您现在的位置是:首页 >技术交流 >neo4j图形数据库网站首页技术交流
neo4j图形数据库
目录
1. neo4j简介
1.1 什么是图形数据库
图数据库是基于图论实现的一种NoSQL数据库,其数据存储结构和数据查询方式都是以图论(它以图为研究对象图论中的图是由若干给定的点及连接两点的线所构成的图形)为基础的, 图数据库主要用于存储更多的连接数据。
1.2 什么是neo4j
Neo4j是一个开源的NoSQL图形数据库,2003 年开始开发,使用 scala和java 语言,2007年开始发布。
• 是世界上最先进的图数据库之一,提供原生的图数据存储,检索和处理;
• 采用属性图模型(Property graph model),极大的完善和丰富图数据模型;
• 专属查询语言 Cypher,直观,高效;
1.3 neo4j的特性
• SQL就像简单的查询语言Neo4j CQL
• 它遵循属性图数据模型
• 它通过使用Apache Lucence支持索引
• 它支持UNIQUE约束
• 它包含一个用于执行CQL命令的UI:Neo4j数据浏览器
• 它支持完整的ACID(原子性,一致性,隔离性和持久性)规则
• 它采用原生图形库与本地GPE(图形处理引擎)
• 它支持查询的数据导出到JSON和XLS格式
• 它提供了REST API,可以被任何编程语言(如Java,Spring,Scala等)访问
• 它提供了可以通过任何UI MVC框架(如Node JS)访问的Java脚本
• 它支持两种Java API:Cypher API和Native Java API来开发Java应用程序
1.4neo4j的优点
• 它很容易表示连接的数据
• 检索/遍历/导航更多的连接数据是非常容易和快速的
• 它非常容易地表示半结构化数据
• Neo4j CQL查询语言命令是人性化的可读格式,非常容易学习
• 使用简单而强大的数据模型
• 它不需要复杂的连接来检索连接的/相关的数据,因为它很容易检索它的相邻节点或关系细节没有连接或索引
1.5 neo4j的构建元素
neo4j图数据库主要有以下构建元素:
节点、属性、关系、标签、数据浏览器
节点
