您现在的位置是:首页 >学无止境 >微服务技术(SpringCloud、Docker、RabbitMQ)网站首页学无止境
微服务技术(SpringCloud、Docker、RabbitMQ)
目录
一、微服务技术简介
微服务是分布式架构(分布式:把服务拆分)的一种。
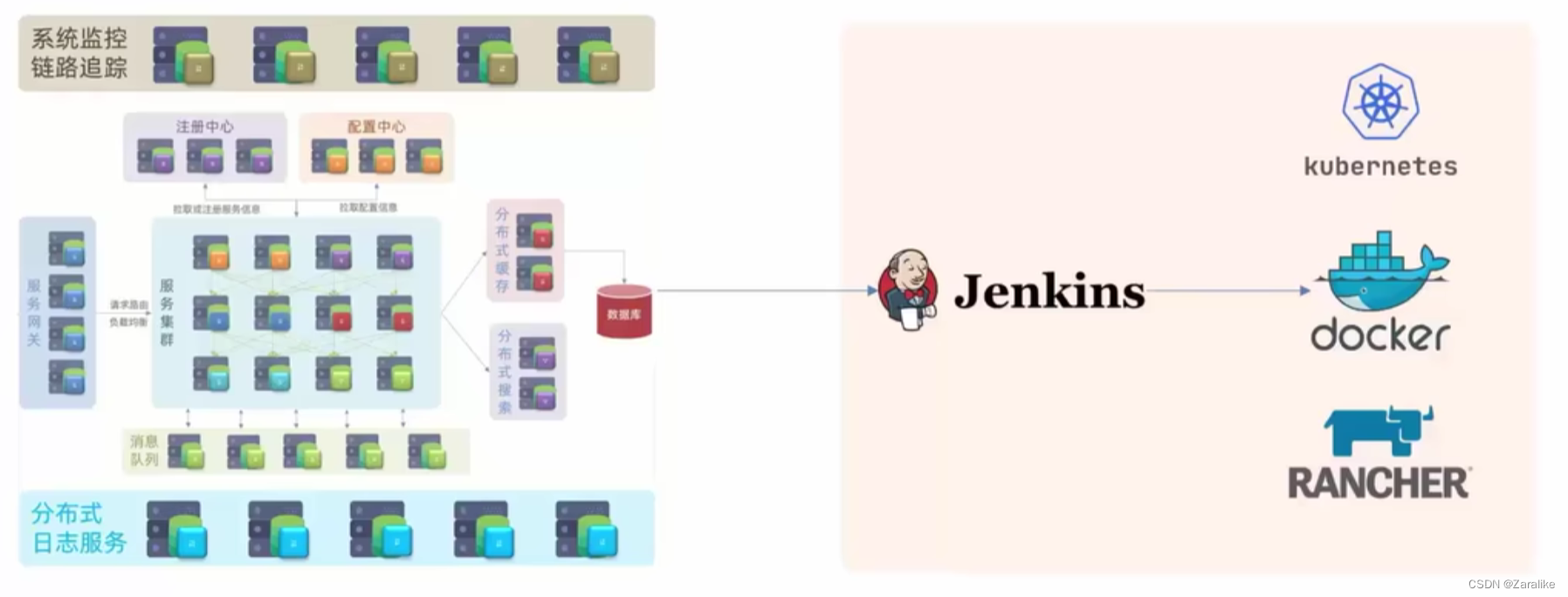
单体架构:将业务的所有功能集中在一个项目中开发,打成一个包部署。
优点:架构简单;部署成本低 缺点:耦合度高
分布式架构:根据业务功能对系统进行拆分,每个业务模块作为独立项目开发,称为一个服务。
优点:降低服务耦合;有利于服务升级拓展
分布式架构要考虑的问题:
- 服务拆分粒度如何?
- 服务集群地址如何维护?
- 服务之间如何实现远程调用?
- 服务健康状态如何感知?
