您现在的位置是:首页 >其他 >PDF大文件批量去除水印,又一个省心小妙招网站首页其他
PDF大文件批量去除水印,又一个省心小妙招
PDF大文件批量去除水印,又一个省心小妙招
导入
在阅读过程中如果遇到一些带有水印的资料是比较烦心的,如下图所示,水印以及类似的内容会影响我们的阅读体验,而市面上去水印的功能有多要收费且很不方便,那么,如何通过Python来对这类图片水印进行去除呢?
适用场景:本教程适合批量去除文件量较大的PDF文档内的图片水印。
使用软件:Python;
需安装第三方库:PIL,fitz,pymupdf
pip install PIL
pip install fitz
pip install pymupdf
不说废话,先把代码贴在前面。
from PIL import Image
import fitz
import os
def replace_color(img_path):
new_color = (255, 255, 255, 255)
for filename in os.listdir(img_path):
image = Image.open(os.path.join(img_path, filename))
new_pixels = [new_color if pixel == (220,220,220) else pixel for pixel in image.getdata()]
new_image = Image.new(image.mode, image.size)
new_image.putdata(new_pixels)
new_image.save(os.path.join(img_path, filename))
def convert_pdf_to_images(img_path,doc):
for i, page in enumerate(doc):
pix = page.getPixmap(matrix=fitz.Matrix(2, 2))
img_output_path = os.path.join(img_path, f"{i+1:04d}.jpg")
pix.writePNG(img_output_path)
def creat_file(img_path):
if not os.path.exists(img_path):
os.makedirs(img_path)
else:
for root, dirs, files in os.walk(img_path, topdown=False):
for name in files:
os.remove(os.path.join(root, name))
for name in dirs:
os.rmdir(os.path.join(root, name))
def convert_images_to_pdf(img_path, output_path):
image_list = []
for filename in os.listdir(img_path):
image_list.append(Image.open(os.path.join(img_path, filename)))
image_list[0].save(output_path, save_all=True, append_images=image_list[1:])
def delete_watermark(file_path):
folder_path = os.path.dirname(file_path)
file_name = os.path.basename(file_path)
output_path = os.path.join(folder_path, 'new_'+file_name)
img_path = os.path.join(folder_path, f"img_{os.path.splitext(file_name)[0]}")
creat_file(img_path)
convert_pdf_to_images(img_path, doc=fitz.open(file_path))
replace_color(img_path)
convert_images_to_pdf(img_path, output_path)
if __name__ == "__main__":
delete_watermark('E:...example.pdf')
正文
为了不影响阅读体验,一般水印都是由灰色或红色等与正文内容明显不同的颜色构成的。因此,要去除此类水印只需要判断出它是哪种颜色,然后将此颜色替换为背景色即可。
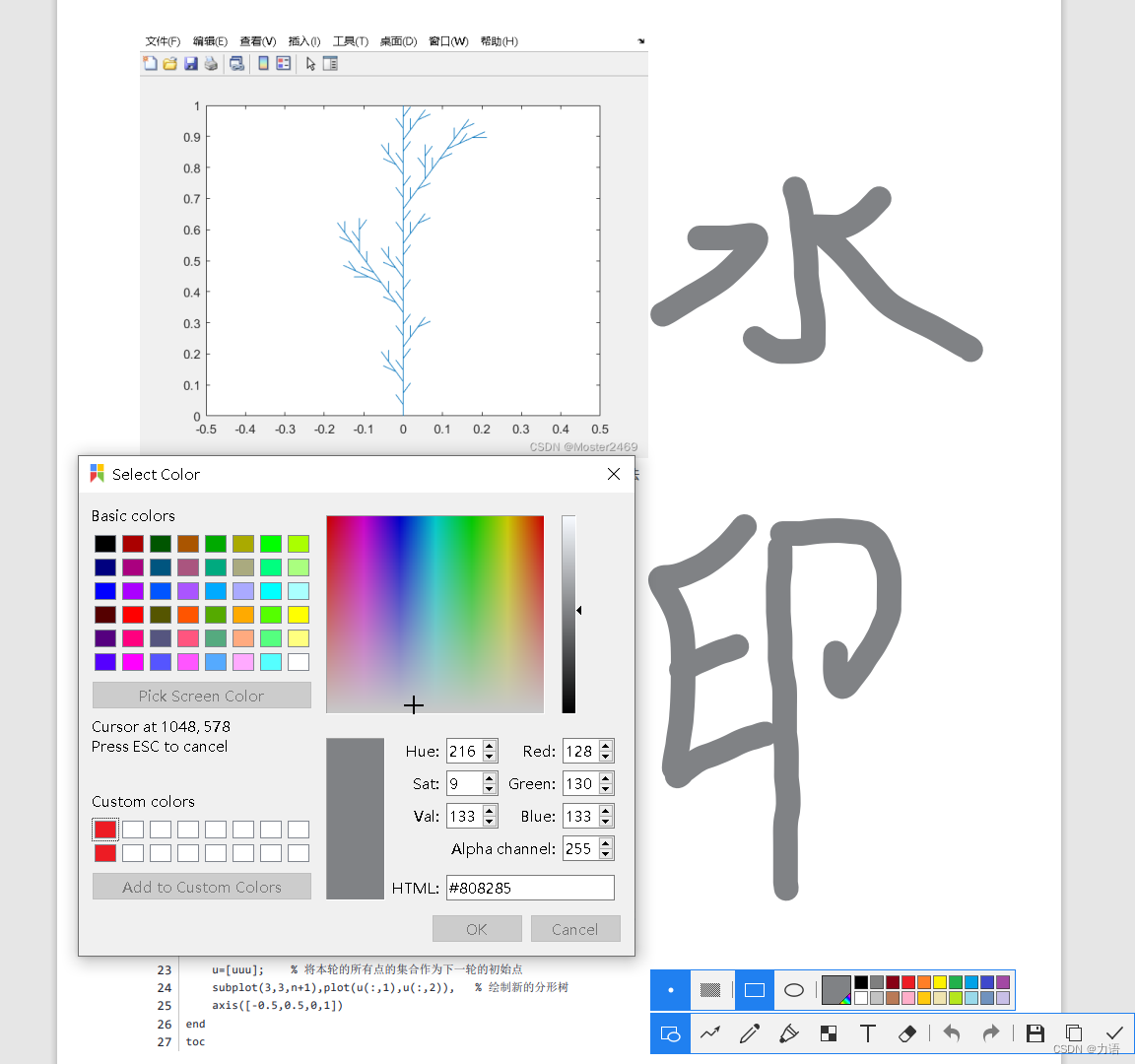
以上面图片中的水印为例,我们通过对水印部分进行取色可以看到,水印的 RGB 值为 (128, 130, 133),背景色为白色( RGB为 (255, 255, 255) ),那么我们只需要将 RGB 值为 (128, 130, 133) 的像素值替换为 (255, 255, 255) 即可实现图像水印的去除。
博主使用的取色工具为 Snipaste,也可以用 PS 等其它工具对水印取色。