节点(Node)是图数据库中的一个基本元素,用来表示一个实体记录,就像关系数据库中的一条记录一 样。在Neo4j中节点可以包含多个属性(Property)和多个标签(Label)。
• 节点是主要的数据元素
• 节点通过关系连接到其他节点
• 节点可以具有一个或多个属性(即,存储为键/值对的属性)
• 节点有一个或多个标签,用于描述其在图表中的作用
属性
属性(Property)是用于描述图节点和关系的键值对。其中Key是一个字符串,值可以通过使用任何
Neo4j数据类型来表示
• 属性是命名值,其中名称(或键)是字符串
• 属性可以被索引和约束
• 可以从多个属性创建复合索引
关系
关系(Relationship)同样是图数据库的基本元素。当数据库中已经存在节点后,需要将节点连接起来
基于方向性,Neo4j关系被分为两种主要类型:
• 单向关系
• 双向关系
标签
标签(Label)将一个公共名称与一组节点或关系相关联, 节点或关系可以包含一个或多个标签。 我们 可以为现有节点或关系创建新标签, 我们可以从现有节点或关系中删除标签。
• 标签用于将节点分组
• 一个节点可以具有多个标签
• 对标签进行索引以加速在图中查找节点
• 本机标签索引针对速度进行了优化
Neo4j Browser
一旦我们安装Neo4j,我们就可以访问Neo4j数据浏览器
2. 安装部署
2.1 环境说明
系统版本:
[root@localhost bin]# cat /etc/redhat-release
CentOS Linux release 7.8.2003 (Core)
软件版本:
neo4j-community-3.5.28-unix.tar.gz
2.2 下载安装包
[root@localhost src]# curl -O http://dist.neo4j.org/neo4j-community-3.5.28-unix.tar.gz
[root@localhost src]# ls
debug kernels neo4j-community-3.5.28-unix.tar.gz
2.3 解压安装包
[root@localhost src]# tar xf neo4j-community-3.5.28-unix.tar.gz -C /usr/local/
