您现在的位置是:首页 >其他 >大数据Doris(二十五):Doris数据Binlog Load导入方式介绍网站首页其他
大数据Doris(二十五):Doris数据Binlog Load导入方式介绍

文章目录
Doris数据Binlog Load导入方式介绍
Binlog Load提供了一种使Doris增量同步用户在Mysql数据库的对数据更新操作的CDC(Change Data Capture)功能。针对MySQL数据库中的INSERT、UPDATE、DELETE、过滤Query支持,暂不兼容DDL(Data Definition Language)语句。
一、基本原理
当前版本设计中,Binlog Load需要依赖canal作为中间媒介,让canal伪造成一个从节点去获取Mysql主节点上的Binlog并解析,再由Doris去获取Canal上解析好的数据,主要涉及Mysql端、Canal端以及Doris端,总体数据流向如下:
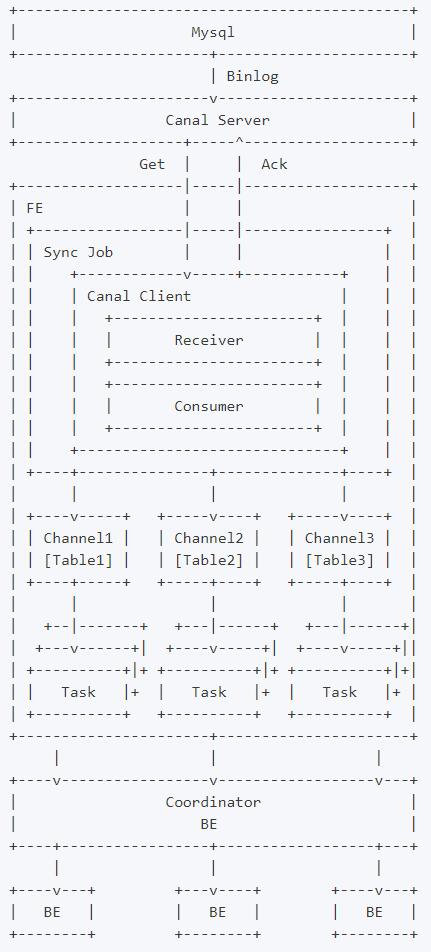
如上图,用户向FE提交一个数据同步作业,FE会为每个数据同步作业启动一个canal client,来向canal server端订阅并获取数据。
client中的receiver将负责通过Get命令接收数据,每获取到一个数据batch,都会由consumer根据对应表分发到不同的channel,每个channel都会为此数据batch产生一个发送数据的子任务Task。
在FE上,一个Task是channel向BE发送数据的子任务,里面包含分发到当前channel的同一个batch的数据。
channel控制着单个表事务的开始、提交、终止。一个事务周期内,一般会从consumer获取到多个batch的数据,因此会产生多个向BE发送数据的子任务Task,在提交事务成功前,这些Task不会实际生效。
满足一定条件时(比如超过一定时间、达到提交最大数据大小),consumer将会阻塞并通知各个channel提交事务。 当且仅当所有channel都提交成功,才会通过Ack命令通知canal并继续获取并消费数据 。如果有任意channel提交失败,将会重新从上一次消费成功的位置获取数据并再次提交( 已提交成功的channel不会再次提交以保证幂等性 )。
整个数据同步作业中,FE通过以上流程不断的从canal获取数据并提交到BE,来完成数据同步。
二、Canal原理及配置
Canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
当前的canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x。
Canal目前没有独立的官网,可以在GitHub上下载和查看Canal文档,地址如下:Home · alibaba/canal Wiki · GitHub
- Canal Server架构如下 :
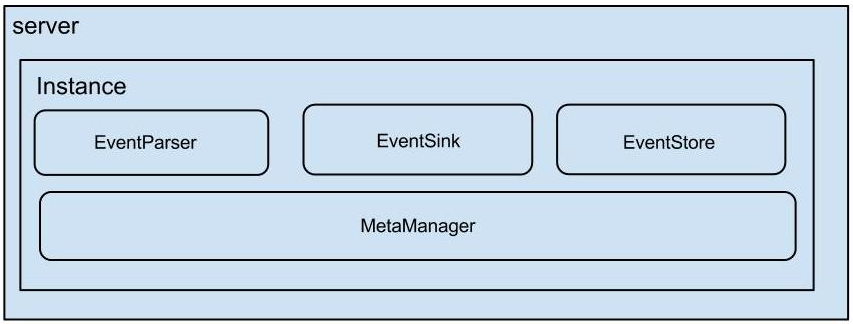
- server 代表一个 canal 运行实例,对应于一个 jvm。
- instance 对应于一个数据队列 (1个 canal server 对应 1..n 个 instance )
- instance 下的子模块
- eventParser: 数据源接入,模拟 slave 协议和 master 进行交互,协议解析
- eventSink: Parser 和 Store 链接器,进行数据过滤,加工,分发的工作
- eventStore: 数据存储
- metaManager: 增量订阅 & 消费信息管理器
1、Canal同步MySQL数据原理
Canal同步MySQL数据工作原理如下图所示:
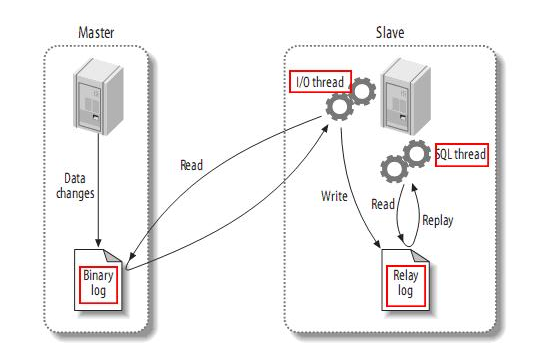
- MySQL主备复制原理
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- 注意:中继日志是从服务器I/O线程将主服务器的二进制日志读取过来,记录到从服务器本地文件,然后从服务器SQL线程会读取relay-log日志的内容并应用到从服务器,从而使从服务器和主服务器的数据保持一致。
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
