您现在的位置是:首页 >其他 >深度学习 - 50.推荐场景下的 Attention And Multi-Head Attention网站首页其他
深度学习 - 50.推荐场景下的 Attention And Multi-Head Attention
目录
一.引言

Attention 注意力机制最早来源于我们自身的视觉感官,当我们视觉获取到图像信息时,我们并不是从前往后从上往下均匀的扫描画面,而是会更偏重观测某一个位置,上面的热力图给出了我们观察建筑物时,视觉更关注,即 Attention 更多的地方。同样,在推荐场景下,图像信息就类比为我们对应的 Item,而我们感官的 Attention 侧重则根据用户历史行为序列决定。
二.Attention
1.Common Attention
注意力 Attention 函数可以描述为将 Query 和一组键值对 Key-Value 映射到 Output,其中 Query、Key、Value 和 Output 都是向量。输出计算为值的加权和,其中分配给每个值的权重由 Query 与相应 Key 的兼容性函数计算。
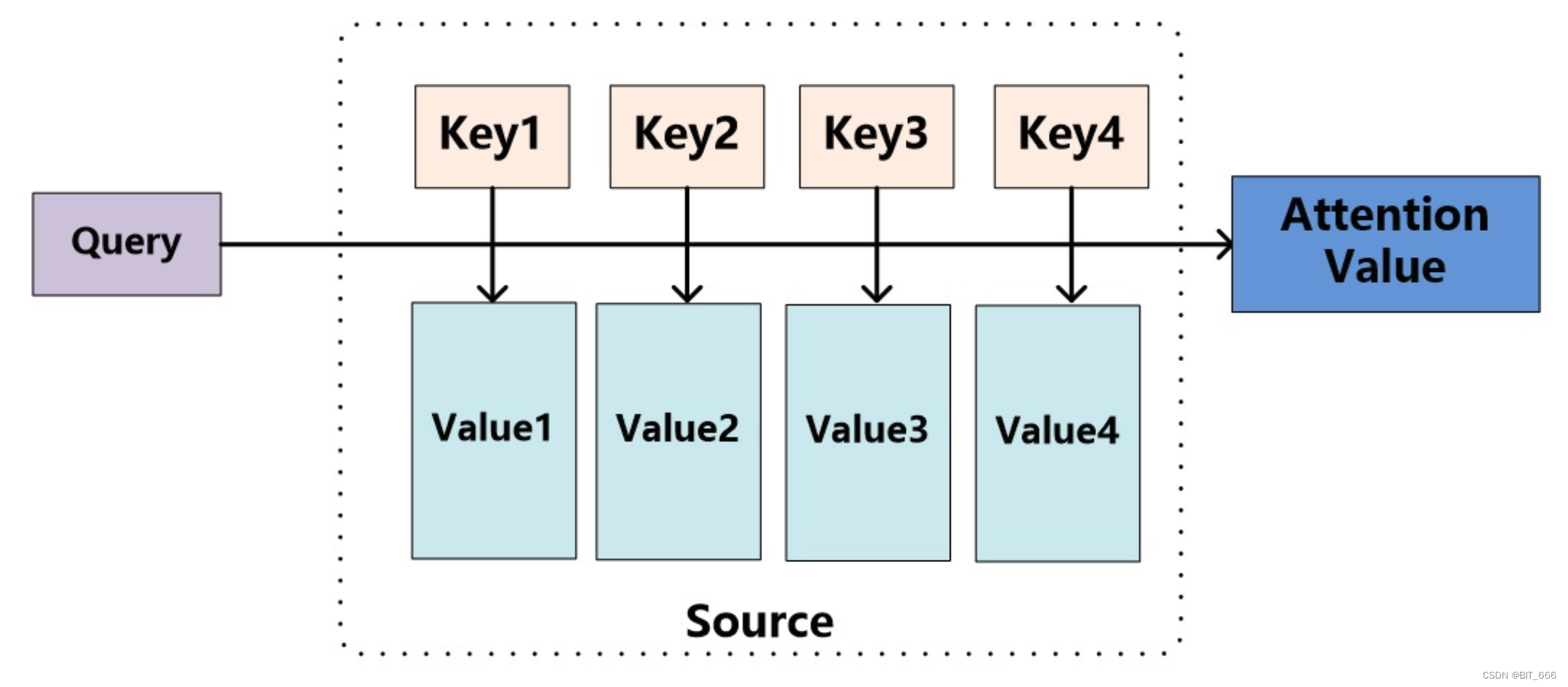