2.4 配置安装jdk环境
下载或者用xftp上传jdk安装包:
[root@localhost src]# ls
debug jdk-8u131-linux-x64.tar.gz kernels neo4j-community-3.5.28-unix.tar.gz
解压
[root@localhost src]# tar xf jdk-8u131-linux-x64.tar.gz -C /usr/local/
[root@localhost src]# cd /usr/local/
[root@localhost local]# ls
bin etc games include jdk1.8.0_131 lib lib64 libexec neo4j-community-3.5.28 sbin share src
[root@localhost local]# mv jdk1.8.0_131/ java
[root@localhost local]# vim /etc/profile
末尾添加
#JAVA_HOME
export JAVA_HOME=/usr/local/java
#JRE_HOME
export JRE_HOME=/usr/local/java/jre
#CALSSPATH
export CLASSPATH=$CLASSPATH:${JAVA_HOME}/lib:${JRE_HOME}/lib
#PATH
export PATH=$PATH:${JAVA_HOME}/bin:${JRE_HOME}/bin
重新加载配置文件,查看java版本
[root@localhost local]# source /etc/profile
[root@localhost local]# java -version
java version "1.8.0_131"
2.5 配置neoj4全局变量
[root@localhost src]# vim /etc/profile
末尾添加
export NEO4J_HOME=/usr/local/neo4j-community-3.5.28
export PATH=$PATH:$NEO4J_HOME/bin
