您现在的位置是:首页 >其他 >【腾讯云FinOps Crane 集训营】让我看看还有谁没用过crane这个降本利器网站首页其他
【腾讯云FinOps Crane 集训营】让我看看还有谁没用过crane这个降本利器
近几年云原生概念的发展如雨后春笋,势如破竹,而devops和k8s(Kubernetes)两兄弟也搭上云原生的车先后火了起来
devops:如字面意思Development&Operations,它的理念是开发即运维,目的是消除开发者们与运维之间的隔阂,从而提高效率;
k8s:即Kubernetes,docker容器编排工具;
虽然有了devops和k8s我们已经能很好的完成应用集群管理,但管理者们不满足于此,他们着手开始向成本管理方向研究,于是有了今天的主角:crane
为什么会取名叫crane?
crane翻译过来是起重机
回想一下现实生活中修房子,没有起重机我们也能修高楼大厦,但会耗费更多人力物力
同样的道理,没有crane我们也能完成应用编排,但是会浪费很多时间,时间即金钱,金钱即成本,所以,称之为降本利器毫不为过
关于Crane

Crane 是 FinOps 基金会认证的云优化方案,是一个基于 FinOps 的云资源分析与成本优化平台,它的愿景是在保证客户应用运行质量的前提下实现极致的降本。
哦对了,重点是crane目前已经开源,GitHub传送门
先来看看crane的架构
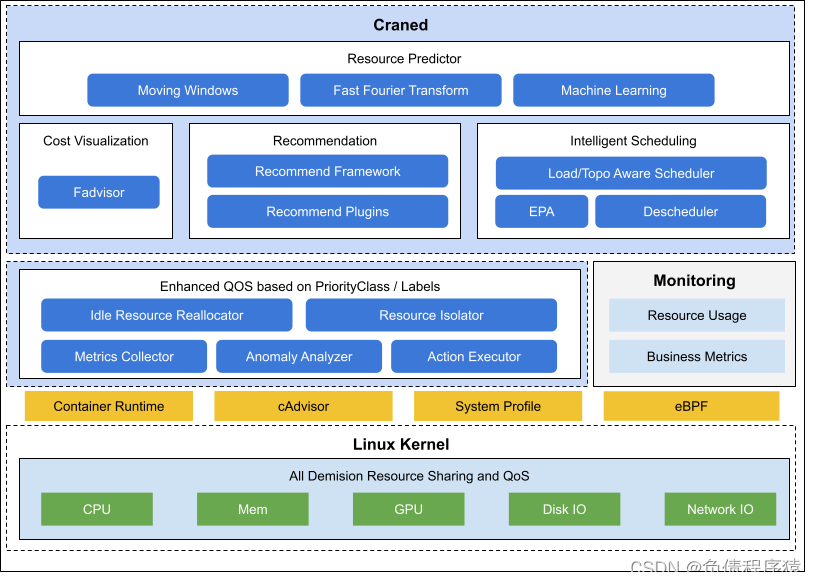
- Craned
Craned 是 Crane 的最核心组件,它管理了 CRDs 的生命周期以及API。Craned 通过 Deployment 方式部署且由两个容器组成:
Craned: 运行了 Operators 用来管理 CRDs,向 Dashboard 提供了 WebApi,Predictors 提供了 TimeSeries API
Dashboard: 基于 TDesign’s Starter 脚手架研发的前端项目,提供了易于上手的产品功能 - Fadvisor
Fadvisor 提供一组 Exporter 计算集群云资源的计费和账单数据并存储到你的监控系统,比如 Prometheus。Fadvisor 通过 Cloud Provider 支持了多云计费的 API。 - Metric Adapter
Metric Adapter 实现了一个 Custom Metric Apiserver. Metric Adapter 读取 CRDs 信息并提供基于 Custom/External Metric API 的 HPA Metric 的数据。 - Crane Agent