keys 负责与 query 计算权重,得到权重后与 values 进行加权求和得到 output,在一些开源代码中,我们经常看到 Attention 代码中有 Q、K、V 类似标识,其中:
Q - Query 在推荐场景下为目标 Item
K - Keys 在推荐场景下为用户行为 Goods
V - Values 在推荐场景下 V 与 K 相同,均为用户行为 Goods
推荐实战场景下,Query 与 Key 的权重计算一般采用 Dot-Product 的方式,对于 N 个 Key 将得到 N 个权重,根据场景不同,也可以决定是否对权重采用 Softmax 归一化,再进行加权求和。
2.Google Attention
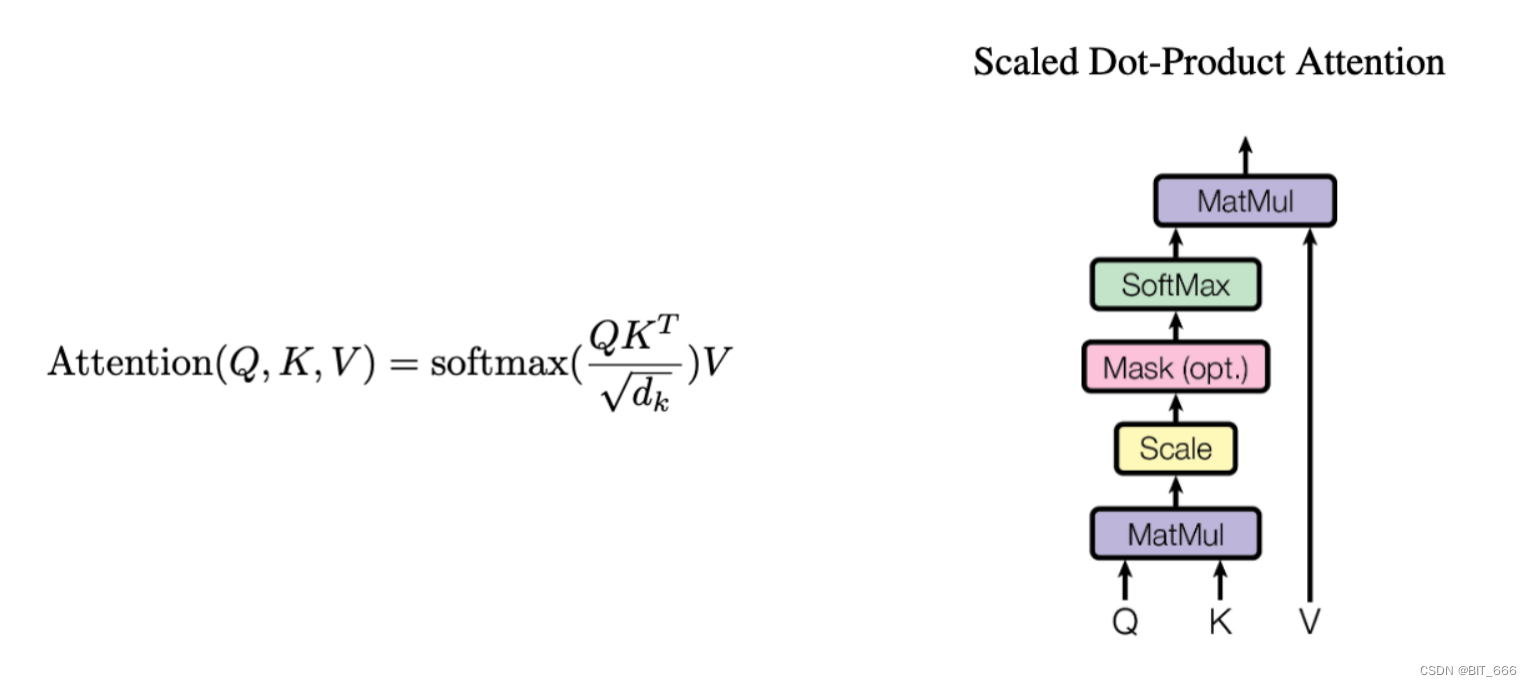
Google《Attention Is All You Need》一文中在原始计算公式的基础上增加了比例因子 1/√dk。最常用的 Attention 函数是 Add Attention 和 Dot-Product Attention。理论上二者复杂度相似,但是 Dot-Product Attention 可以通过矩阵优化代码提高效率。除此之外,由于 Dot-Product Attention 有时幅度较大容易将 softmax 函数推入梯度极小的区域,为了抵消这种影响,谷歌将点积做了缩放,缩放因子为 √dk。