[root@localhost src]# source /etc/profile
[root@localhost ~]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/usr/local/java/bin:/usr/local/java/jre/bin:/usr/local/java/bin:/usr/local/java/jre/bin:/usr/local/java/bin:/usr/local/java/jre/bin:/usr/local/neo4j-community-3.5.28/bin
2.6 修改neo4j配置文件
[root@localhost src]# cd /usr/local/neo4j-community-3.5.28/conf/
[root@localhost conf]# vim neo4j.conf
修改相应配置如下
修改22行,在前面加个#,可以任意路径读取文件
22 #dbms.directories.import=import
修改35行和36行,设置jvm初始堆内存和jvm最大堆内存
生产环境给的jvm最大内存越大越好,但是要小于机器的物理内存
35 dbms.memory.heap.initial_size=512m
36 dbms.memory.heap.max_size=512m
修改46行,可以认为这个是缓存,如果机器配置高,这个越大越好
46 dbms.memory.pagecache.size=10g
修改54行,去掉#,可以远程通过ip访问neo4j数据库
54 dbms.connectors.default_listen_address=0.0.0.0
默认 bolt端口是7687,http端口是7474,https关口是7473,不修改下面3项也可以
修改71行,去掉#,设置http端口为7687,端口可以自定义,只要不和其他端口冲突就行
71 #dbms.connector.bolt.listen_address=:7687
75 #dbms.connector.http.listen_address=:7474
