您现在的位置是:首页 >学无止境 >3、Druid的load data 示例(实时kafka数据和离线-本地或hdfs数据)网站首页学无止境
3、Druid的load data 示例(实时kafka数据和离线-本地或hdfs数据)
Apache Druid 系列文章
1、Druid(Imply-3.0.4)介绍及部署(centos6.10)、验证
2、Druid的入门示例(使用三种不同的方式摄入数据和提交任务)
3、Druid的load data 示例(实时kafka数据和离线-本地或hdfs数据)
4、java操作druid api
5、Druid配置文件详细介绍以及示例
6、Druid的Roll up详细介绍及示例
本文介绍了Druid摄取离线与实时数据的过程,离线数据包括本地文件和hdfs数据,实时数据以kafka为示例进行说明。
本文依赖hadoop环境、kafka环境以及druid环境可正常使用。
本文分为2个部分,即离线数据和实时数据的摄取。
一、批量(离线)数据摄取
批量数据可以通过两种方式来摄入,即摄入本地文件和hdfs文件。
1、摄取本地文件
具体示例参考2、Druid的入门示例(使用三种不同的方式摄入数据和提交任务)
2、摄取HDFS文件
前提:hdfs、yarn集群运行正常,测试环境hadop集群是高可用环境
1)、将需要测试的数据上传至hadoop集群中
[alanchan@server1 ~]$ hadoop fs -ls hdfs://HadoopHAcluster/druid
Found 1 items
-rw-r--r-- 3 alanchan supergroup 2582 2022-12-29 09:51 hdfs://HadoopHAcluster/druid/test.json
# 文件位置
hdfs://HadoopHAcluster/druid/test.json
2)、编写 index_test.json 文件中配置
# index_test.json
{
"type": "index_hadoop",
"spec": {
"dataSchema": {
"dataSource": "test",
"parser": {
"type": "hadoopyString",
"parseSpec": {
"format": "json",
"dimensionsSpec": {
"dimensions": [
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user"
]
},
"timestampSpec": {
"format": "auto",
"column": "time"
}
}
},
"metricsSpec": [
{
"name": "count",
"type": "count"
},
{
"name": "added",
"type": "longSum",
"fieldName": "added"
},
{
"name": "deleted",
"type": "longSum",
"fieldName": "deleted"
},
{
"name": "delta",
"type": "longSum",
"fieldName": "delta"
}
],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "day",
"queryGranularity": "none",
"intervals": [
"2022-09-12/2022-09-13"
],
"rollup": false
}
},
"ioConfig": {
"type": "hadoop",
"inputSpec": {
"type": "static",
"paths": "/druid/test.json"
}
},
"tuningConfig": {
"type": "hadoop",
"partitionsSpec": {
"type": "hashed",
"targetPartitionSize": 5000000
},
"jobProperties": {
"fs.default.name": "hdfs://HadoopHAcluster/",
"fs.defaultFS": "hdfs://HadoopHAcluster/",
"dfs.client.use.datanode.hostname": "true",
"dfs.datanode.use.datanode.hostname": "true",
"yarn.nodemanager.vmem-check-enabled": "false",
"mapreduce.map.java.opts": "-Duser.timezone=UTC -Dfile.encoding=UTF-8",
"mapreduce.job.user.classpath.first": "true",
"mapreduce.reduce.java.opts": "-Duser.timezone=UTC -Dfile.encoding=UTF-8",
"mapreduce.map.memory.mb": 1024,
"mapreduce.reduce.memory.mb": 1024
}
}
},
"hadoopDependencyCoordinates": [
"org.apache.hadoop:hadoop-client:2.8.3"
]
}
# hadoopDependencyCoordinates是可选配置。
#A JSON array of Hadoop dependency coordinates that Druid will use, this property will override the default Hadoop coordinates.
#Once specified, Druid will look for those Hadoop dependencies from the location specified by druid.extensions.hadoopDependenciesDir
# 可以在druid的安装目录下查找其对应的版本,运行出错后,其日志中也有体现找不到对应的客户端
# /usr/local/bigdata/imply-3.0.4/dist/druid/hadoop-dependencies/hadoop-client
3)、可以使用 postman 提交索引任务,也可以直接在druid中提交
提交后,yarn的任務界面可以看到提交的MR任務。
4)、到 Druid控制台中执行SQL查询
SELECT *
FROM "test"
LIMIT 1
二、流式(实时)kafka数据摄取
1、需求
实时摄取Kafka中 metrics topic的数据到 Druid中
2、操作步骤
1)、启动 Kafka 集群
2)、在Kafka集群上创建一个名为metrics的topic
cd /usr/local/bigdata/kafka_2.12-3.0.0/bin
kafka-topics.sh --create --zookeeper server1:2118,server2:2118,server3:2118 --topic metrics --partitions 1 --replication-factor 1
kafka-topics.sh --create --bootstrap-server server1:9092 --topic metrics --partitions 1 --replication-factor 1
[alanchan@server1 bin]$ kafka-topics.sh --create --bootstrap-server server1:9092 --topic metrics --partitions 1 --replication-factor 1
Created topic metrics.