- canal 工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
注意:mysql-binlog是MySQL数据库的二进制日志,记录了所有的DDL和DML(除了数据查询语句)语句信息。一般来说开启二进制日志大概会有1%的性能损耗。
2、开启MySQL binlog
对于自建MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,开启Mysql binlog日志步骤如下:
2.1、登录mysql查看MySQL是否开启binlog日志
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%';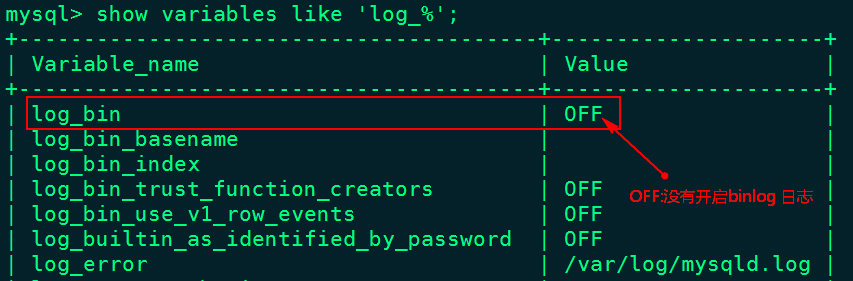
2.2、开启mysql binlog日志
在/etc/my.cnf文件中[mysqld]下写入以下内容:
[mysqld]
# 随机指定一个不能和其他集群中机器重名的字符串,配置 MySQL replaction 需要定#义,不要和 canal 的 slaveId 重复
server-id=123
#配置binlog日志目录,配置后会自动开启binlog日志,并写入该目录
log-bin=/var/lib/mysql/mysql-bin
# 选择 ROW 模式
binlog-format=ROW
MySQL binlog-format有三种模式:Row、Statement 和 Mixed 。
- Row:不记录sql语句上下文相关信息,仅保存哪条记录被修改。
优点: binlog中可以不记录执行的sql语句的上下文相关的信息,仅需要记录那一条记录被修改成什么了。所以row level的日志内容会非常清楚的记录下每一行数据修改的细节。
缺点:所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容,比如一条update语句,修改多条记录,则binlog中每一条修改都会有记录,这样造成binlog日志量会很大,特别是当执行alter table之类的语句的时候,由于表结构修改,每条记录都发生改变,那么该表每一条记录都会记录到日志中。
- Statement(默认):每一条会修改数据的sql都会记录在binlog中。
这种模式下,slave在复制的时候sql进程会解析成和原来master端执行过的相同的sql来再次执行。
优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。
缺点:由于只记录语句,所以,在statement level下 已经发现了有不少情况会造成MySQL的复制出现问题,主要是修改数据的时候使用了某些定的函数或者功能的时候会出现。 例如:update 语句中含有uuid() ,now() 这种函数时,Statement模式就会有问题(update t1 set xx = now() where xx = xx)
- Mixed: 混合模式
在Mixed模式下,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志格式,也就是在Statement和Row之间选择一种。如果sql语句确实就是update或者delete等修改数据的语句,那么还是会记录所有行的变更。
2.3、重启mysql 服务,重新查看binlog日志情况
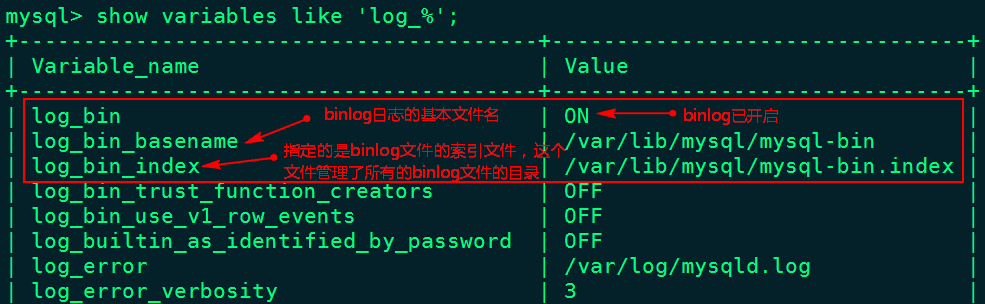
3、Canal配置及启动
这里所说的Canal安装与配置,首先需要在Canal中配置CanalServer 对应的canal.properties,这个文件中主要配置Canal对应的同步数据实例(Canal Instance)位置信息及数据导出的模式,例如:我们需要将某个mysql中的数据同步到Kafka中,那么就可以创建一个“数据同步实例”,导出到Kafka就是一种模式。其次,需要配置Canal Instance 实例中的instance.properties文件,指定同步到MySQL数据源及管道信息。
这里我们将MySQL数据同步到Doris中,只需要在canal.properties文件中配置Doris destination名称即可,Canal可以根据该destination名字找到对应的Canal instance实例的配置信息,对应的instance目录中,配置instance.properties 指定同步MySQL的源及数据管道相关信息。
