您现在的位置是:首页 >其他 >privateGPT centos7环境下部署和研究网站首页其他
privateGPT centos7环境下部署和研究
参考:gihtub代码 https://github.com/imartinez/privateGPT
安装
llama-cpp-python-0.1.48安装报错
Could not build wheels for llama-cpp-python, , which is required to install pyproject.toml-based projects
搜索(结果较少):
从文章: 升级gcc解决编译llama-cpp-python错误发现是gcc/g++版本过低所致,但是博主环境是ubuntu.
搜索到文章 centos:安装gcc g++知道默认centos7 yum安装的是4.8.5
总结:
解决方案centos gcc/g++升级到11
参考:centos7 升级gcc到11.2.0
注意:编译安装耗时较久
执行
python ingest.py 报错version `GLIBCXX_3.4.29‘ not found的问题
OSError: xxxx/lib/libstdc++.so.6: version `GLIBCXX_3.4.29' not found (required by xxxx/python3.9/site-packages/llama_cpp/libllama.so)
如何解决version `GLIBCXX_3.4.29‘ not found的问题
默认路径下的libstdc++.so.6缺少GLIBCXX_3.4.29
发现是
版本低了
ll /xxx/lib/libstdc++.so.6

改为指向6.0.29
提取数据:
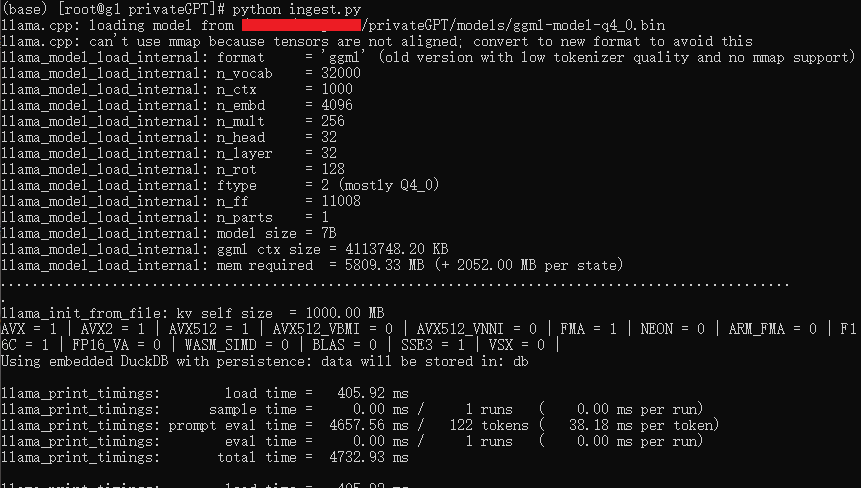
python ingest.py
python privateGPT.py执行查询
语法错误
File "/data1/Projects/privateGPT/privateGPT.py", line 26
match model_type:
^
SyntaxError: invalid syntax
是python3.10语法
参考:https://github.com/imartinez/privateGPT/issues/89
修改代码为:
if model_type == "LlamaCpp":
llm = LlamaCpp(model_path=model_path, n_ctx=model_n_ctx, callbacks=callbacks, verbose=False)
elif model_type == "GPT4All":
llm = GPT4All(model=model_path, n_ctx=model_n_ctx, backend='gptj', callbacks=callbacks, verbose=False)
else:
print(f"Model {model_type} not supported!")
exit;
query报错:
unknown token 忽视掉 https://github.com/imartinez/privateGPT/issues/77
输出乱码
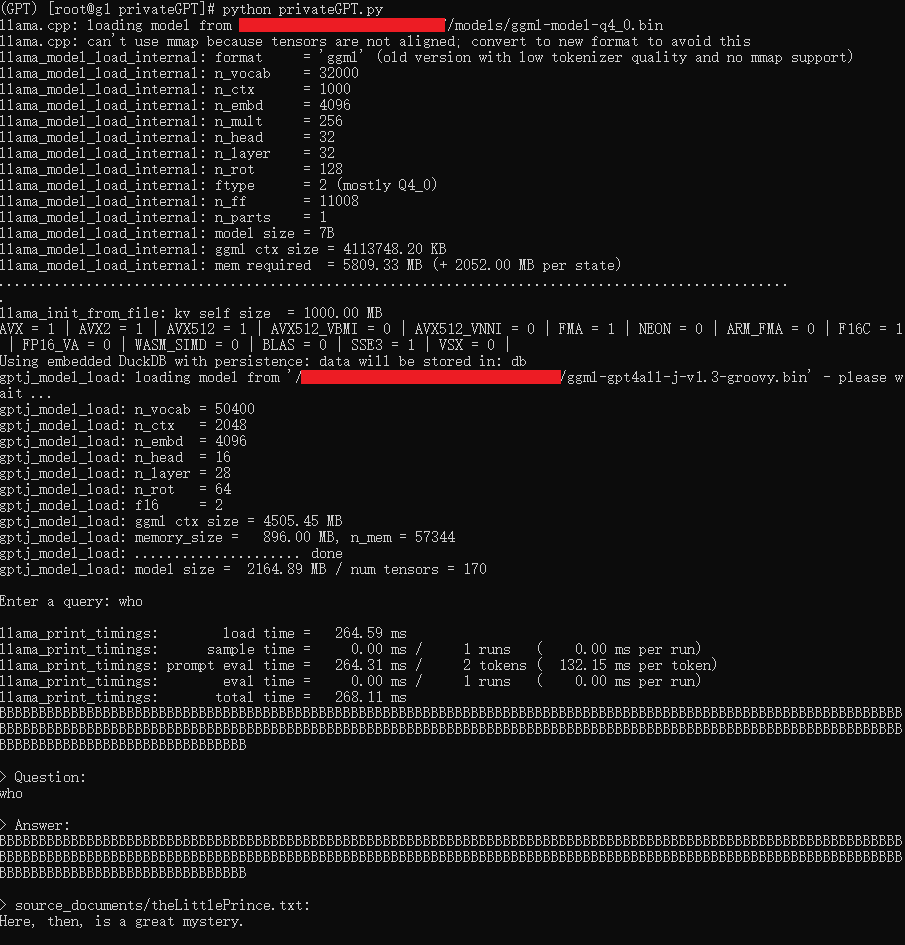
拉取最新代码后解决
总结
缺点:
1.模型比较局限,只能选择 GPT4All-J 类型的模型,性能高的开源模型暂时无法兼容 https://gpt4all.io/index.html