三.Multi-Head Attention
Multi-Head Attention 最早应用于 NLP 任务中,其代替 RNN 实现了 Seq2Seq 的模型框架。
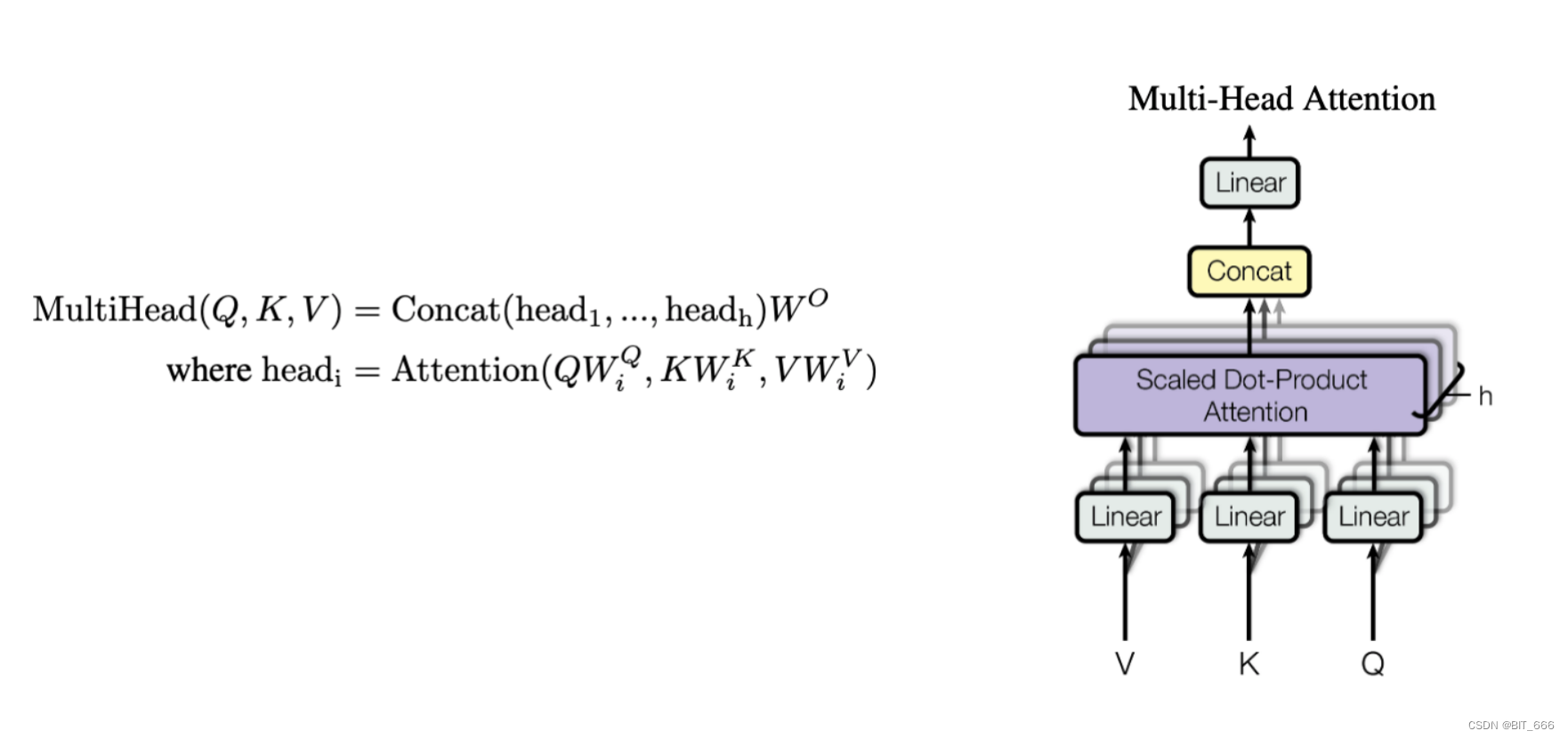
Q - Query 在推荐场景下为目标 Item,批量计算时维度为 None x 1 x Dim
K - Keys 在推荐场景下为用户行为 Goods,批量计算时维度为 None x T_k x Dim
V - Values 在推荐场景下 V 与 K 相同,均为用户行为 Goods
Multi-Head 可以理解为 Q、K、V 分解为 Head 个子空间,对每个子空间内的向量进行 Attention 操作,例如一个 Query 的维度为 None x 128,如果采用 Head = 4 的场景,则 Query 被分为 4 个 None x 32 的向量,同理 K、V 对应的向量也被分解。随后每个 None x 32 进行 Attention 操作,最后再 Concat 合并。
Tips:
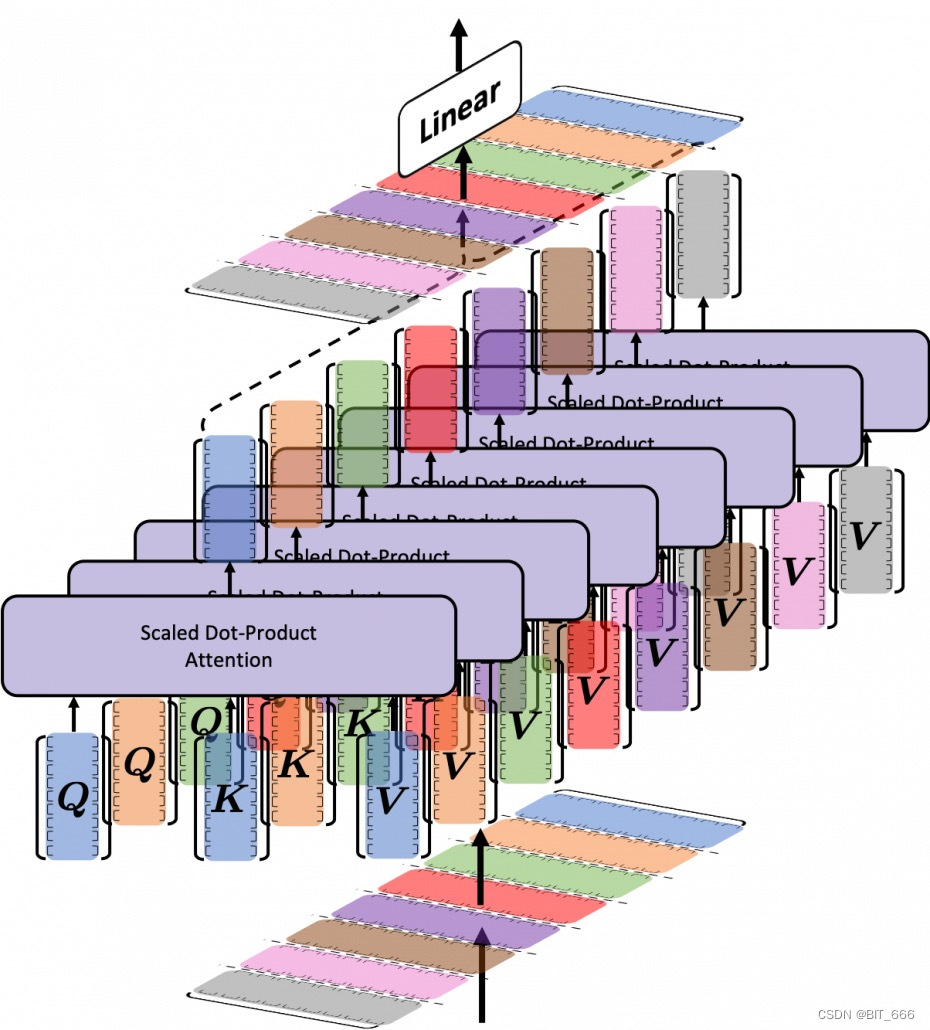
NLP 场景下 Query 为语句序列,维度为 None x T_q x Dim,由于推荐场景下 Query 候选集为单一商品,所以维度为 None x 1 x Dim。Multi-Head Attention 可以理解为在向量的不同子空间内进行 Attention,以表征不同的含义。除此之外,Multi-Head Attention 还分别增加了前后两个 linear 模块,与传统 Attention 直接 lookup 获取向量内积有所不同。上图可以看作是 Multi-Head 的立体示意图。
四.总结
上面简单介绍了 Attention 与 Multi-Attention 机制,目前 Attention 机制已经广泛应用于推荐与自然语言处理任务中,除了上面最基础的 id 对应 embedding 信息外,很多场景下通过增加 id SideInfo 侧信息以及序列行为相对位置与绝对位置信息的 Position_embeeding 优化 Attention 的效果。后续会使用 kears 实现简单的 Attention 与 Multi-Head Attention 机制,欢迎批评指正~
参考:
更多推荐算法相关深度学习:深度学习导读专栏






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结