Canal详细安装步骤及配置如下:
3.1、下载Canal
Doris使用Canal建议使用canal 1.1.5及以上版本,Cannal下载地址如下:Releases · alibaba/canal · GitHub
这里选择Canal 1.1.6版本下载
3.2、上传解压
将下载好的Canal安装包上传到node3节点上,解压
#首先创建目录 “/software/canal”
[root@node3 ~]# mkdir -p /software/canal
#将Canal安装包解压到创建的canal目录中
[root@node3 ~]# tar -zxvf /software/canal.deployer-1.1.6.tar.gz -C /software/canal/
3.3、关于配置canal.properties
Canal同步到消息队列时,需要配置CANAL_HOME/conf中canal.properties文件“canal.destinations”配置型,指定destinations 信息,多个destination使用逗号隔开,启动Canal后,Canal会根据配置的 destination名字在CANAL_HOME/conf/${destination}目录下找到对应的instance .properties实例配置,进一步找到同步的MySQL源信息,进行CDC数据同步。
如果是Doris同步Mysql数据,在Doris中启动Doris同步作业时需要指定对应的destination 名称,所以这里不必单独再配置$CANAL_HOME/conf中canal.properties文件指定destination名称。
3.4、配置Canal instance实例信息
#在$CANAL_HOME/conf中创建doris目录作为instance的根目录,该目录名需要与创建的Doris job 中指定的destination名称保持一致。
[root@node3 ~]# cd /software/canal/conf/
[root@node3 conf]# mkdir doris
#复制$CANAL_HOME/conf/example目录中的instance.properties到创建的doris目录中
[root@node3 conf]# cd /software/canal/conf/
[root@node3 conf]# cp ./example/* ./doris/
#配置instance.properties,只需要配置如下内容:
[root@node3 doris]# vim /software/canal/conf/doris/instance.properties
## canal instance serverId
canal.instance.mysql.slaveId = 1234
## mysql adress
canal.instance.master.address = node2:3306
## mysql username/password
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
3.5、配置doris instance 实例连接mysql的权限
Canal的原理是模拟自己为mysql slave,所以这里一定需要做为mysql slave的相关权限 ,授权Canal连接MySQL具有作为MySQL slave的权限:
mysql> CREATE USER canal IDENTIFIED BY 'canal';
mysql> GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
mysql> FLUSH PRIVILEGES;
mysql> show grants for 'canal' ;
3.6、启动Canal Server
进入$CANAL_HOME/canal/bin 目录中,执行”startup.sh”脚本启动Canal:
#启动Canal
[root@node3 ~]# cd /software/canal/bin/
[root@node3 bin]# ./startup.sh
#查看对应的Canal 进程
[root@node3 bin]# jps
...