79 #dbms.connector.https.listen_address=:7473
修改227行,去掉#,允许从远程url来load csv
245 dbms.security.allow_csv_import_from_file_urls=true
修改254行,设置neo4j可读可写
265 dbms.read_only=false
2.7 服务基本操作
启动:
[root@localhost ~]# neo4j start
查看运行状态
[root@localhost ~]# neo4j status
服务停止
[root@localhost ~]# neo4j stop
服务重启
[root@localhost ~]# neo4j restart
2.8 测试访问
浏览器访问:
192.168.5.56:7474/browser/
初始用户名和密码为neo4j
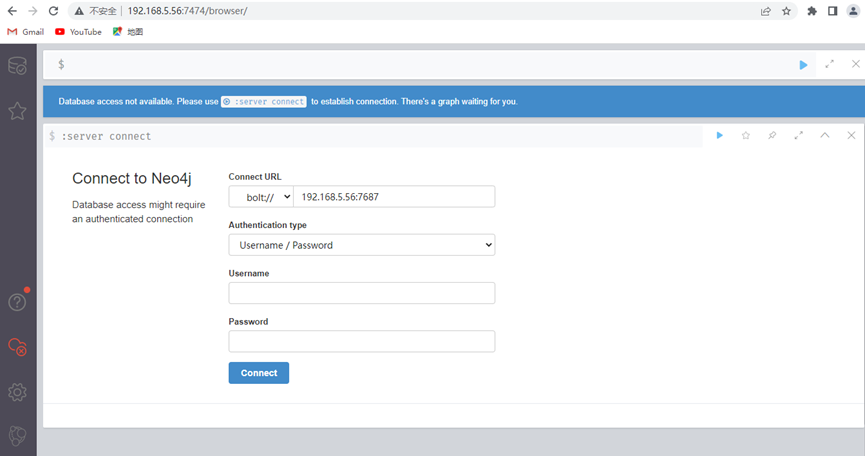
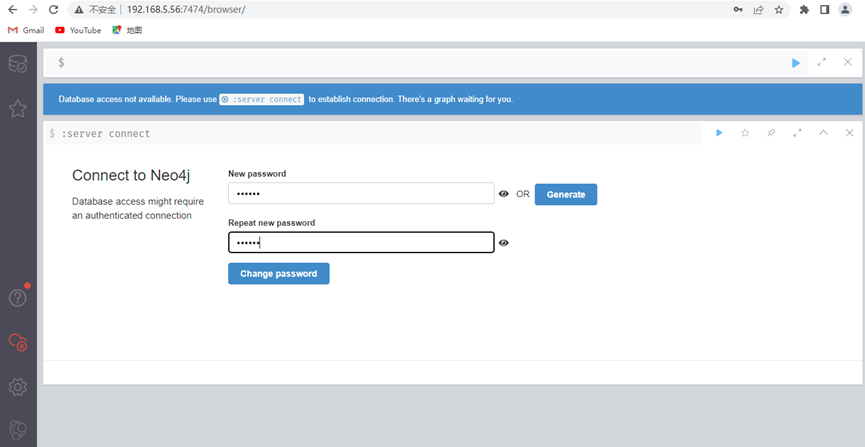
登录之后会提醒你更改密码
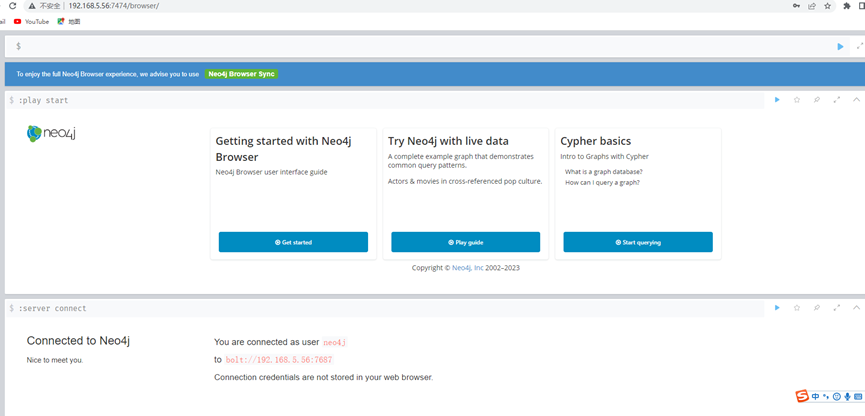
3. 使用DBeaver连接neo4j
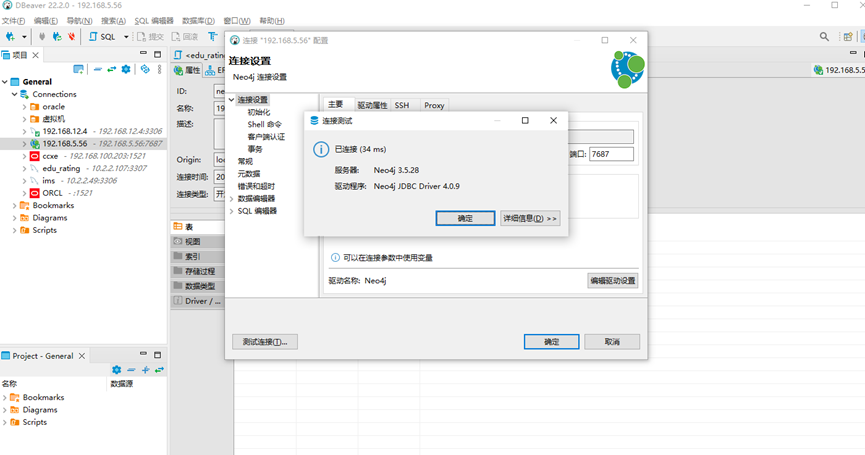
输入ip、用户名、密码
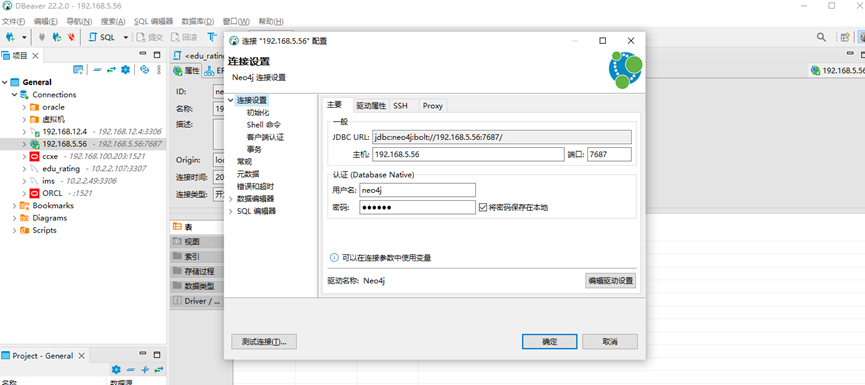
测试连接成功
4. neo4j图形数据库基本操作
首先我们打开Neo4j的浏览器控制台(http://xxx.xxx.xxx.xxx:7474/browser),用户名是neo4j,默认密码也是 neo4j,如果你已经了密码,那么,就输入你修改的密码即可。登陆进去我们会看到如下的界面的。
4.1 增加节点
Neo4j使用的是create 命令进行增加,就类似与MySQL中的insert。
创建一个学生节点(只有节点没有属性)
create (s:Student)
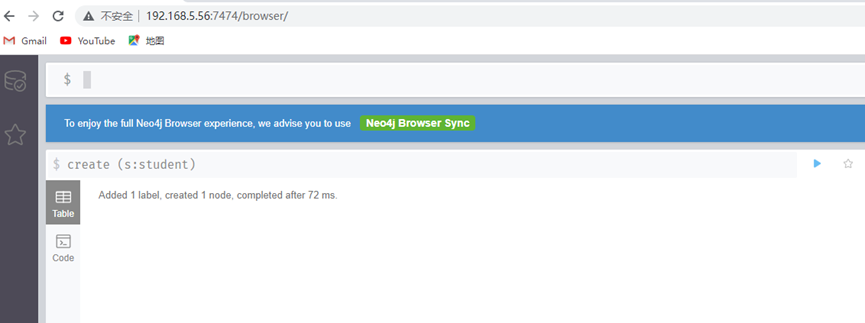
这说明我们已经创建完了学生节点
语法格式:
create (<node-name>:<label-name>)
