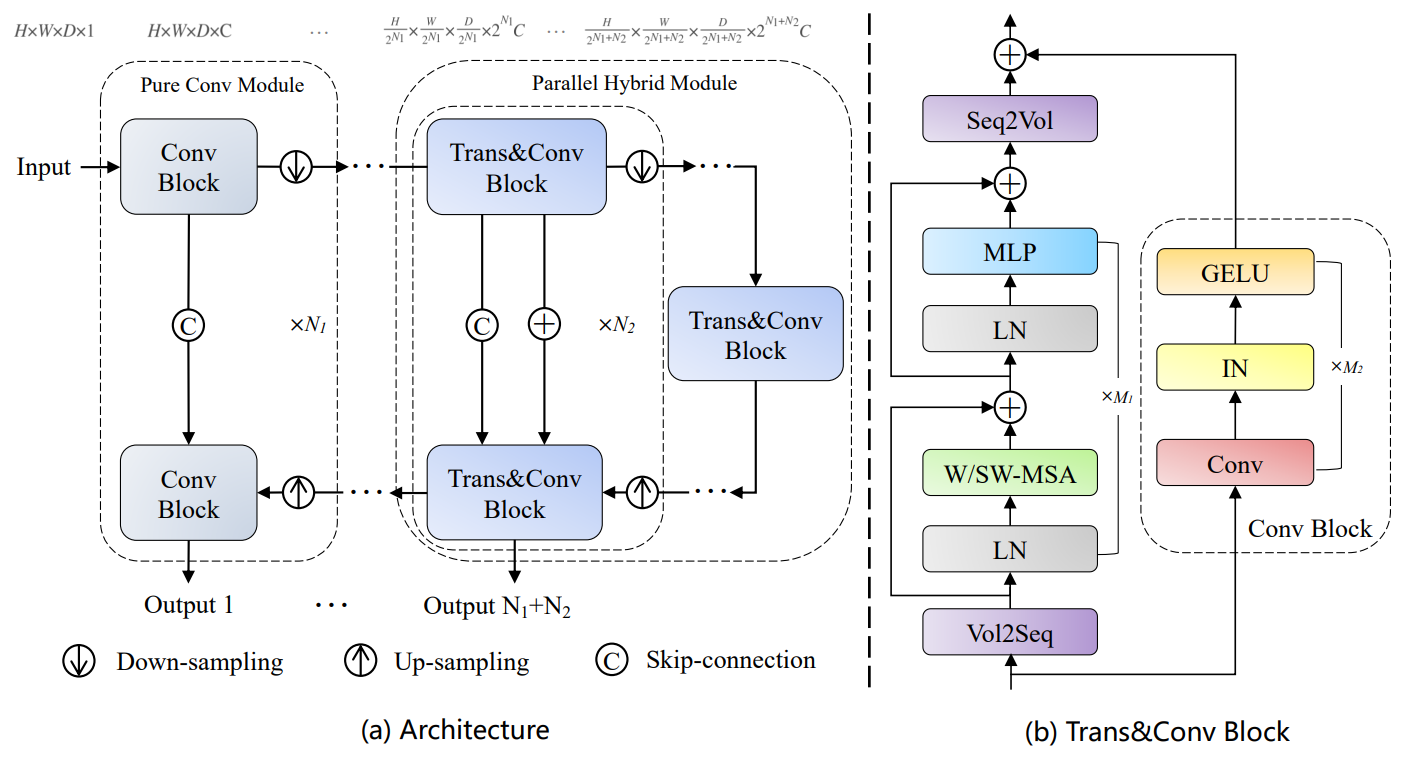
PHTrans 的编码器,对于 H×W×D 的输入volume(3D 医学图像),首先使用几个纯卷积模块得到 volume。然后输入到 Trans&Conv Block 重复 N2 次。对于解码器同样基于纯卷积模块和并行混合模块构建,并通过跳跃连接和加法操作融合来自编码器的语义信息。此外,在训练期间在解码器的每个阶段都使用深度监督机制,产生总共 N1 + N2 个输出,其中应用了由交叉熵和 DICE 的联合损失。深度监督,即网络的中间部分添加了额外的 Loss。
Trans&Conv block
缩小比例的特征图分别输入 Swin Transformer (ST) 块和卷积 (Conv) 块,分别在 ST 块的开头和结尾引入 Volume-to-Sequence (V2S) 和 Sequence-to-Volume (S2V) 操作来实现 volume 和 sequence 的变换,使其与 Conv 块产生的输出兼容。W-MSA 能够降低计算复杂度,但是不重合的窗口之间缺乏信息交流,这样其实就失去了 Transformer 利用 Self-Attention 从全局构建关系的能力,于是用 SW-MSA 来跨窗口进行信息交流(跨窗口连接),同时保持非重叠窗口的高效计算。
每个 head 中的 self-attention 计算如下:
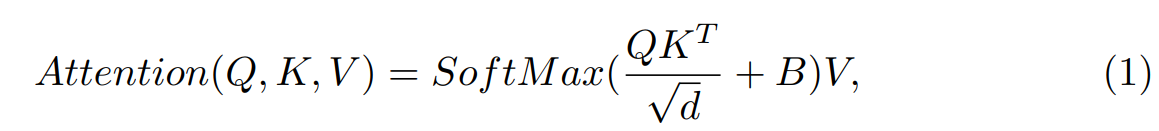
Q, K, V ∈ L×d 是查询、键和值矩阵,d 是查询 / 键维度,B ∈ L×L 是相对位置偏差。通过加法运算融合 ST 块和 Conv 块的输出。 编码器中 Trans&Conv 块的计算过程:
xi−1 是编码器第 i−1 阶段的下采样结果。在解码器中,除了跳跃连接之外,还通过加法操作来补充来自编码器的上下文信息。因此,解码器中的 Trans&Conv 块计算过程:

实验:
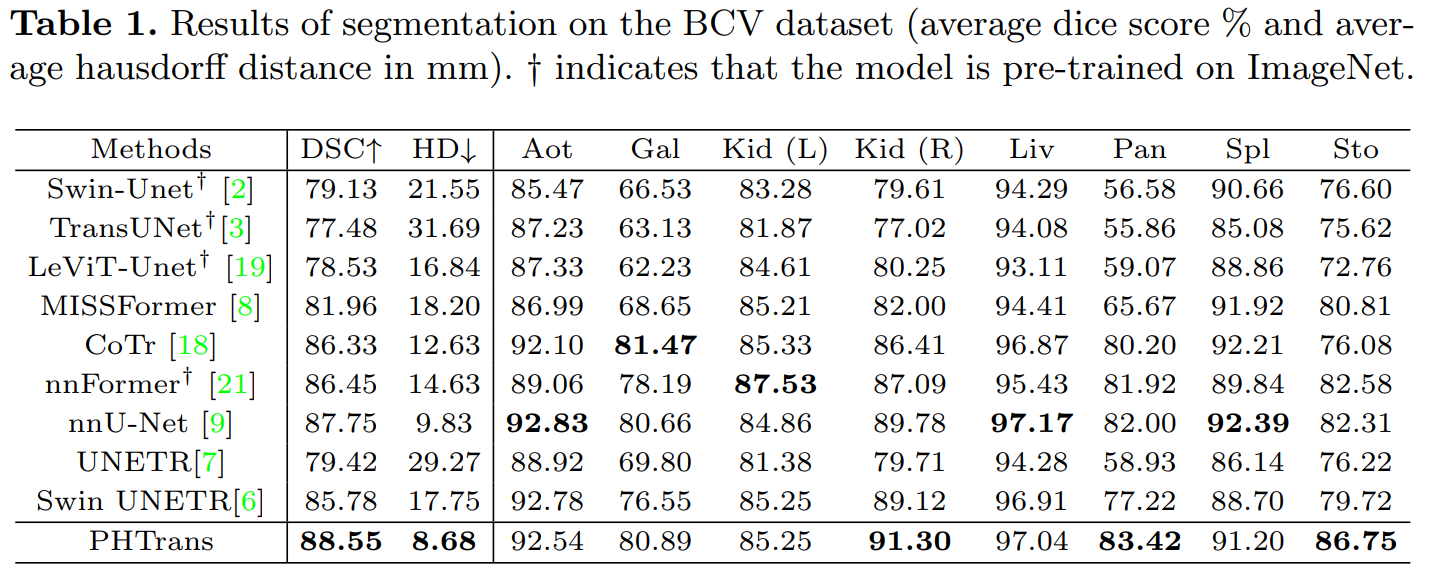

DA-Net: Dual Branch Transformer and Adaptive Strip Upsampling for Retinal Vessels Segmentation, MICCAI2022
解读:MICCAI 2022:使用自适应条形采样和双分支 Transformer 的 DA-Net - GiantPandaCV
论文:https://dl.acm.org/doi/10.1007/978-3-031-16434-7_51
代码:未找到
目前的视网膜血管分割方法根据输入类型大致分为 image-level 和 patches-level 方法,为了从这两种输入形式中受益,这篇文章引入了一个双分支 Transformer 模块,被叫做 DBTM,它可以同时利用 patches-level 的本地信息和 image-level 的全局上下文信息。视网膜血管跨度长、细且呈条状分布,传统的方形卷积核表现不佳,也是为了更好地捕获这部分的上下文信息,进一步设计了一个自适应条状 Upsampling Block,被叫做 ASUB,以适应视网膜血管的条状分布。