18940 CanalLauncher
...
注意:如果启动canal后没有对应的进程,可以在CANALHOME/logs/{destination}/${destination}.log中查看对应的报错信息。
三、Doris同步MySQL数据案例
下面步骤演示使用Binlog Load 来同步MySQL表数据,需要的Canal已经配置完成,只需要经过MySQL中创建源表、Doris创建目标表、创建同步作业几个步骤即可完成数据同步。详细步骤如下:
1、MySQL中创建源表
在MySQL中创建表source_test作为Doris同步MySQL数据的源表,MySQL建表语句如下:
mysql> create database demo;
mysql> create table demo.source_test (id int(11),name varchar(255));
2、Doris中创建目标表
在Doris端创建好与Mysql端对应的目标表,Binlog Load只能支持Unique类型的目标表,且必须激活目标表的Batch Delete功能(建表默认开启), Doris目标表结构和MySQL源表结构字段顺序必须保持一致 :
#node1连接Doris
[root@node1 bin]# ./mysql -u root -P 9030 -h 127.0.0.1
#建库及目标表
mysql> create database mysql_db
mysql> create table mysql_db.target_test (
-> id int(11),
-> name varchar(255)
-> ) engine = olap
-> unique key (id)
-> distributed by hash(id) buckets 8;
3、创建同步作业
在Doris中 创建同步作业的语法格式如下:
CREATE SYNC [db.]job_name
(
channel_desc,
column_mapping
...
)
binlog_desc
- job_name
job_name是数据同步作业在当前数据库内的唯一标识,相同job_name的作业只能有一个在运行。
- channel_desc
channel_desc用来定义mysql源表到doris目标表的映射关系。在设置此项时,如果存在多个映射关系,必须满足mysql源表应该与doris目标表是一一对应关系,其他的任何映射关系(如一对多关系),检查语法时都被视为不合法。
- column_mapping
column_mapping主要指mysql源表和doris目标表的列之间的映射关系,如果指定,写的列是目标表中的列,即:源表这些列导入到目标表对应哪些列;如果不指定,FE会默认源表和目标表的列按顺序一一对应。但是我们依然建议显式的指定列的映射关系,这样当目标表的结构发生变化(比如增加一个 nullable 的列),数据同步作业依然可以进行。否则,当发生上述变动后,因为列映射关系不再一一对应,导入将报错。
- binlog_desc
binlog_desc中的属性定义了对接远端Binlog地址的一些必要信息,目前可支持的对接类型只有canal方式,所有的配置项前都需要加上canal前缀。有如下配置项:
canal.server.ip: canal server的地址。
canal.server.port: canal server的端口,默认是11111。
canal.destination: 前文提到的instance的字符串标识。
canal.batchSize: 每批从canal server处获取的batch大小的最大值,默认8192。
canal.username: instance的用户名。
canal.password: instance的密码。
canal.debug: 设置为true时,会将batch和每一行数据的详细信息都打印出来,会影响性能。
在Doris中创建同步作业,命令如下:
CREATE SYNC mysql_db.job
(
FROM demo.source_test INTO target_test
(id,name)
)
FROM BINLOG
(
"type" = "canal",
"canal.server.ip" = "node3",
"canal.server.port" = "11111",
"canal.destination" = "doris",
"canal.username" = "canal",
"canal.password" = "canal"
);
注意:target_test 不能指定对应的库名,默认该目标表就是当前所在的库。
以上执行完成之后,可以通过执行如下命令,查看执行的job任务:
#查看执行的job任务 ,可以查看到对应提交的job 状态为运行。
mysql> show sync job;
...