• node-name:它是我们要创建的节点名称
• label-name:它是我们要创建的标签名称
创建一个学生节点(创建具有属性的节点)
创建一个id10000,名字张三,年龄为18岁,性别为男的学生节点
create (s:Student{id:10000, name:"张三",age:18,sex:1})
执行后,会看到如下的结果:
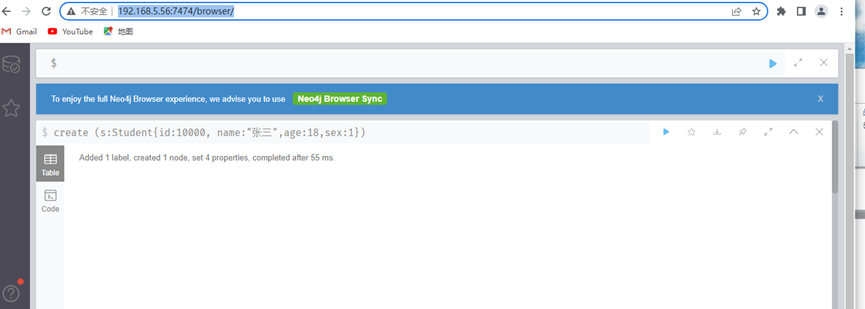
这说明我们创建了一个具有id,name,age,sex四个属性的节点。
不难理解,id、name、age、sex,就类似我们MySQL中 表中的字段一样。
创建带属性的节点语法如下:
create (<node-name>:<label-name> {
<property1-name>:<property1-Value>,
<property2-name>:<property2-Value>,
...,
<property3-name>:<property3-Value>
})
property1-name就是属性名称,property1-Value就是属性值。
4.2 查询
我们在上一步创建了没有属性的节点和有属性的节点,那么问题来了,我们怎么查看呢?查询咯~
Neo4j使用的是match … return … 命令进行查询,就类似与MySQL中的select。
我们查询刚刚创建的节点信息。
查询全部学生
match (s:Student) return s
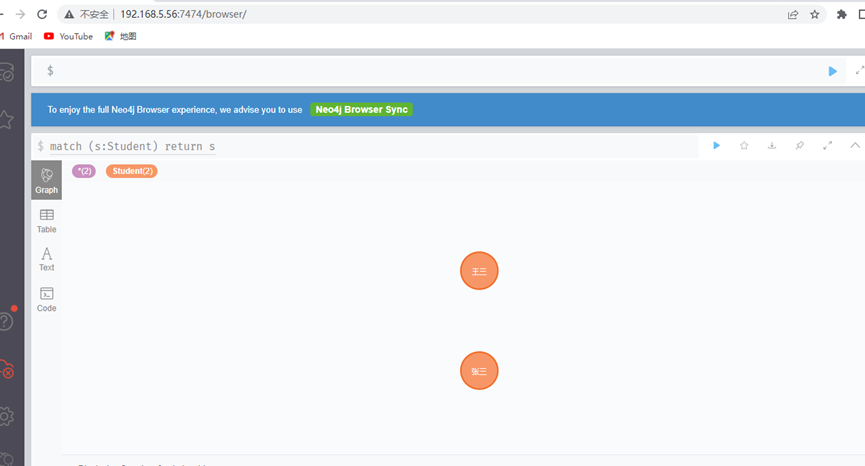
两个节点是以图的形式展示,我们也可以切换左边的Graph(图)、Table(表格)、Text(文本)等来以不同的形式展示。
查询全部或者部分字段
只需要把要展示的字段以节点名 + 点号 + 属性字段 拼接即可,如下:
match (s:Student) return s.id,s.name,s.age,s.sex
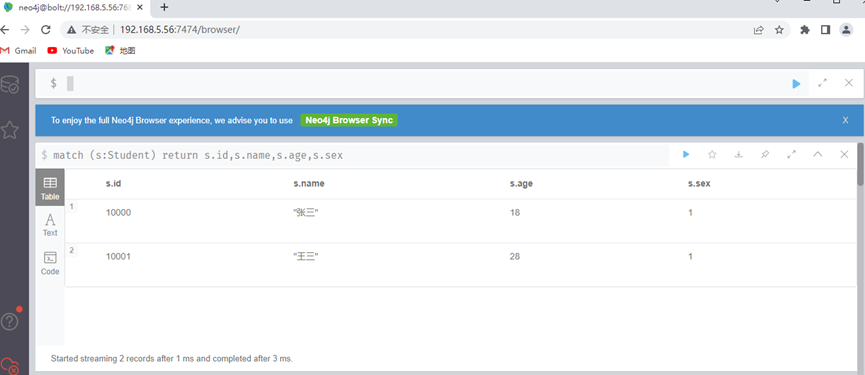
查询满足年龄age等于18的学生信息
match (s:Student) where s.age=18 return s.id,s.name,s.age,s.sex
