您现在的位置是:首页 >学无止境 >如何利用 Playwright 对已打开的浏览器进行爬虫网站首页学无止境
如何利用 Playwright 对已打开的浏览器进行爬虫
之前写过一篇关于如何利用 Selenium 操作已经打开的浏览器进行爬虫的文章
如何利用 Selenium 对已打开的浏览器进行爬虫!
最近发现很多人都开始摒弃 Selenium,全面拥抱 Playwright 了,那如何利用 Playwright 进行爬虫,以应对一些反爬严格的网站呢?
对 Playwright 不了解的小伙伴,可以看很早之前写过的一篇文章
具体操作步骤如下:
PS:这里以 Chrome 为例,其他浏览器类似
1-1 查看本地 Chrome 浏览器的的安装地址
比如:C:Program FilesGoogleChromeApplicationchrome.exe
1-2 命令行启动浏览器
打开 CMD 终端,输入下面命令行打开 Chrome 浏览器
# 使用无痕模式,打开目标网站,最大化展示
cd C:Program FilesGoogleChromeApplication && chrome.exe --remote-debugging-port=6666 --user-data-dir="C:workchrome" --start-maximized --incognito --new-window https://www.taobao.com其中
-
--remote-debugging-port 端口号
指定浏览器调试端口号
PS:这里可以随机指定一个端口号,不要指定为已经被占用的端口号
-
--user-data-dir 用户数据保存目录
指定浏览器的用户数据保存目录
注意:需要设置到一个全新的目录,不要影响 Chrome 浏览器系统用户的数据
-
--incognito 用户数据保存目录
无痕模式打开,默认非无痕模式
-
--start-maximized
窗口最大化显示
-
--new-window 目标地址
直接打开目标网站
1-3 编写代码操作浏览器
使用命令行打开 Chrome 浏览器后,就可以使用 Playwright 编写代码,继续对浏览器进行操作
注意:必须保证上面的操作只打开一个浏览器窗口,方便我们进行操作
2 实战一下
目标:使用 Playwright 操作上面命令行打开的浏览器页面,根据关键字进行搜索,获取商品标题及地址
需要注意的是,通过 connect_over_cdp 指定的端口号要和浏览器调试端口号保持一致
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.connect_over_cdp('http://localhost:6666/')
# 获取页面对象
# 上下文索引:第一个
# page索引:第一个
page = browser.contexts[0].pages[0]
# 输入
page.locator("#q").fill("Python")
# 点击搜索
page.locator(".btn-search").click()
# 等待元素出现
# 注意:由于page.locator能获取多条数据,这里使用first获取1条数据,避免wait_for()方法报错
page.locator("div[class^=Card--doubleCard]").first.wait_for(state='visible')
# 获取商品盒子下所有div元素列表
elements = page.locator("div[class^=Content--contentInner]>div").all()
# 遍历,获取标题及地址
for element in elements:
# 标题
title_element = element.locator("div[class^=Title--title--] > span").first
# 地址
href_element = element.locator("a[class^=Card--doubleCardWrapper--]")
href = "https:" + href_element.get_attribute("href")
print("标题:", title_element.text_content(), ",URL:", href)最后:下方这份完整的软件测试视频学习教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】
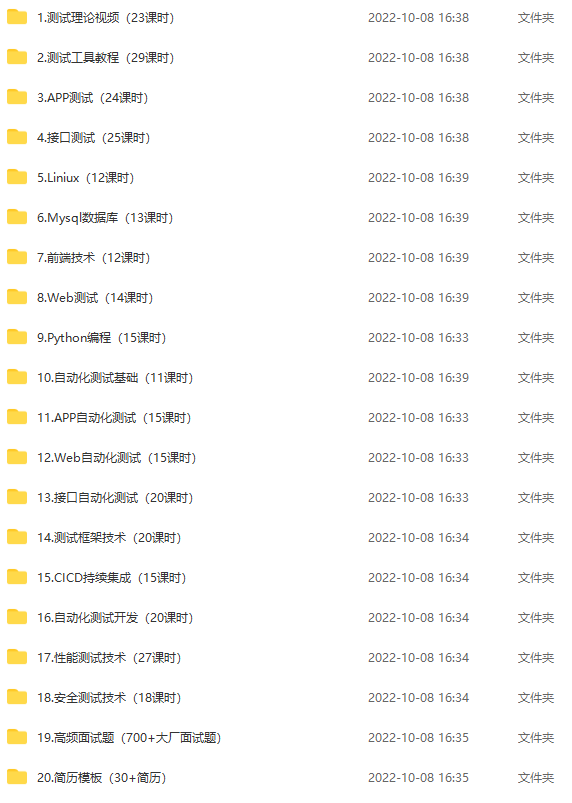
软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
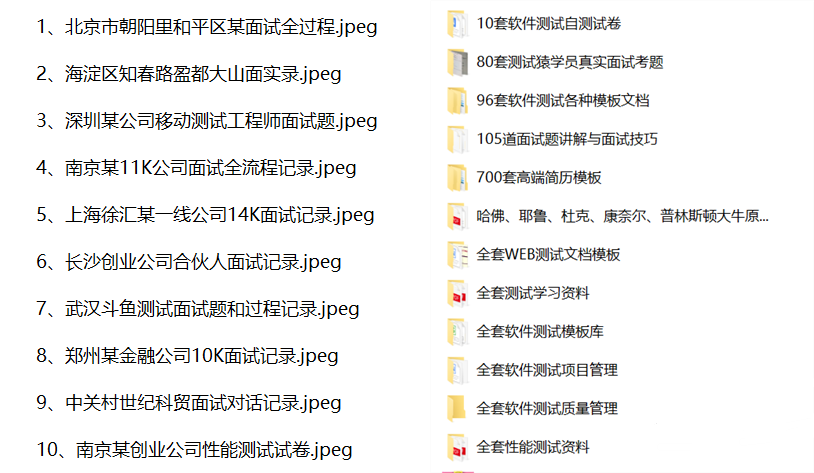








站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结