微服务:一种经过良好架构设计的分布式架构方案,其特征为:
- 单一职责:微服务拆分粒度更小,每一个服务都对应唯一的业务功能,做到单一职责,避免重复业务开发
- 面向服务:微服务对外暴露业务接口
- 自治:团队独立、技术独立、数据独立、部署独立
- 隔离性强:服务调用做好隔离、容错、降级,避免出现级联问题
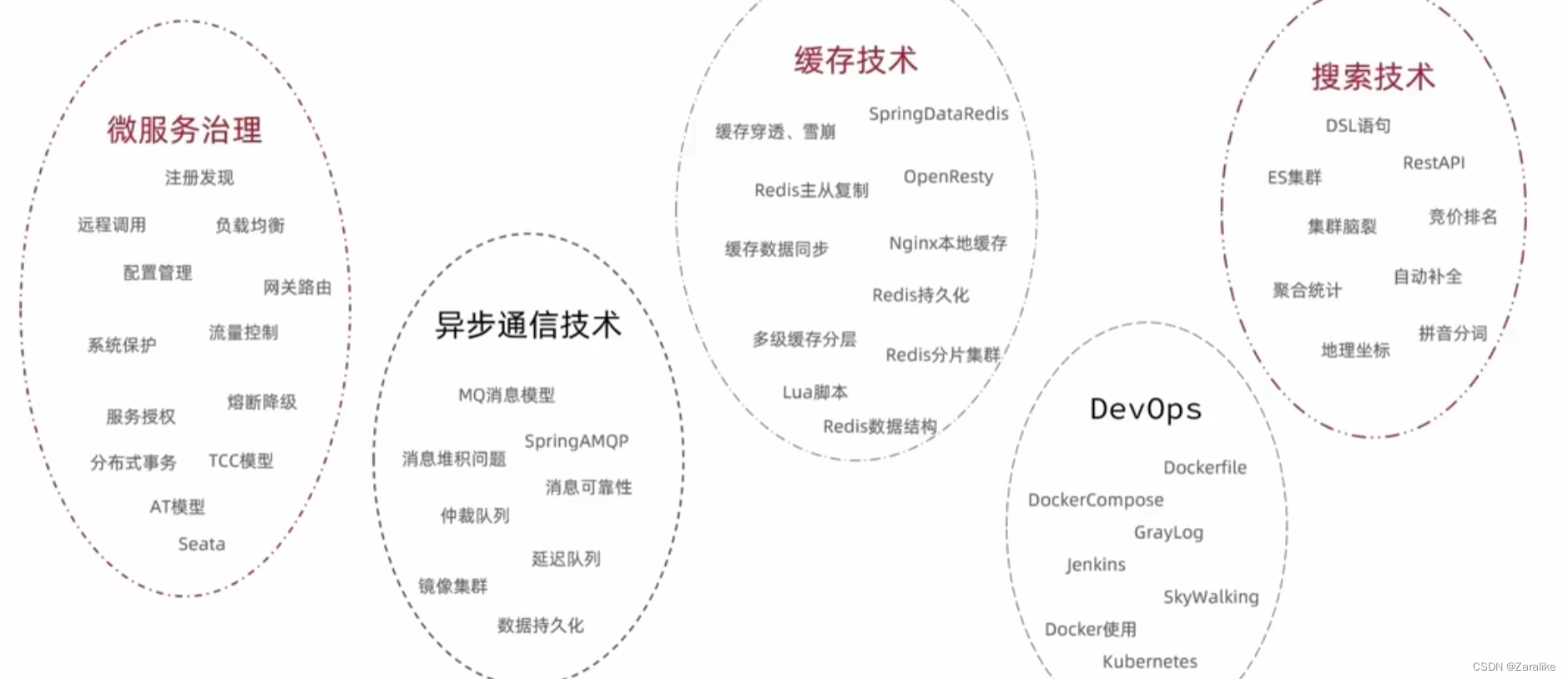
微服务技术对比:
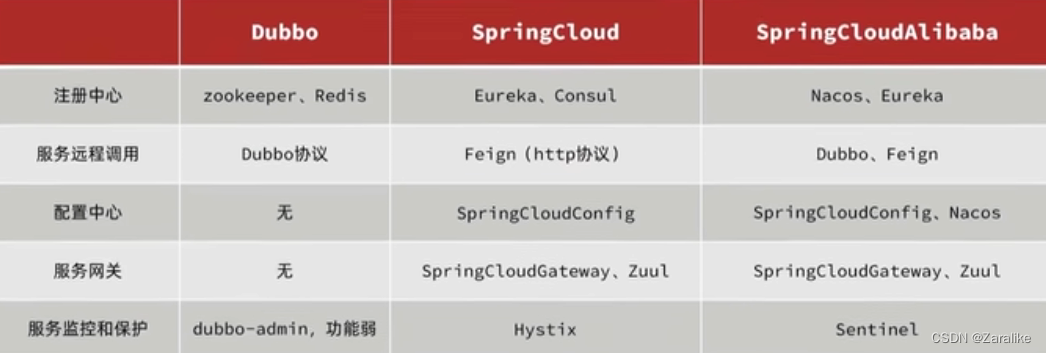
SpringCloud:https://spring.io/projects/spring-cloud
SpringCloud集成了各种微服务功能组件,并基于SpringBoot实现了这些组件的自动装配,从而提供了良好的开箱即用体验。
二、服务拆分及远程调用
服务拆分:
1.不同微服务,不要重复开发相同业务
2.微服务数据独立,每个微服务有自己的数据库,不要访问其他微服务的数据库
3.微服务可以将自己的业务暴露为接口,供其他微服务调用
远程调用:
1.基于RestTemplate发起的http请求实现远程调用(注册RestTemplate)
//在Application中注册RestTemplate
@MapperScan("cn.xxx.yyy.mapper")
@SpringBootApplication
public class Application{
public static void main(String[] args){
SpringApplication.run(Application.class,args);
}
@Bean
public RestTemplate restTemplate(){
return new RestTemplate();
}
}2.http请求做远程调用是与语言无关的调用,只要知道对方的ip、端口、接口路径、请求参数即可。
@Service
public class OrderService{