首先需要将 PDF 中的一页信息提取出来,我们使用的是 fitz 库。
# 将 PDF 文件分解为图片
def convert_pdf_to_images(img_path,doc)
for i, page in enumerate(doc):
pix = page.getPixmap(matrix=fitz.Matrix(2, 2))
img_output_path = os.path.join(img_path, f"{i+1}.jpg")
pix.writePNG(img_output_path)
然后再对图片中的特定颜色进行替换
def replace_color(pixel, old_color, new_color):
if pixel in old_color:
return new_color
else:
return pixel
old_color = (128, 130, 133)
new_color = (255, 255, 255)
# 遍历输入文件夹中的所有.jpg文件并进行颜色替换
for filename in os.listdir(input_folder):
if filename.endswith('.jpg') or filename.endswith('.png'):
# 打开图片并获取像素数据
image = Image.open(os.path.join(input_folder, filename))
pixels = list(image.getdata())
# 遍历像素数据并进行颜色替换
new_pixels = [replace_color(pixel, old_color, new_color) for pixel in pixels]
# 将修改后的像素数据保存到新文件夹中
new_image = Image.new(image.mode, image.size)
new_image.putdata(new_pixels)
new_image.save(os.path.join(output_folder, filename))
最后再将图片拼接起来则得到去水印后的 PDF
def convert_images_to_pdf(img_path, output_path):
image_list = []
for filename in sorted(os.listdir(img_path), key=lambda x: int(x.split('.')[0])):
image_list.append(Image.open(os.path.join(img_path, filename)))
image_list[0].save(output_path, save_all=True, append_images=image_list[1:])
将以上三个步骤合并,即可得到我们的最终代码
from PIL import Image
import fitz
import os
def replace_color(img_path):
new_color = (255, 255, 255, 255)
for filename in os.listdir(img_path):
image = Image.open(os.path.join(img_path, filename))
new_pixels = [new_color if pixel == (220,220,220) else pixel for pixel in image.getdata()]
new_image = Image.new(image.mode, image.size)
new_image.putdata(new_pixels)
new_image.save(os.path.join(img_path, filename))
def convert_pdf_to_images(img_path,doc):
for i, page in enumerate(doc):
pix = page.getPixmap(matrix=fitz.Matrix(2, 2))
img_output_path = os.path.join(img_path, f"{i+1:04d}.jpg")
pix.writePNG(img_output_path)
def creat_file(img_path):
if not os.path.exists(img_path):
os.makedirs(img_path)
else:
for root, dirs, files in os.walk(img_path, topdown=False):
for name in files:
os.remove(os.path.join(root, name))
for name in dirs:
os.rmdir(os.path.join(root, name))
def convert_images_to_pdf(img_path, output_path):
image_list = []