Crane Agent 通过 DaemonSet 部署在集群的节点上。
再来看看crane核心功能
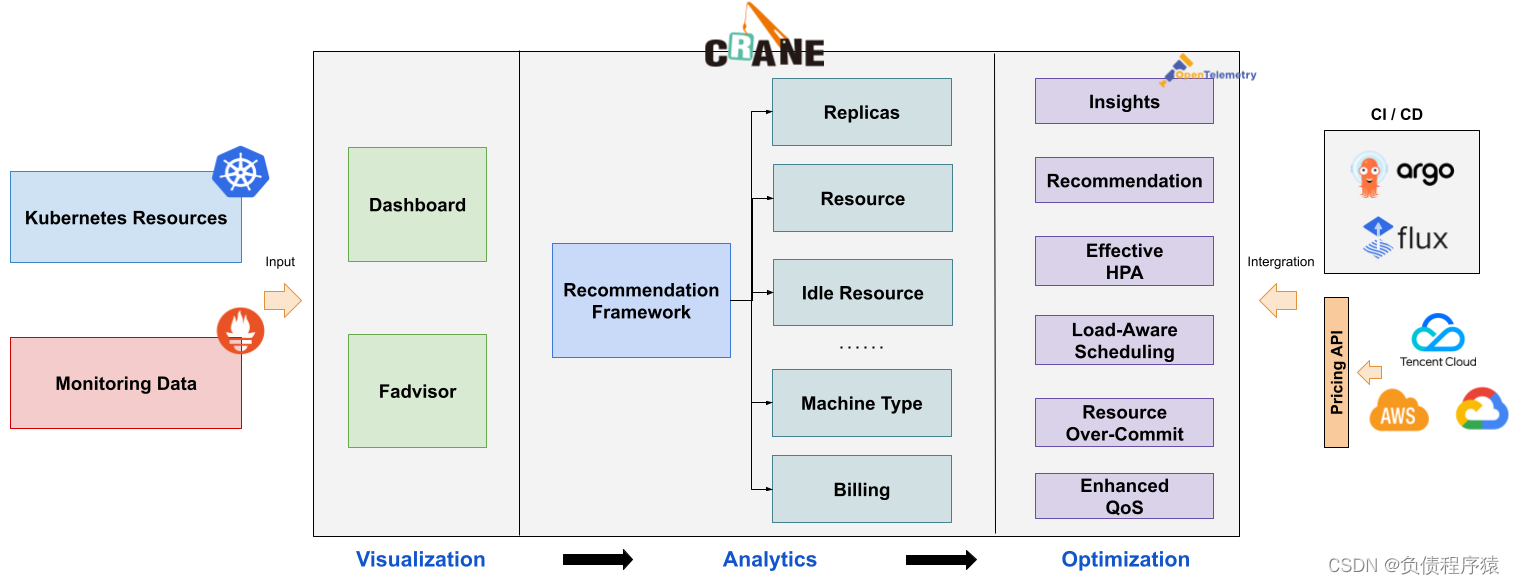
成本可视化和优化评估
- crane提供一组 Exporter 计算集群云资源的计费和账单数据并存储到你的监控系统,比如 Prometheus。
- 多维度的成本洞察,优化评估。通过 Cloud Provider 支持多云计费。
推荐框架
提供了一个可扩展的推荐框架以支持多种云资源的分析,内置了多种推荐器:资源推荐,副本推荐,HPA 推荐,闲置资源推荐。
基于预测的水平弹性器
EffectiveHorizontalPodAutoscaler 支持了预测驱动的弹性。它基于社区 HPA 做底层的弹性控制,支持更丰富的弹性触发策略(预测,观测,周期),让弹性更加高效,并保障了服务的质量。
负载感知的调度器
动态调度器根据实际的节点利用率构建了一个简单但高效的模型,并过滤掉那些负载高的节点来平衡集群。
拓扑感知的调度器
Crane Scheduler与Crane Agent配合工作,支持更为精细化的资源拓扑感知调度和多种绑核策略,可解决复杂场景下“吵闹的邻居问题",使得资源得到更合理高效的利用。
基于 QOS 的混部
QOS相关能力保证了运行在 Kubernetes 上的 Pod 的稳定性。具有多维指标条件下的干扰检测和主动回避能力,支持精确操作和自定义指标接入;具有预测算法增强的弹性资源超卖能力,复用和限制集群内的空闲资源;具备增强的旁路cpuset管理能力,在绑核的同时提升资源利用效率。
降本利器三驾马车
- 成本展示: Kubernetes 资源( Deployments, StatefulSets )的多维度聚合与展示。
- 成本分析: 周期性的分析集群资源的状态并提供优化建议。
- 成本优化: 通过丰富的优化工具更新配置达成降本的目标。
简而言之,crane提供一些自动化的策略来对k8s集群进行监控和管理,从而实现成本管理。
多说无益,直接上手体验吧
步骤概览:
- 使用 Kind 安装一个本地运行的 Kubernetes 集群
- 使用 Helm 安装 Prometheus 和 Grafana
- 使用 Helm 安装 Crane
- 通过 kubectl 的 port-forward 访问 Crane Dashboard
官方文档写的很清晰,这里我就只说重点步骤,详情请移步crane安装文档
部署环境要求
- kubectl
- Kubernetes 1.18+
- Helm 3.1.0
- Kind 0.16+