DA-Net结构:

共享 encoder 包含五个卷积块,DBTM 在 encoder 之后,最后是带 ASUB 的 decoder。首先,原眼底图像很常规的被分成 N^2 个 patches,同时将原眼底图像也下采样 N 倍。将它们一起送入共享 encoder,分别得到相应的特征图 F(i) 和 F′,这里的共享指的是两个 encoder 分支的权重共享,两个分支可以通过合并批次并行操作。随后,这两个分支的输出通过 DBTM 进行通信,DBTM 可以向每个补丁广播长距离的全局信息。U 型网络中间还有普通的跨层连接,最后,再通过 ASUB 的 decoder 后,得到预测的分割结果。
DBTM:Local Patches Meet Global Context

首先将经过 flatten 和投影的特征图 F(i) 和 F′ 作为输入 tokens ,其中加入训练过的 position embeddings 以保留位置信息。然后 tokens 被送入 Transformer Layer。不同的是,设计了一个特殊的 self-then-cross 的 pipeline,将两个分支的输入混合起来,称为双分支 Transformer 模块。第一个 Transformer Layer 作为 Q,第二个 Transformer Layer 作为 K 和 V。具体来说,首先,这两个分支的输入标记分别用自注意机制模拟 image-level 和 patches-level 的长距离依赖。然后,交叉注意机制被用于两个分支的 tokens 之间的通信。在交叉注意机制中,将 patches-level 的标记表示为查询 Q, image-level 分支的标记表示为下图中多头自我注意(MSA)层的键 Q 值 V。整体设计是很简单的,实现了”Local Patches Meet Global Context“。
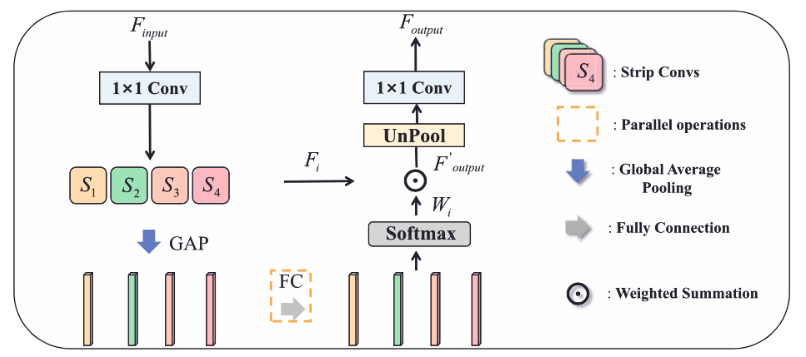
ASUB block:
视网膜血管的一些固有特征导致了其分割困难,比如视网膜血管的分支很细,边界很难区分,而且视网膜血管之间的关系很复杂。在这些情况下,视网膜血管周围的背景信息对视网膜血管的分割至关重要。如下图所示,传统的方形卷积核在正常的上采样块中不能很好地捕捉线性特征,并且不可避免地引入了来自邻近的不相关信息。为了更好地收集视网膜血管周围的背景信息,提出了 Adaptive Strip Upsampling Block(ASUB),它适合于长而细的视网膜血管分布。


在(c)中,一共有四种类型的条状卷积核,捕捉水平(S1)、垂直(S2)、左对角线(S3)和右对角线(S4)方向上的信息。分析 ASUB 的思路,首先,使用一个 1×1 的 Conv 来将特征图的维度减半,以减少计算成本。然后,利用四个带状卷积来捕捉来自不同方向的上下文信息。此外,做全局平均池化(GAP)来获得通道维度的特征图。在通道维度上获得特征向量,并使用全连接层来学习每个带状卷积的通道方向的注意力向量。之后,应用softmax 来产生通道融合权重 Wi , i∈{1, 2, 3, 4}。 最后,我们用学到的自适应权重对每个带状卷积 Fi 的输出进行加权,得到特征图,特征图是 4 个 Fi*Wi 求和。 最后用 1×1 的 Conv 恢复维度,得到最终输出 Foutput。同时,这部分是会增加网络学习负担的。
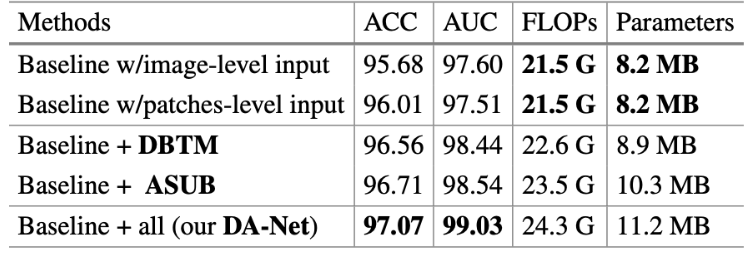
实验:







站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结