您现在的位置是:首页 >其他 >6.selenium的使用网站首页其他
6.selenium的使用
目录
2.定位出同一类元素(tag_name, name, class name等)
一、unittest框架 unittest.TestCase
Selenium2
一、定位一组元素
1.打开本地的HTML页面
file:///D:/%E4%BB%A3%E7%A0%81%E4%BF%9D%E5%AD%98/HTML/form.html
"D:代码保存HTMLform.html"
出现很多%字母,是由于中文出现的乱码
拼成一个URL: file: +/// +文件绝对路径
首先需要import os
用到 os.path.abspath(文件的绝对路径)
2.定位出同一类元素(tag_name, name, class name等)
然后根据需要定位的元素的特征(type)去甄别出要定位的具体元素,然后进行操作
定位一组元素,必须是driver.find_elements_by,如果使用element会报错
from selenium import webdriver
import time
import os #打开本地网页需要导入的包
driver = webdriver.Chrome()
url = "file:///" + os.path.abspath("D:/代码保存/HTML/form.html") #文件所在地址复制得到
driver.get(url)
time.sleep(3)
#给所有复选框打钩
buttons = driver.find_elements_by_tag_name("input")
for button in buttons:
if button.get_attribute('type') == 'checkbox':
button.click()
time.sleep(5)
driver.quit()二、多层框架的定位
iframe 框架里面的嵌套框架——解决不同层框架上的页面元素定位
driver.switch_to.frame("f1")
(1)如果要定位一个层级框架中的元素,必须先调到这个框架层级,才可以定位
(2)如果要定位某一个层级,必须从默认页面跳转
driver.switch_to_default_content()
default context -> f1 f1 -> f2 可以
default context -> f2 f2 ->f1 不可以
(3)层级定位
(4)下拉框选择
方法一:直接用xpath定位
方法二:先定位出一组元素(tag name等),然后根据元素的属性进行过滤筛选,再进行操作
方法三:先定位出一组元素(tag name等),通过数组下标的方式进行定位
(5)alert弹框的处理
driver.find_element_by_id("tooltip".click() #定位元素点击,使得弹出框出现
alert = driver.switch_to.alert #定位弹出框/获得弹出框的操作句柄
alert.accept() #关闭alert
在alert弹框输入响应的信息
alert = driver.switch_to.alert #先获得弹出框的操作句柄
alert.end_keys("我爱夏天") #再用send_keys去输入信息
(6)div块的处理
适用于页面复杂,元素非常多,没有id ,并且name,或者tag name重复
1.首先定位div模块
2.在定位到的div模块的基础上,去精确寻找这个元素所在的div模块
div1 = driver.find_element_by_class_name("maodal-body")
div1.find_element_by_link_text("click me").click()
(7)上传文件
定位上传按钮
send_keys(需要长传文件的绝对路径 + 文件名字)
(8)为啥有的第三方网站的页面元素无法定位
出于安全性的考虑,防止有人使用自动化脚本暴力破解密码
selenium3
一、unittest框架 unittest.TestCase
UI功能单元测试
1.测试固件(框架里面的固定方法)
setup(),测试环境和数据的初始化
tearDown() 环境的清理工作
2.测试用例
测试用例方法:test_开头 运行脚本的时候默认自动会运行test_开头的方法
普通方法不能以test_开头 普通方法被test_开头的方法调用的时候才会运行
3.测试套件
把测试用例组织到一起进行一个整体的测试
必须以继承的方式来使用它,Python也是一种面向对象的语言 class
(1)addTest 把不同文类里面的测试方法一个一个添加
(2)把一个文件中一个类里面的所有的测试用例都添加进去的方法
unittest.makeSuite (脚本名称. 类名称) 可以把一个类中的所有的测试方法添加到测试套件中
unittest.TestLoader().loadTestsFromTestCase(脚本名称. 类名称) 把一个文件夹中的所有测试方法创建成一个测试套件返回
(3)把一个文件夹下的某种方式命名的所有测试用例都添加到测试套件中
discover
unittest.defaultTestLoader.discover("../src232", pattern= "testbaidu*.py",top_level_dir=None ,)
文件夹 运行测试用例所在的文件名称 默认的参数
运行测试套件后,控制台打印信息的详细程度:
verbosity = 0 不打印正确的,只打印运行错误的测试用例以及错误原因
verbosity = 1 运行成功的用点来表示,运行失败的用F表示,最终抛出运行失败的异常
verbosity = 2 最详细的打印,显示全部信息
二、unittest具体使用
1.测试用例的执行顺序
0-9 A-Z a-z
2.忽略测试用例的执行
对于不想运行的测试用例,使用标签:
@unittest.skip("skipping")
3.unnittest断言
测试的最终结果就是判断实际结果是否和预期结果一致
断言:就是判断实际结果是否和预期结果一致
self.assertEqual(arg1,arg2,msg='')预判表达式arg1和arg2相等
self.assertNotEqual(arg1,arg2,msg='')预判表达式arg1和arg2不相等
self.assertT(arg1True,msg='')预判表达式arg1为true
4.HTML报告
运行了一个测试套件,里面有上百个测试用例,如何集中并且清晰的查看测试用例执行结果
生成HTML报告的步骤:
(1)需要创建一个存放HTML的文件夹
curpath = sys.path[0]
#当前路径下resultreport文件夹不存在的时候,就创建一个
if not os.path.exits(curpath+'/resultreport'):
os.makedir(curpath+'/resultreport')
(2)解决重复命名的问题(用当前时间来命名)
now = time.strftime("%Y-%m-%d-%H %M %S"),time.localtime(time.time())
filename = curpath + '/resultreport' + now +'resultreport.html'
(3)报告的输出
with open(filename, 'wb') as fp:
#括号里的参数是HTML报告里面的参数
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u"测试报告",
description=u"用例执行情况", verbosity=2)
suit = createsuite( )
runner.run(suite)
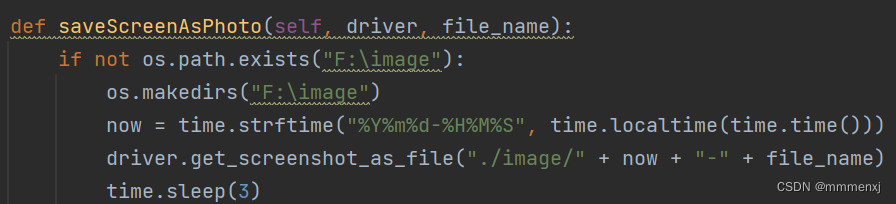
5.异常捕捉和错误截图
目的:保留测试结果现场
. /代表当前路径
错误截图的API: get_screenshot_as_file
6.数据驱动:用测试数据来驱动测试用例代码执行
(1)安装ddt pip install ddt
pip show ddt
(2)导包
from ddt import ddt ,unpack解绑,data,file_data
同时在类上面使用标签 @ddt
(3)数据驱动的方式
@data(value) 一次传入一个参数,括号中写参数
@data(value1,value2...) 一次传入多个参数,需要用@unpack映射
@file_data("json文件")
@data(*解析数据的方法 (txt/csv文件))






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结