Crane 需要用到Prometheus作数据采集,并且在grafana作数据展示,所以我们需要安装依赖
注意:以下命令是直接安装Crane 以及其依赖 (Prometheus/Grafana)
curl -sf https://raw.githubusercontent.com/gocrane/crane/main/hack/local-env-setup.sh | sh -
查看所有Pod 都正常运行
$ export KUBECONFIG=${HOME}/.kube/config_crane
$ kubectl get deploy -n crane-system
NAME READY STATUS RESTARTS AGE
crane-agent-5r9l2 1/1 Running 0 4m40s
craned-6dcc5c569f-vnfsf 2/2 Running 0 4m41s
fadvisor-5b685f4cd6-xpxzq 1/1 Running 0 4m37s
grafana-64656f6d54-6l24j 1/1 Running 0 4m46s
metric-adapter-967c6d57f-swhfv 1/1 Running 0 4m41s
prometheus-kube-state-metrics-7f9d78cffc-p8l7c 1/1 Running 0 4m46s
prometheus-node-exporter-4wk8b 1/1 Running 0 4m40s
prometheus-server-fb944f4b7-4qqlv 2/2 Running 0 4m46s
注意:pod启动耗时跟自己机器配置和网络有关,如不能访问建议先不要排查问题,过几分钟再试试如果不行再继续排查
访问 Crane Dashboard
kubectl -n crane-system port-forward service/craned 9090:9090
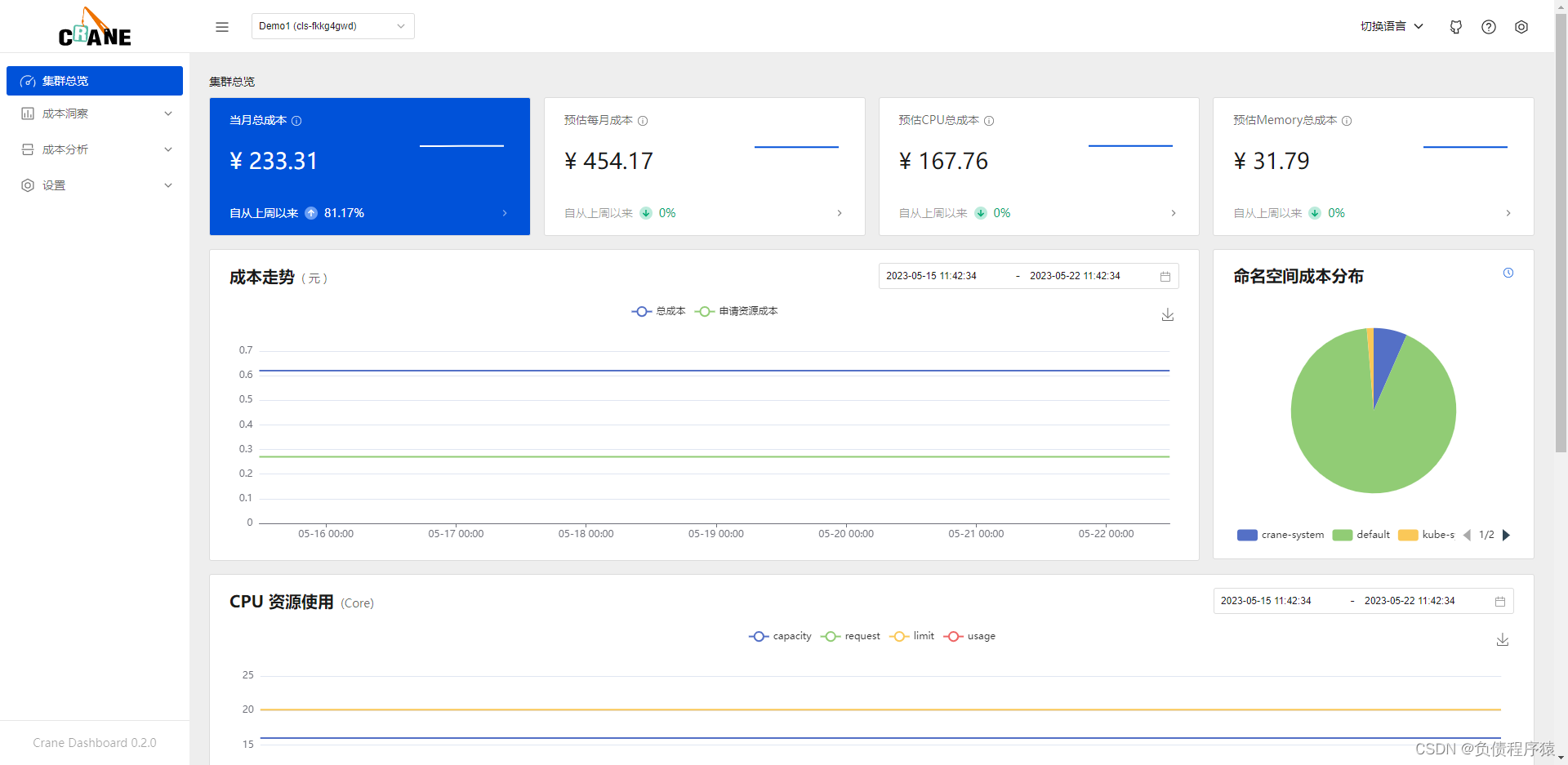
嘿嘿,如不想安装,可直接访问官方demo,传送门
应用资源优化模型
crane基于 Kubernetes 应用的特点总结出云原生应用的资源优化模型

图中五条线从上到下分别是:
- 节点容量:集群中所有节点的资源总量,对应集群的 Capacity
- 已分配:应用申请的资源总量,对应 Pod Request
- 周峰值:应用在过去一段时间内资源用量的峰值。周峰值可以预测未来一段时间内的资源使用,通过周峰值配置资源规格的安全性较高,普适性更强