23067 | job | CANAL | RUNNING ...
...
向MySQL源表中插入如下数据,同时在Doris中查询对应的目标表,可以看到MySQL中的数据被监控到Doris目标表中。
#node2节点中,向MySQL源表demo.source_test表 中插入如下数据
mysql> insert into source_test values (1,"zs"),(2,"ls"),(3,"ww");
#node1节点通过Mysql客户端查看同步结果,可以看到数据同步成功。
mysql> select * from target_test;
+------+------+
| id | name |
+------+------+
| 3 | ww |
| 2 | ls |
| 1 | zs |
+------+------+
#node2节点中,对MySQL源表删除数据
mysql> delete from source_test where id =1;
#node1节点通过Mysql客户端查看同步结果,可以看到数据同步成功。
mysql> select * from target_test;
+------+------+
| id | name |
+------+------+
| 2 | ls |
| 3 | ww |
+------+------+
如果想要暂停、停止、重新执行同步任务的job,可以执行如下命令:
#暂停同步任务,jobname为提交的job名称
PAUSE SYNC JOB jobname;
#停止同步任务,jobname为提交的job名称
STOP SYNC JOB jobname;
#重新执行同步任务,jobname为提交的job名称
RESUME SYNC JOB jobname;
四、注意事项
1、关于配置
下面配置属于数据同步作业的系统级别配置,主要通过修改 fe.conf 来调整配置值。
- sync_commit_interval_second
默认10s,提交事务的最大时间间隔。若超过了这个时间channel中还有数据没有提交,consumer会通知channel提交事务。
- min_sync_commit_size
提交事务需满足的最小event数量。若Fe接收到的event数量小于它,会继续等待下一批数据直到时间超过了 sync_commit_interval_second 为止。默认值是10000个events,如果你想修改此配置,请确保此值小于canal端的 canal.instance.memory.buffer.size配置(默认16384),否则在ack前Fe会尝试获取比store队列长度更多的event,导致store队列阻塞至超时为止。
- min_bytes_sync_commit
提交事务需满足的最小数据大小。若Fe接收到的数据大小小于它,会继续等待下一批数据直到时间超过了sync_commit_interval_second为止。默认值是15MB,如果你想修改此配置,请确保此值小于canal端的canal.instance.memory.buffer.size和canal.instance.memory.buffer.memunit的乘积(默认16MB),否则在ack前Fe会尝试获取比store空间更大的数据,导致store队列阻塞至超时为止。
- max_bytes_sync_commit
提交事务时的数据大小的最大值。若Fe接收到的数据大小大于它,会立即提交事务并发送已积累的数据。默认值是64MB,如果你想修改此配置,请确保此值大于canal端的canal.instance.memory.buffer.size和canal.instance.memory.buffer.memunit的乘积(默认16MB)和min_bytes_sync_commit。
- max_sync_task_threads_num
默认10个,数据同步作业线程池中的最大线程数量。此线程池整个FE中只有一个,用于处理FE中所有数据同步作业向BE发送数据的任务task,线程池的实现在SyncTaskPool类。
2、关于注意点
- 数据同步作业并不能禁止alter table的操作,当表结构发生了变化,如果列的映射无法匹配,可能导致作业发生错误暂停,建议通过在数据同步作业中显式指定列映射关系,或者通过增加 Nullable 列或带 Default 值的列来减少这类问题。
- 删除doris 目标表后,数据同步作业会被EF的定时调度停止。
- doris中多个数据同步作业不能配置相同的ip:port+destination,主要为了防止出现多个作业连接到同一个instance的情况。
- Doris本身浮点类型的精度与Mysql不一样,所以数据同步时浮点类型的数据精度在Mysql端和Doris端不一样,可以选择用Decimal类型代替。
- ?博客主页:https://lansonli.blog.csdn.net
- ?欢迎点赞 ? 收藏 ⭐留言 ? 如有错误敬请指正!
- ?本文由 Lansonli 原创,首发于 CSDN博客?
- ?停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结