您现在的位置是:首页 >技术杂谈 >SQL执行过程网站首页技术杂谈
SQL执行过程
1. select 语句执行过程
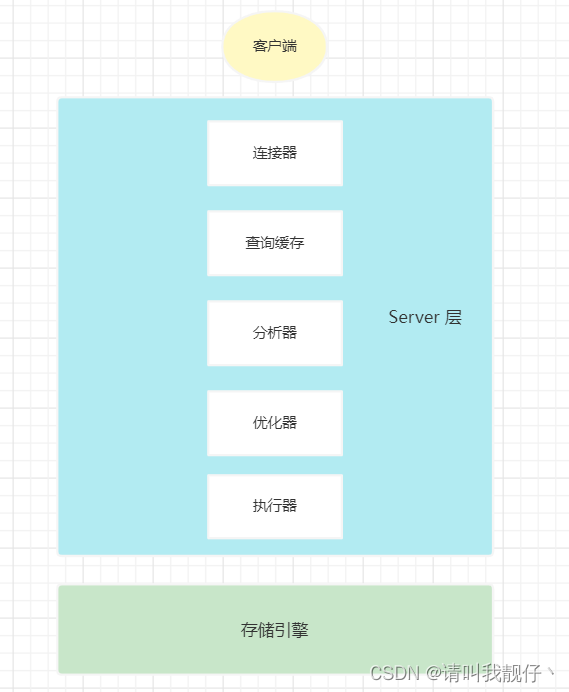
一条 select 语句的执行过程如上图所示
1、建立连接
连接器会校验你输入的用户名和密码是否正确,如果错误会返回提示,如果正确,连接器会查询当前用户对于的权限。连接器的作用就是校验用户权限
2、查询缓存
MySQL 中有个缓存的概念,当你在执行一条 SQL 查询语句时,MySQL 会先去缓存中查看是否有对应的记录,如果有,则直接返回,如果没有,则取数据库中查询,查询完成后再放入缓存中。这个查询缓存的目的是为了加快 MySQL 查询速度。
这里建议你将这个缓存的选项关闭上,因为在实际项目中,这个查询缓存用处不大,为什么这么说。因为当有 update、或者 delete 语句执行时,这张的表查询缓存就会失效,下次查询还是需要从数据库中查询,所以通常来说查询缓存并不能提高性能。
3、分析器
分析器作用是进行词法分析,语法分析。对于 select 语句而言,MySQL 拿到这条 SQL 语句后,识别出 select 关键词,知道这是一条查询语句,然后再取识别 from 以及表名,识别字段,这个步骤是词法分析。词法分析完成后还需要进行语法分析,也就是判断这条语句的语法是否正确,比如你 select 写成了 selct,那么语法分析就会检验出来
4、优化器
优化器职责是对 sql 语句进行优化,比如这条语句该用什么索引,sql 顺序需不需要调整。
5、执行器
经过上面几部分析,就来到了执行器,开始从数据库查询数据了。查询数据前会校验一下有无权限该表的权限,如果没有则返回错误提示。有权限则开始扫描行,查看是否满足条件,满足条件的结果放入结果集中。
2. update 语句执行过程
update 语句执行过程和 select 语句相同,也需要经过连接、分析器、优化器、执行器这些步骤。不同的是,在 update 执行过程中涉及到两个日志,一个是 redo log,一个是 binlog
redo log
首先需要明确的是,redo log 是 Inndb 存储引擎独有的,其他引擎没有。redo log 主要作用是记账
举个通俗易懂的例子,你是掌柜的,开了一家店铺,店铺生意很好,每天都有很多人来,有些人都是常客,吃饭都是月结,于是你有一个账本,账本上记录了谁欠你多少钱,店铺刚开张时,客人少,你一笔笔记录,没问题,后来客人多了,你发现账本查找起来很费时,影响效率,于是你找了一个黑板,客人来了以后,消费了多少钱,你就记在黑板上,等到不忙的时候在汇总到账本上。
这里的黑板就是 redo log,账本就是 MySQL 数据库磁盘,这么做的原因是为了提高效率,不然 MySQL 每一次操作都要写入到磁盘中,效率很低,有了 redo log 以后,每次 update 操作,我只需要写到内存上,然后记录到 redo log 中即可返回,这样速度快了很多。等到空闲的时候,再将 redo log 中的数据写入到磁盘中进行持久化。
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么这块“粉板”总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写,如下面这个图所示。
write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。
write pos 和 checkpoint 之间的是“粉板”上还空着的部分,可以用来记录新的操作。如果 write pos 追上 checkpoint,表示“粉板”满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下。
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。
要理解 crash-safe 这个概念,可以想想我们前面赊账记录的例子。只要赊账记录记在了粉板上或写在了账本上,之后即使掌柜忘记了,比如突然停业几天,恢复生意后依然可以通过账本和粉板上的数据明确赊账账目。
binlog
上面说的 redo log 是引擎层的日志,那么 binlog 则是 MySQL Server 层的日志
binlog 主要是记录 MySQL 的原始操作语句,比如 update user set name = “张三” where id = 2,binlog 就将它记录下来
binlog 和 redolog 区别
redolog 是引擎层面的日志,是 Inndb 独有的,binlog 是 Server 层的,所有引擎都可以使用
redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
两阶段提交
update 语句执行的内部流程
update user set name = "张三" where id = 2
执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
执行器拿到引擎给的行数据,把这个值修改成张三
引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
两阶段提交就是先提交 redolog,然后写入 binlog,binlog 写入成功后再提交 redolog






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结