https://gpt4all.io/index.html
2.中文文档
embedding模型用中文向量,但是问答结果要还是英文,要么是没有意义的文字
shibing624/text2vec-base-chinese
参考:https://zhuanlan.zhihu.com/p/630223486

3.内存管理有问题,第xx个问题报错内存不足,待解决
ggml_new_tensor_impl: not enough space in the context’s memory pool (needed 8355506480, available 8342642000)
4.仅使用cpu
。。。待解决
完整代码
不持久化文档,完整代码:
import os
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.llms import GPT4All, LlamaCpp
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders import TextLoader
loader = TextLoader('./source_documents/xxx.txt',encoding='utf-8')
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import RetrievalQA
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import UnstructuredFileLoader
from langchain.chains.question_answering import load_qa_chain
model_path = 'xxx/ggml-gpt4all-j-v1.3-groovy.bin'
callbacks = [StreamingStdOutCallbackHandler()]
llm = GPT4All(model=model_path, backend='gptj', callbacks=callbacks, verbose=False)
chain = load_qa_chain(llm, chain_type="stuff")
chunk_size = 500
chunk_overlap = 50
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
documents = loader.load()
texts = text_splitter.split_documents(documents)
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2" )
db = Chroma.from_documents(texts, embeddings)
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever, return_source_documents=True)
query = "what is tame?"
res = qa(query)
answer, docs = res['result'], res['source_documents']






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结