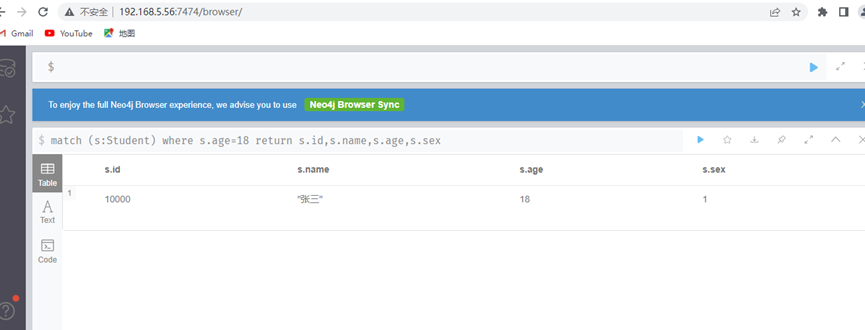
查询出所有的男生(sex=1)并按年龄倒叙排序
match (s:Student) where s.sex=1 return s.id,s.name,s.age,s.sex order by s.age desc
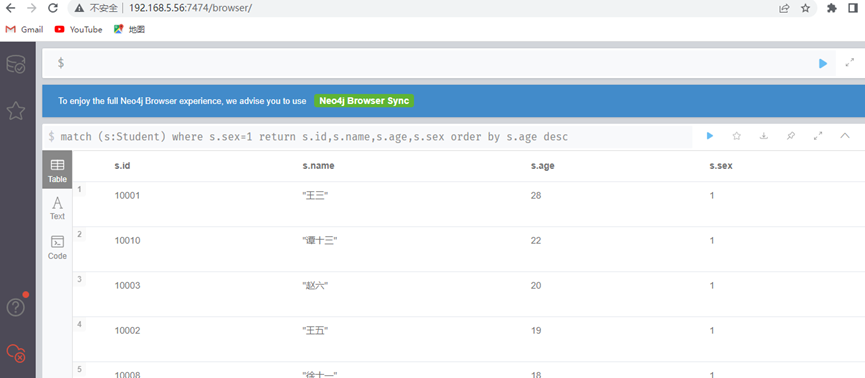
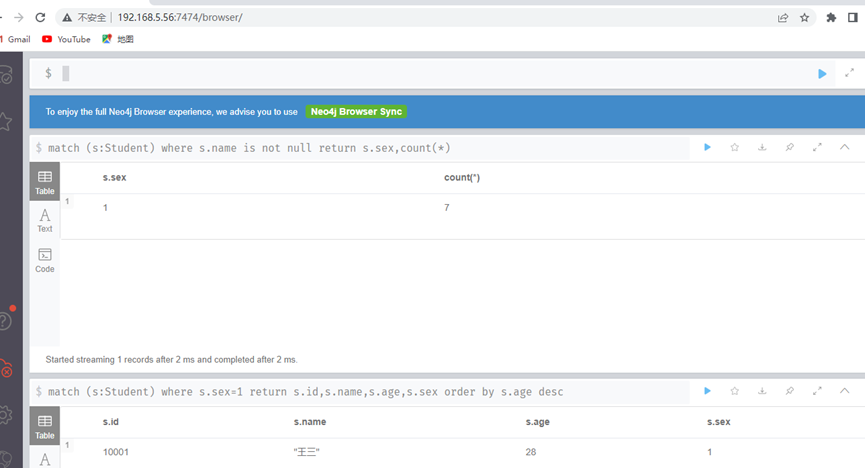
查询出名字不为null,且按性别分组
这里要注意一点,CQL中的分组和SQL是有所差异的,在CQL中不用显式的写group by分组字段,由解释器自动决定:即未加聚合函数的字段自动决定为分组字段。
match (s:Student) where s.name is not null return s.sex,count(*)
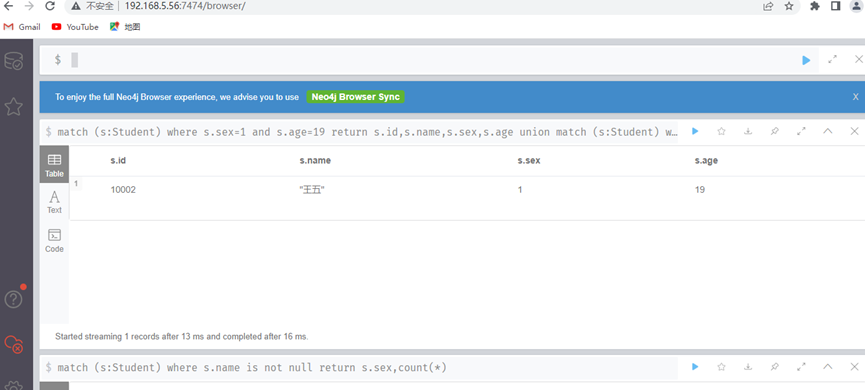
union联合查询(查询性别为男或者女的,且年龄为19岁的学生)
match (s:Student) where s.sex=1 and s.age=19 return s.id,s.name,s.sex,s.age
union
match (s:Student) where s.sex=0 and s.age=19 return s.id,s.name,s.sex,s.age
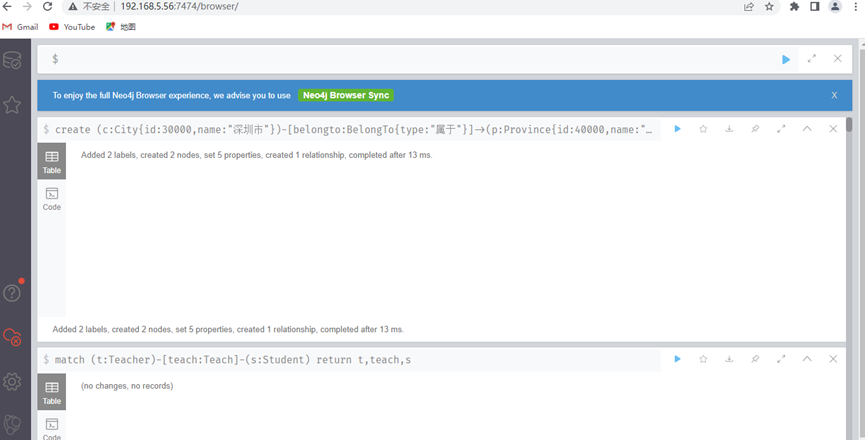
4.3 增加关系
东和深圳创建关系,深圳是属于广东省的。但是并没有广东省份节点和深圳市节点,没错,我们就是为两个不存在的节点创建关系。
create (c:City{id:30000,name:"深圳市"})-[belongto:BelongTo{type:"属于"}]->(p:Province{id:40000,name:"广东省"})
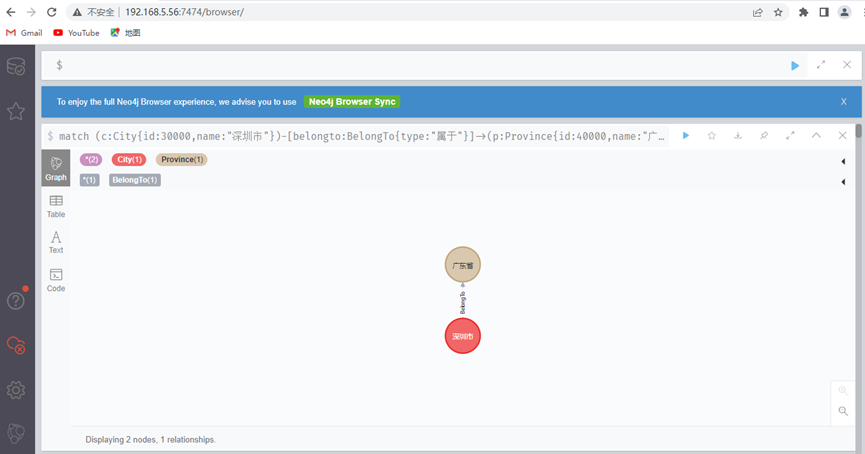