3)、定义摄取配置文件
index-metrics-kafka.json 文件中
{
"type": "kafka",
"dataSchema": {
"dataSource": "metrics-kafka",
"parser": {
"type": "string",
"parseSpec": {
"timestampSpec": {
"column": "time",
"format": "auto"
},
"dimensionsSpec": {
"dimensions": ["url", "user"]
},
"format": "json"
}
},
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "HOUR",
"queryGranularity": "NONE"
},
"metricsSpec": [
{
"type": "count",
"name": "views"
},
{
"name": "latencyMs",
"type": "doubleSum",
"fieldName": "latencyMs"
}
]
},
"ioConfig": {
"topic": "metrics",
"consumerProperties": {
"bootstrap.servers": "server1:9092,server2:9092,server3:9092",
"group.id": "kafka-indexing-service"
},
"taskCount": 1,
"replicas": 1,
"taskDuration": "PT1H"
},
"tuningConfig": {
"type": "kafka",
"maxRowsInMemory": "100000",
"workerThreads": 2
}
}
1)、提交任务
打开postman提交索引任务或者在http://server3:8888/unified-console.html#load-data提交任务
将 index-metrics-kafka.json 文件中的内容拷贝到 postman 中
发送post请求到http://server1:8090/druid/indexer/v1/supervisor
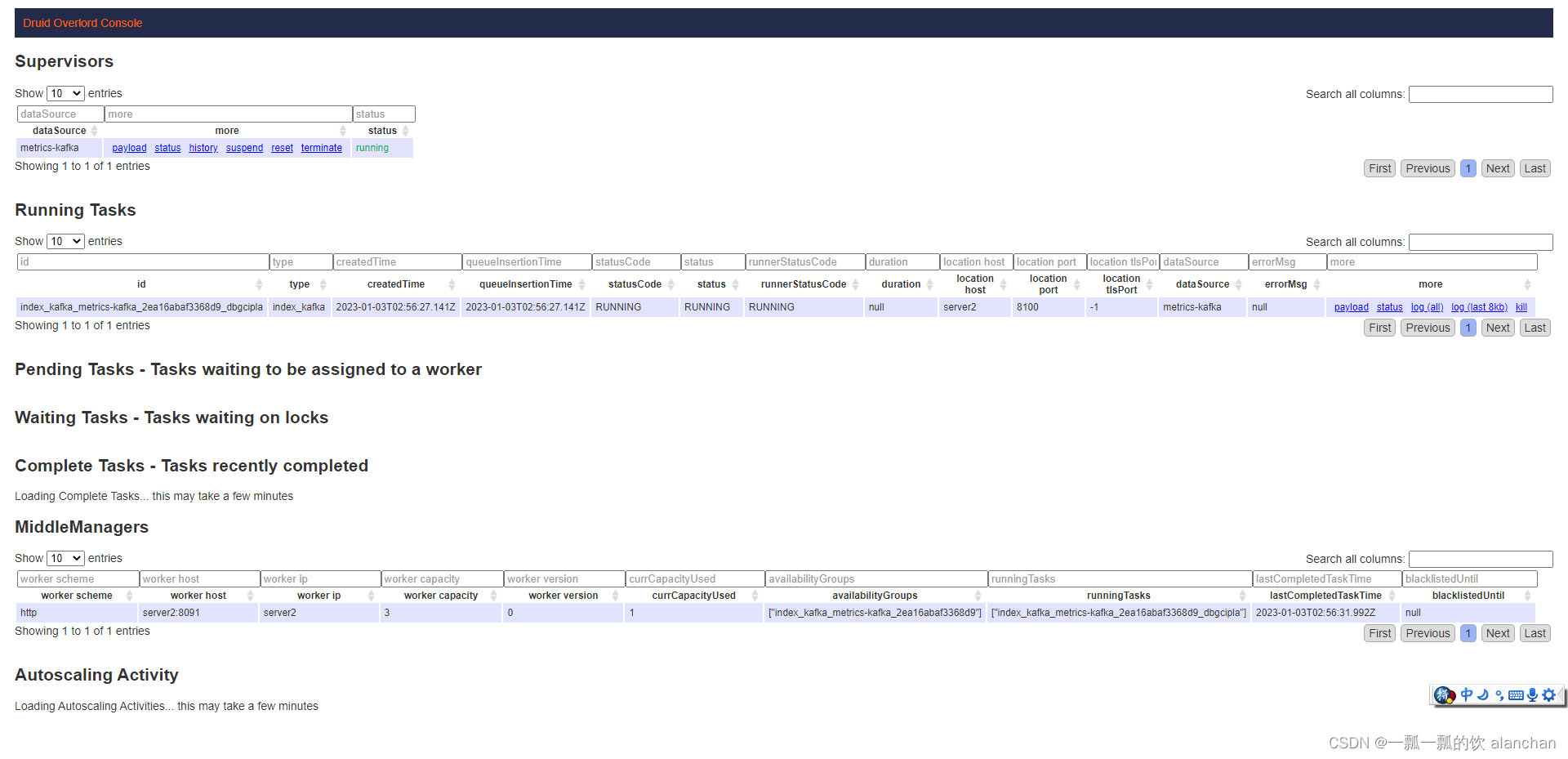
4)、在Kafka集群上开启一个控制台producer