for filename in os.listdir(img_path):
image_list.append(Image.open(os.path.join(img_path, filename)))
image_list[0].save(output_path, save_all=True, append_images=image_list[1:])
def delete_watermark(file_path):
folder_path = os.path.dirname(file_path)
file_name = os.path.basename(file_path)
output_path = os.path.join(folder_path, 'new_'+file_name)
img_path = os.path.join(folder_path, f"img_{os.path.splitext(file_name)[0]}")
creat_file(img_path)
convert_pdf_to_images(img_path, doc=fitz.open(file_path))
replace_color(img_path)
convert_images_to_pdf(img_path, output_path)
if __name__ == "__main__":
delete_watermark('E:...example.pdf')
只需要对水印和背景进行取色,然后更改相应代码即可实现全自动 Python 去水印功能。
由于水印颜色并不总是某一个RGB值,而是一个范围,所以也可以使用 218<pixel[0]<244 and 218<pixel[1]<244 and 218<pixel[2]<244: 替换 pixel == (220,220,220)。
上述程序在运行过程中会根据文件名,产生一个"img_[文件名]"文件夹用于存放图片,以及产生一个去除水印后的"new_[文件名].pdf"文件。

若不需要查看单张图片的效果,也可以直接运行如下代码,在等待一段时间后会直接生成去除水印后的 PDF。
import fitz
with fitz.open('example.pdf') as doc:
for page in doc:
pix = page.getPixmap(matrix=fitz.Matrix(2, 2))
pix = pix.applyFunction(lambda r,g,b: (255, 255, 255) if (r,g,b) == (220, 220, 220) else (r,g,b))
new_page = fitz.new_page(width=pix.width, height=pix.height)
new_page.insert_image(fitz.Rect(0, 0, pix.width, pix.height), pixmap=pix)
new_doc.save("new_example.pdf")
不过该方法生成的 PDF 文件会远大于原始文件,若是介意这点可继续用前一种方法。关于为什么该方法生成的文件变大这点,笔者目前也不清楚,如果有知道原因的朋友可以留下评论。
对于特别大的文件,可能导致 MemoryError,这时可以尝试先将图片分组,每组图片生成 pdf 文件后,再将多个 pdf 文件合并。
from PyPDF2 import PdfFileMerger
def convert_images_to_pdf2(img_path, pdf_path, output_path, num_group=10):
image_list = []
creat_file(pdf_path)
pdf_file = []
for i, filename in enumerate(os.listdir(img_path)):
img = Image.open(os.path.join(img_path, filename))
image_list.append(img)
if (i + 1) % num_group == 0:
split_pdf_path = os.path.join(pdf_path, f"{len(pdf_file)+1:04d}.pdf")
image_list[0].save(split_pdf_path, save_all=True, append_images=image_list[1:])
pdf_file.append(split_pdf_path)
image_list = []
pdfs = [os.path.join(pdf_path, f) for f in os.listdir(pdf_path)]
merger = PdfFileMerger()
for pdf in pdfs:
merger.append(pdf)
merger.write(os.path.join(pdf_path, output_path))
merger.close()






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结