- 日均峰值:应用在近一天内资源用量的峰值
- 均值:应用的平均资源用量,对应 Usage
其中资源的闲置分两类:
- Resource Slack:Capacity 和 Request 之间的差值
- Usage Slack:Request 和 Usage 之间的差值
Total Slack = Resource Slack + Usage Slack
资源优化的目标是减少 Resource Slack 和 Usage Slack。
模型中针对如何一步步减少浪费提供了四个步骤,从上到下分别是:
- 提升装箱率:提升装箱率能够让 Capacity 和 Request更加接近。手段有很多,例如:动态调度器、腾讯云的云原生节点的节点放大功能等
- 业务规格调整减少资源锁定:根据周峰值资源用量调整业务规格使的 Request 可以减少到周峰值线。资源推荐和副本推荐可以帮助应用实现此目标。
- 业务规格调整+扩缩容兜底流量突发:在规格优化的基础上再通过 HPA 兜底突发流量使的 Request 可以减少到日均峰值线。此时 HPA 的目标利用率偏低,仅为应对突发流量,绝大多数时间内不发生自动弹性。弹性推荐可以扫描出适合做弹性的应用并提供HPA配置。
- 业务规格调整+扩缩容应对日常流量变化:在规格优化的基础上再通过 HPA 应用日常流量使的 Request 可以减少到均值。此时 HPA 的目标利用率等于应用的平均利用率。EHPA实现了基于预测的水平弹性,帮助更多应用实现智能弹性。
总结
如果没有腾讯云 Finops Crane 集训营,我不会这么快接触到crane,之前试想过有没有这样一个系统,它能实时看到k8s集群中各个应用的成本概览,这样我们就能更好、更合理的进行资源调度,进而控制运维成本,自从认识crane后我突然明白,这就是我心里的那个它~
crane也让我明白了技术发展的核心不止于“能跑就行”,满足需求只是大前提,降本增效才是优化的核心方向。
最后
关于腾讯云 Finops Crane 集训营:
Finops Crane集训营主要面向广大开发者,旨在提升开发者在容器部署、K8s层面的动手实践能力,同时吸纳Crane开源项目贡献者,鼓励开发者提交issue、bug反馈等,并搭载线上直播、动手实验组队、有奖征文等系列技术活动。既能让开发者通过活动对 Finops Crane 开源项目有深入了解,同时也能帮助广大开发者在云原生技能上有实质性收获。
为奖励开发者,我们特别设立了积分获取任务和对应的积分兑换礼品。
ok我话说完






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结