cd /usr/local/bigdata/kafka_2.12-3.0.0/bin
kafka-console-producer.sh --broker-list server1:9092,server2:9092,server3:9092 --topic metrics
[alanchan@server3 bin]$ kafka-console-producer.sh --broker-list server1:9092,server2:9092,server3:9092 --topic metrics
>
5)、在Kafka producer控制台中粘贴如下数据
{"time":"2019-07-23T17:57:58Z","url":"/foo/bar","user":"alice","latencyMs":32}
{"time":"2019-07-23T17:57:59Z","url":"/","user":"bob","latencyMs":11}
{"time":"2019-07-23T17:58:00Z","url": "/foo/bar","user":"bob","latencyMs":45}
/usr/local/bigdata/kafka_2.12-3.0.0/bin
[alanchan@server3 bin]$ kafka-console-producer.sh --broker-list server1:9092,server2:9092,server3:9092 --topic metrics
>{"time":"2019-07-23T17:57:58Z","url":"/foo/bar","user":"alice","latencyMs":32}
>{"time":"2019-07-23T17:57:59Z","url":"/","user":"bob","latencyMs":11}
>{"time":"2019-07-23T17:58:00Z","url": "/foo/bar","user":"bob","latencyMs":45}
3、验证数据
在 Druid Console中执行以下SQL查询
SELECT *
from "metrics-kafka"
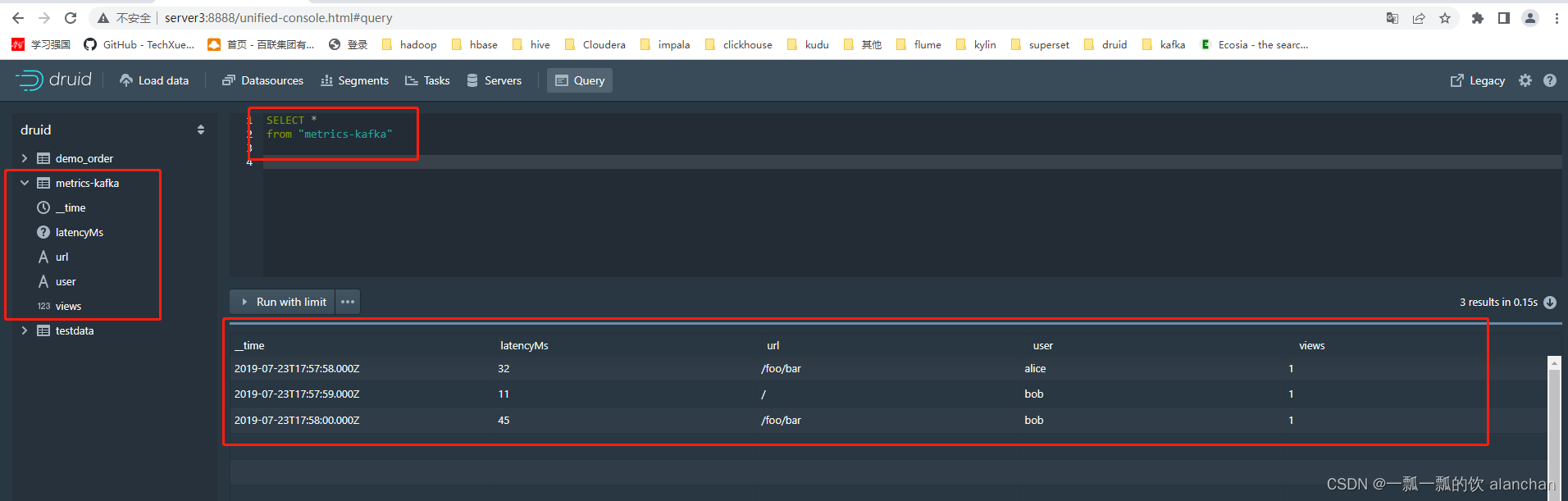
以上,简单的描述了Druid摄取离线和实时kafka数据过程及验证。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结