match (c:City{id:30000,name:"深圳市"})-[belongto:BelongTo{type:"属于"}]->(p:Province{id:40000,name:"广东省"}) return c,belongto,p
为两个不存在的节点创建关系的语法如下:
create (<node1-name>:<label1-name>
{<property1-name>:<property1-Value>,
<property1-name>:<property1-Value>})-
[(<relationship-name>:<relationship-label-name>{<property-name>:<property-Value>})]
->(<node2-name>:<label2-name>
{<property1-name>:<property1-Value>,
<property1-name>:<property1-Value>})
4.4 修改
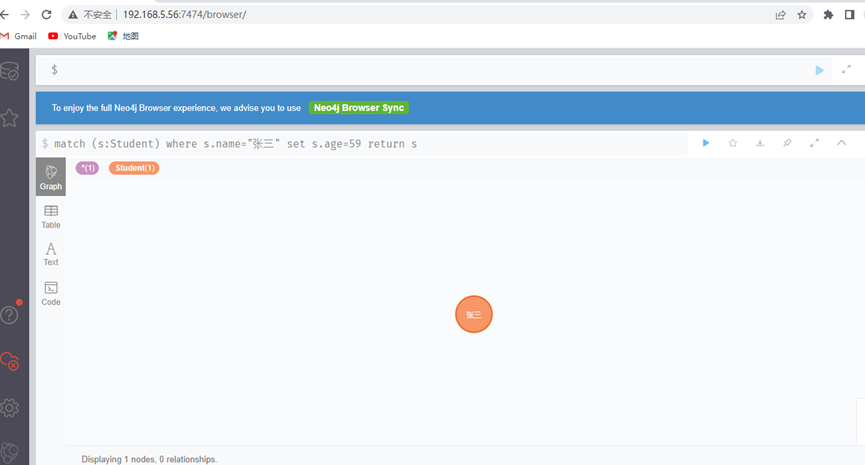
现在将张三的年龄从18岁修改到59岁
match (s:Student) where s.name="张三" set s.age=19 return s
4.5 删除
这里以删除学生节点中没有属性的来举例:
先查询下学生中没有属性的节点
match (s:Student) where s.name is null return s
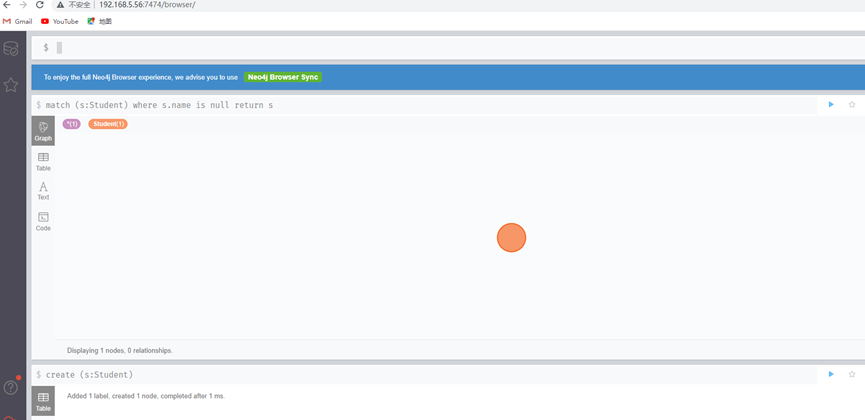
删除这个节点
match (s:Student) where s.name is null delete s
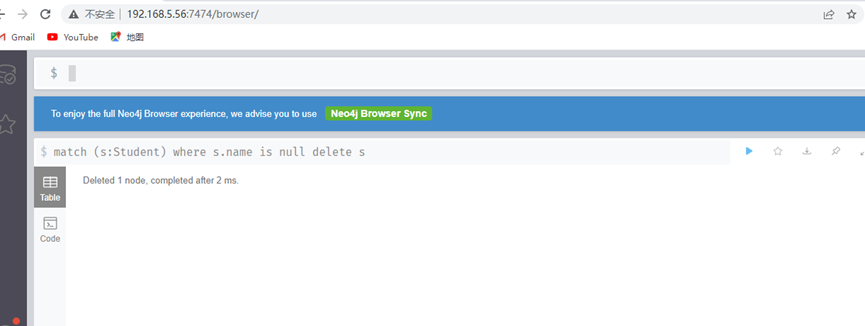
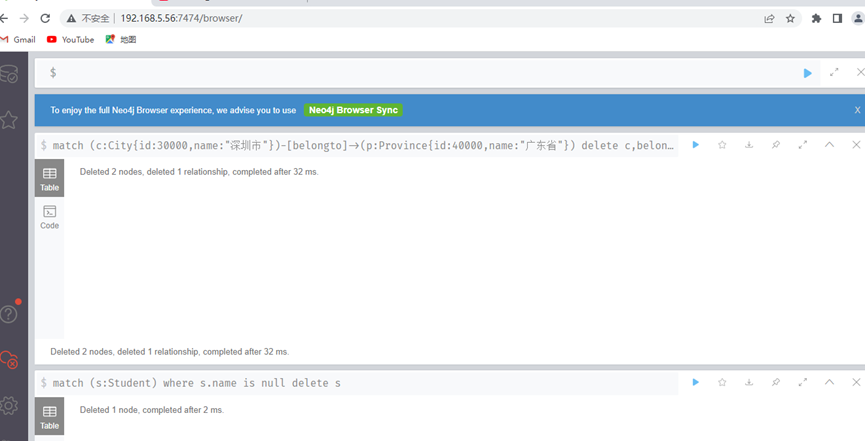
删除带关系的节点
match (c:City{id:30000,name:"深圳市"})-[belongto]->(p:Province{id:40000,name:"广东省"}) delete c,belongto,p






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结