@Autowired
private RestTemplate restTemplate;
public Order queryOrderById(Long orderId){
Order order = orderMapper.findById(orderId);
String url = "http://localhost:8081/user/"+order.getUserId();
User user = resTemplate.getForObject(url,User.class);
order.setUser(user);
return order;
}
}1.Eureka注册中心
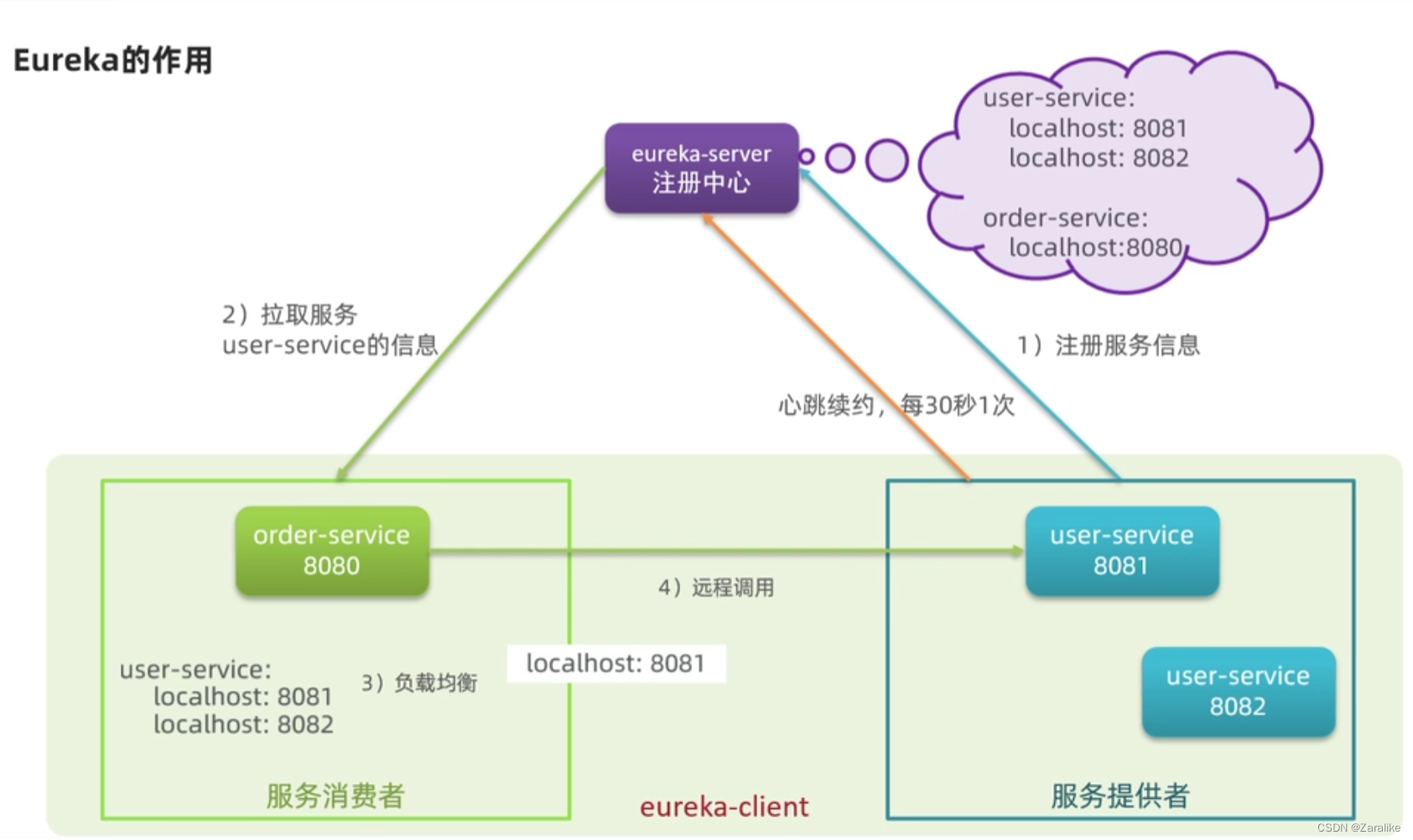
步骤:
1.搭建EurekaServer
- 引入eureka-server依赖
- 添加@EnableEurekaServer注解
- 在application.yml中配置eureka地址
2.服务注册
- 引入eureka-client依赖
- 在application.yml中配置eureka地址
3.服务发现
- 引入eureka-client依赖
- 在application.yml中配置eureka地址
- 给RestTemplate添加@LoadBalanced注解
- 用服务提供者的服务名称远程调用
Ribbon 负载均衡策略

1.Ribbon负载均衡规则
- 规则接口是IRule
- 默认实现是ZoneAvoidanceRule,根据zone选择服务列表,然后轮询
2.负载均衡自定义方式
- 代码发布:配置灵活,但修改时需要重新打包发布
- 配置方式:直观方便,无需重新打包发布,但是无法做全局配置
3.饥饿加载
- 开启饥饿加载(配置文件)
- 指定饥饿加载的微服务名称(可配置多个)
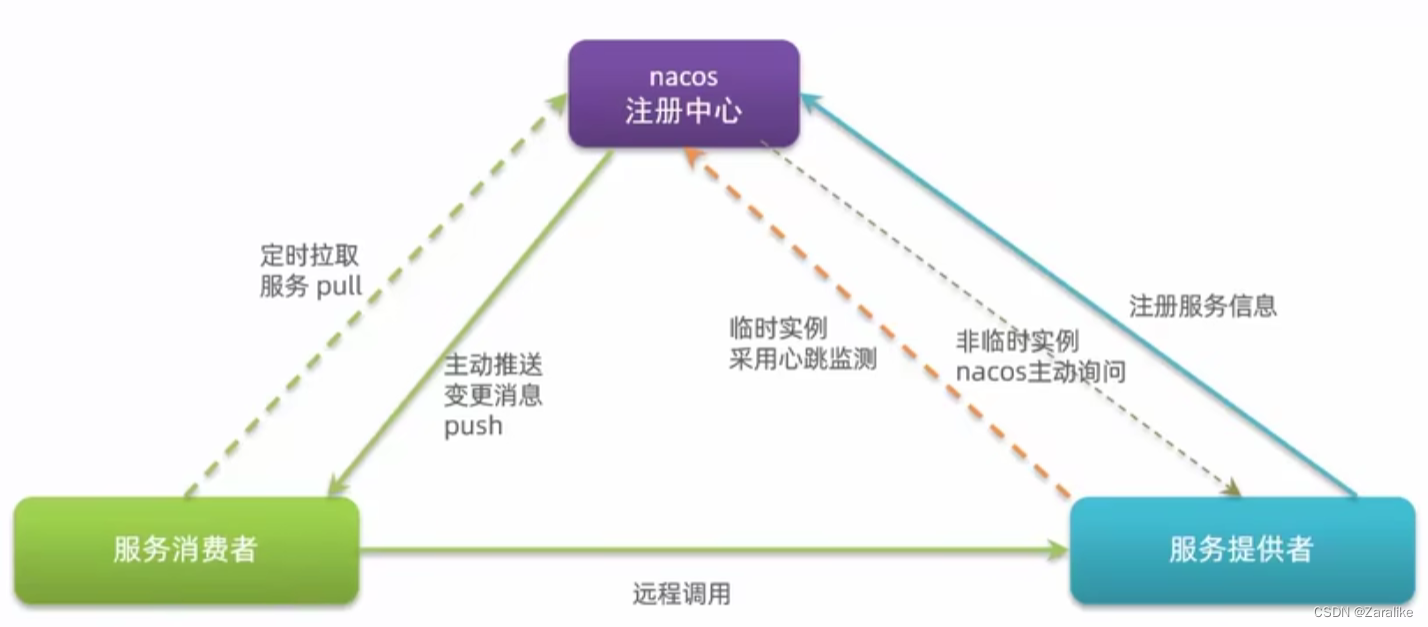
2.Nacos注册中心
Nacos服务搭建:
1.下载安装包 2.解压 3.在bin目录下运行命令:startup.cmd -m standalone
Nacos服务注册或发现:
1.引入nacos.discovery依赖 2.配置nacos地址spring.cloud.nacos.server-addr
服务多级存储模型:
一级是服务,例如userservice 2.二级是集群,例如北京上海 3.三级是实例,例如北京机房某台部署了userservice的服务器
设置实例的集群属性:配置spring.cloud.nacos.discovery.cluster-name
NacosRule负载均衡:
同集群优先访问,集群内随机访问
实例的权重控制:
Nacos控制台可设置实例的权重(0~1之间);权重设置为0则完全不会被访问(服务升级)
Nacos环境隔离:
namespace用来做环境隔离;每个namespace都有唯一id;不同namespace下的服务不可见
3.Nacos配置管理
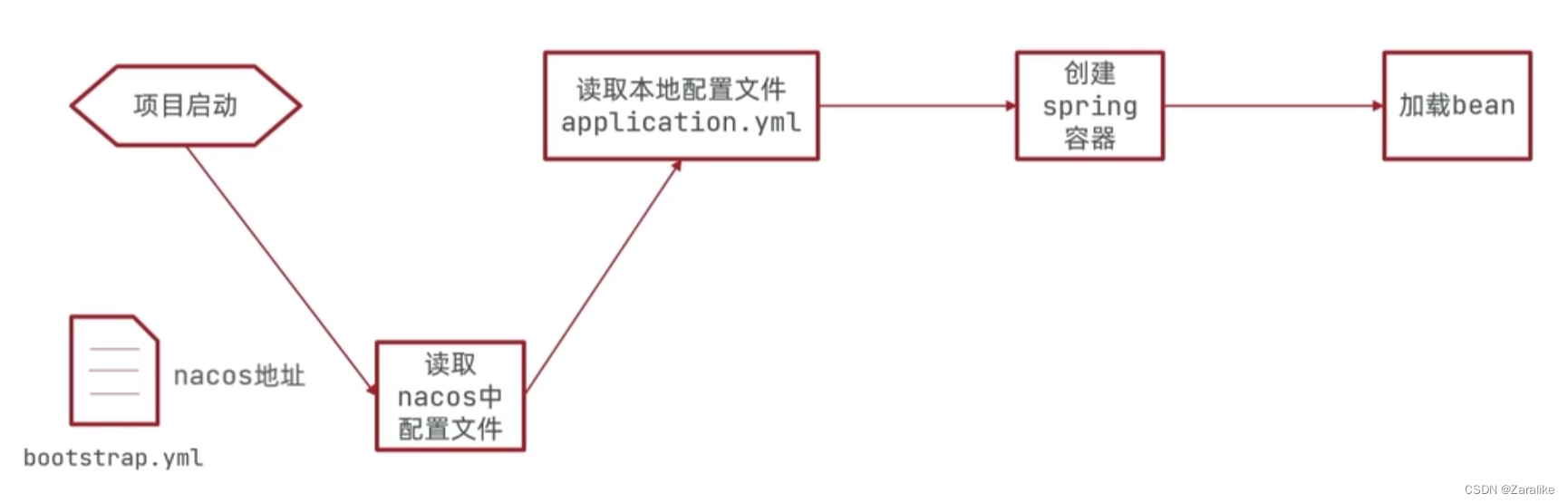
步骤:
1.在Nacos中添加配置文件
2.在微服务中引入nacos的config依赖
3.在微服务中添加bootstrap.yml,配置nacos地址、当前环境、服务名称、文件后缀名。
热更新:
方式1:通过@Value注解注入,结合@RefreshScope来刷新
方式2:通过@ConfigurationProperties注入,自动刷新
注意事项:
- 不是所有的配置都适合放到配置中心,维护起来比较麻烦
- 建议将一些关键参数,需要运行时调整的参数放到nacos配置中心,一般都是自定义配置
多环境配置共享:
微服务启动时会从nacos读取多个配置文件:
1.[服务名]-[spring.profile.active].yaml,环境配置
2.[服务名].yaml,默认配置,多环境共享(一定会加载,多环境共享配置可以写入这个文件)
优先级:[服务名]-[环境].yaml>[服务名].yaml>本地配置
nacos集群搭建:
1.搭建MySQL集群并初始化数据库表
2.下载解压nacos
3.修改集群配置(节点信息)、数据库配置
4.分别启动多个nacos节点
5.nginx反向代理
4.http客户端Feign
RestTemplate方式调用存在问题:
- 代码可读性差,编程体验不统一
- 参数复杂URL难以维护
Feign是一个声明式的http客户端,官方地址:https://github.com/OpenFeign/feign,其作用是帮助我们优雅地实现http请求的发送。
Feign的使用步骤:
1.引入依赖 2.添加@EnableFeignClients注解 3.编写FeignClient接口 4.使用FeignClient中定义的方法代替RestTemplate
Feign的日志配置:
方式一:配置文件,feign.client.config.xxx.loggerLevel(xxx:default代表全局;xxx:服务名称代表该服务)
方式二:java代码配置(@EnableFeignClients注解声明代表全局;@FeignClient注解声明代表某服务)
Feign的优化:
1.日志级别尽量用basic
2.使用HttpClient或OKHttp代替URLConnection
1)引入feign-httpClient依赖 2)配置文件开启httpClient功能,设置连接池参数
Feign的最佳实践:
实践一:让controller和FeignClient继承同一接口
实践二:将FeignClient、POJO、Feign的默认配置都定义到一个项目中供所有消费者使用
三、统一网关Gateway
网关作用:身份认证和权限校验;服务路由、负载均衡;请求限流
SpringCloud中网关的实现有2种:
- gateway:基于Sprin5中的WebFlux,属于响应式编程的实现,具备更好的性能
- zuul:基于Servlet的实现,属于阻塞式编程
网关搭建步骤:
1.创建项目,引入nacos服务发现和gateway依赖
2.配置application.yml,包括服务基本信息、nacos地址、路由
路由配置包括:路由id、路由目标地址(uri)、路由断言(判断路由的规则)、路由过滤器(对请求或响应做处理)
过滤器执行顺序:
- 每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前
- GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值;路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。、
- 当order值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFIiter的顺序执行。
四、Docker
项目部署问题:
- 依赖关系复杂,容易出现兼容性问题
- Docker允许开发中将应用、依赖、配置一起打包,形成可移植镜像
- Docker应用运行在容器中,使用沙箱机制,相互隔离
- 开发、测试、生产环境有差异
- Docker镜像中包含完整运行环境,包括系统函数库,仅依赖系统的Linux内核,因此可在任意Linux操作系统上运行
Docker和虚拟机的差异:
- docker是一个系统进程;虚拟机是在操作系统中的操作系统
- docker体积小、启动速度快、性能好;虚拟机体积大、启动速度慢、性能一般
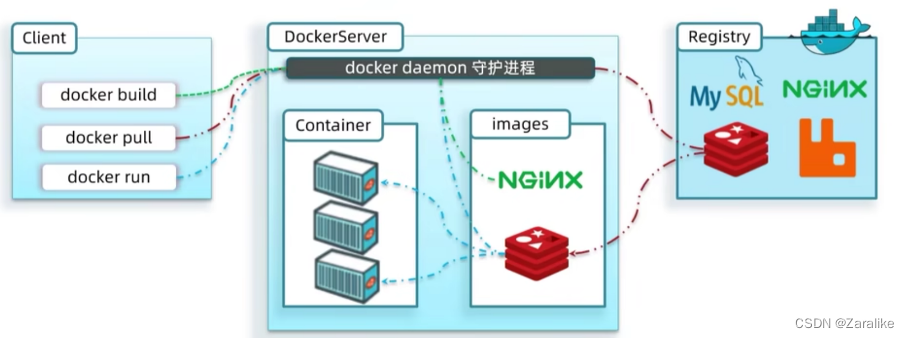
Docker架构:
镜像(Image):Docker将应用程序及其所需的依赖、函数库、环境、配置等文件打包在一起,称为镜像。
容器(Container):镜像中的应用程序运行后形成的进程就是容器,Docker会给容器做隔离,对外不可见。
Docker是一个CS架构的程序,由两部分组成:
- 服务端(server):Docker守护进程,负责处理Docker指令,管理镜像、容器等
- 客户端(client):通过命令或RestAPI向Docker服务端发送指令,可以在本地或远程向服务端发送指令。
DockerCompose部署微服务
1.编写docker-compose.yml文件
2.修改项目将数据库、nacos地址命名为docker-compose中的服务名
3.使用maven打包工具,将项目中的每个微服务都打包为app.jar
4.将打包好的app.jar拷贝到cloud-demo中的每一个对应子目录中
5.将cloud-demo上传至虚拟机,利用docker-compose up -d 部署
五、异步通信技术
同步调用
优点:时效性较强,可以立即得到结果
问题:耦合度高;性能和吞吐能力下降;有额外的资源消耗;有级联失败问题
异步通信
优点:耦合度低;吞吐量提升;故障隔离;流量削峰
缺点:依赖于Broker的可靠性、安全性、吞吐能力;架构复杂,业务没有明显的流程线,不好追踪管理
消息队列(MessageQueue)事件驱动架构中的Broker
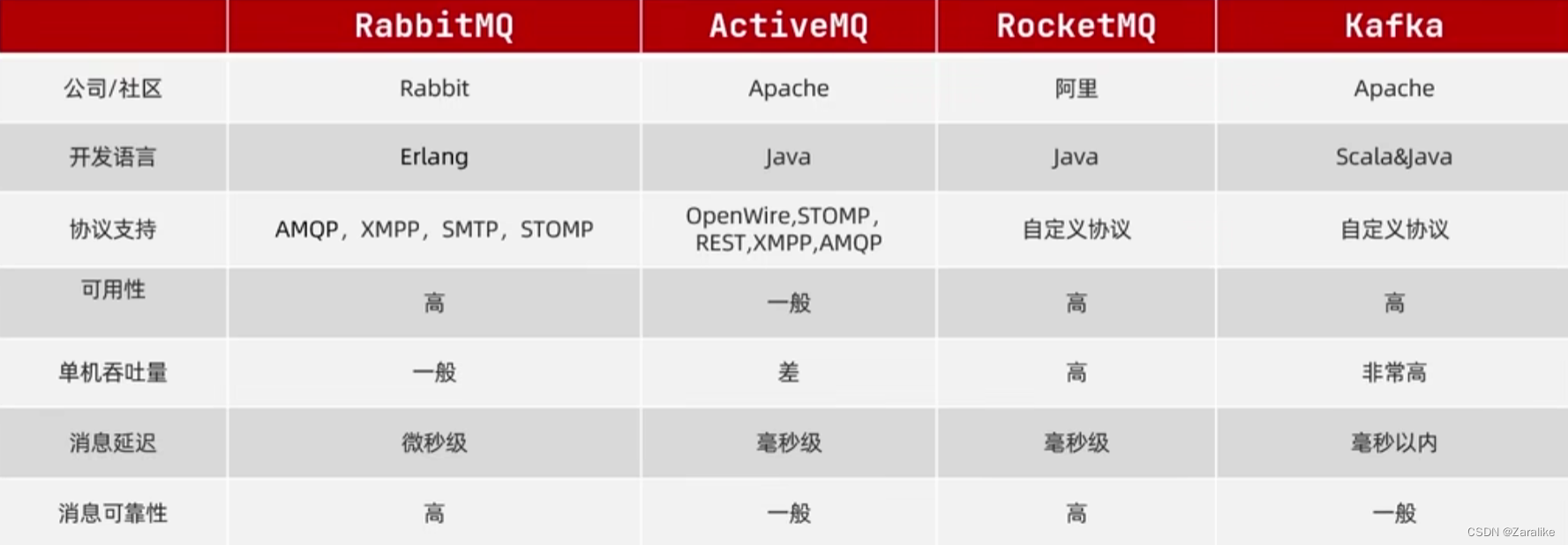
RabbitMQ:基于Erlang语言开发的开源消息通信中间件,官网地址:https://www.rabbitmq.com/
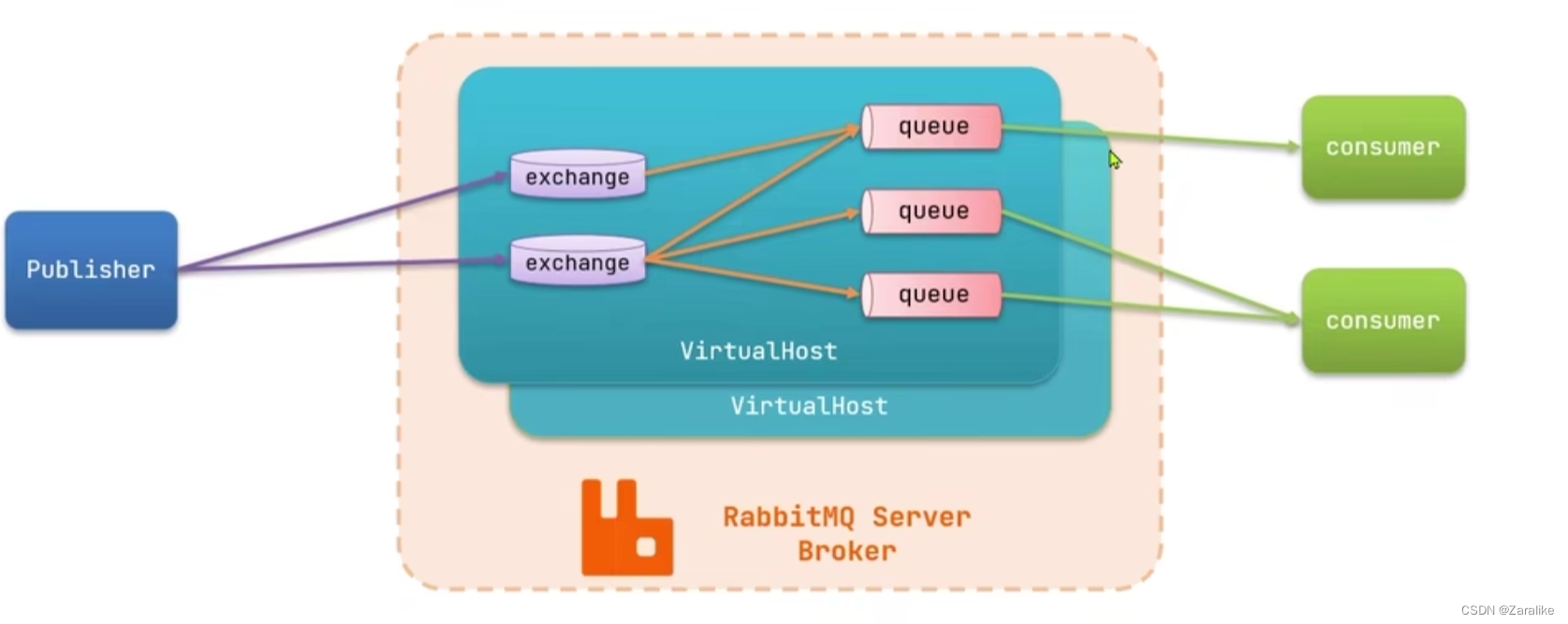
channel:操作MQ的工具
exchange:路由消息到队列中
queue:缓存消息
virtual host:虚拟主机,是对queue、exchange等资源的逻辑分组
SpringAMQP
官方地址:https://spring.io/projects/spring-amqp
AMQP(Advanced Message Queuing Protocol)是用于在应用程序之间传递业务消息的开放标准。该协议与语言和平台无关,更符合微服务中独立的要求。
Spring AMQP是基于AMQP协议定义的一套API规范,提供了模板来发送和接收消息,包含两部分,其中spring-amqp是基础抽象,spring-rabbit是底层的默认实现。
简单队列模型、WorkQueue模型、发布订阅模型(Fanout、Direct、Topic)
六、ElasticSearch
Lucene:Apache的开源搜索引擎类库,提供了搜索引擎的核心API
ElasticSearch:一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能,官网:https://www.elastic.co/cn/,优势:支持分布式,可水平扩展;提供Restful接口,可被任何语言调用
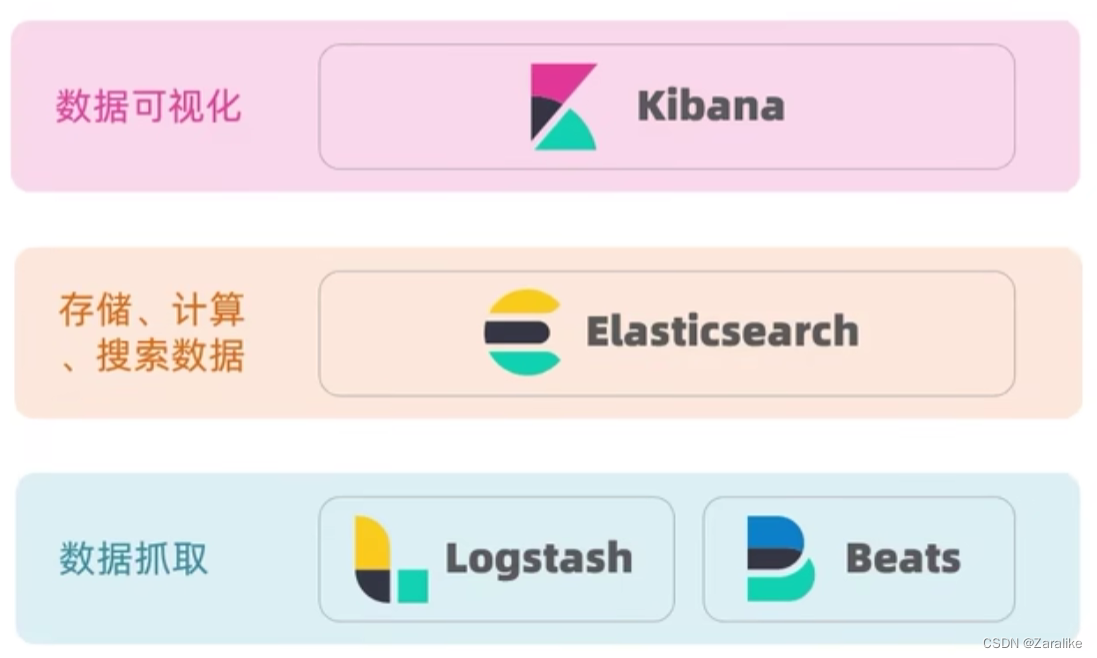
ElasticStack(ELK):以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
ElasticSearch采用倒排索引:
- 文档(document):每条数据就是一个文档
- 词条(term):文档按照语义分成的词语;对文档中的内容分词,得到的词语
正向索引:基于文档id创建索引。查询词条时必须先找到文档,而后判断是否包含词条
倒排索引:对文档内容分词,对词条创建索引,并记录词条所在文档的信息。查询时先根据词条查询到文档id,而后获取到文档

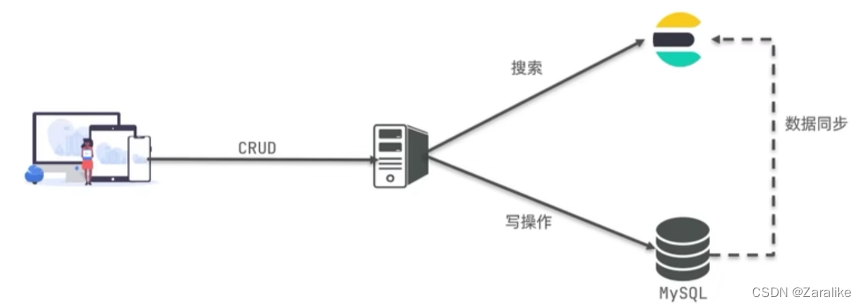
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
ElasticSearch:擅长海量数据的搜索、分析、计算
分词器作用:
- 创建倒排索引时对文档分词
- 用户搜索时,对输入的内容分词
IK分词器的模式:ik_smart(智能切分,粗粒度);ik_max_word(最细切分,细粒度)
利用config目录的ikAnalyzer.cfg.xml文件添加拓展词典和停用词典,在词典中添加拓展词条或者停用词条(P85)





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结