您现在的位置是:首页 >学无止境 >目标检测复盘 --4. Faster RCNN网站首页学无止境
目标检测复盘 --4. Faster RCNN
简介目标检测复盘 --4. Faster RCNN

- Fast RCNN的性能得到了很大的提升,但是还是有很大一部分开销在候选框的生成模块,也就是SS算法,Faster RCNN使用一个网络专门干这个事,从而加快整体检测速度,能达到5帧每秒。
- 所以这里的FasterRCNN也就是RPN+FastRCNN

- RPN,这里参考 https://blog.csdn.net/m0_63007797/article/details/127704034
- 流程:
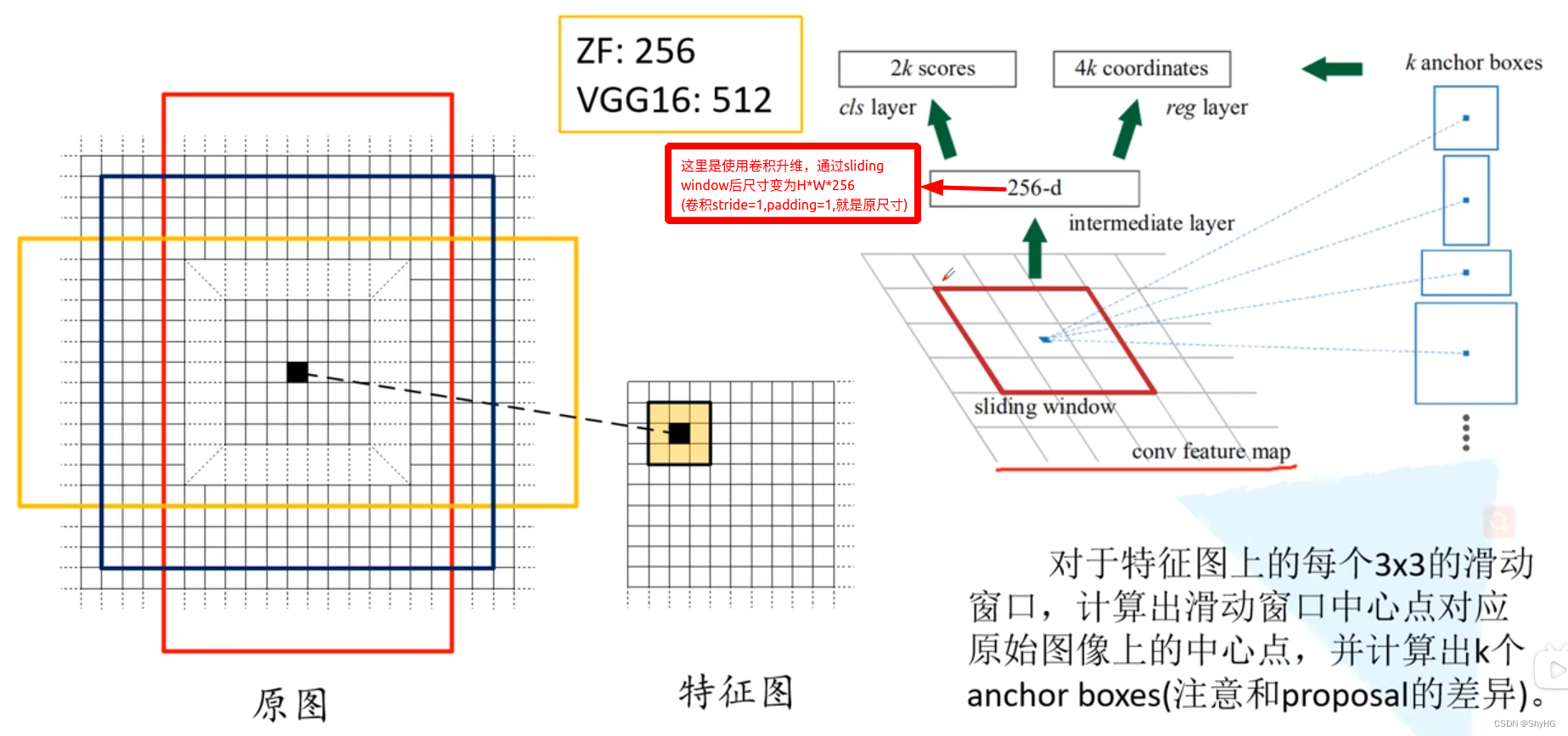
- 常规卷积提取特征获取feature map
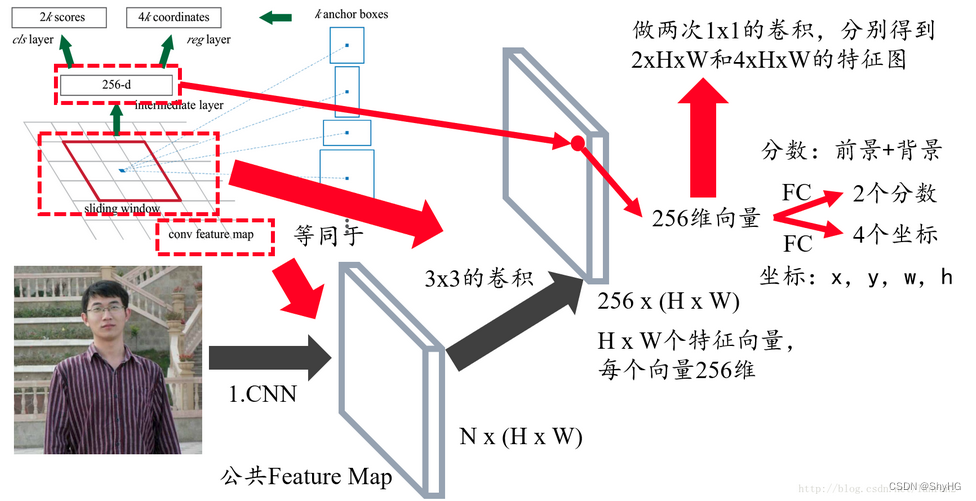
- 利用3*3,个数为256,stride=1,paddling=1的卷积核作为sliding window来卷积,得到H*W*256的特征图,对每个点的256维向量分别所两次全连接操作获得图中的2k scores和4k coordinates,论文中k=9
- 映射到特征图上,接入Fast RCNN步骤
- 更为详细的RPN解释
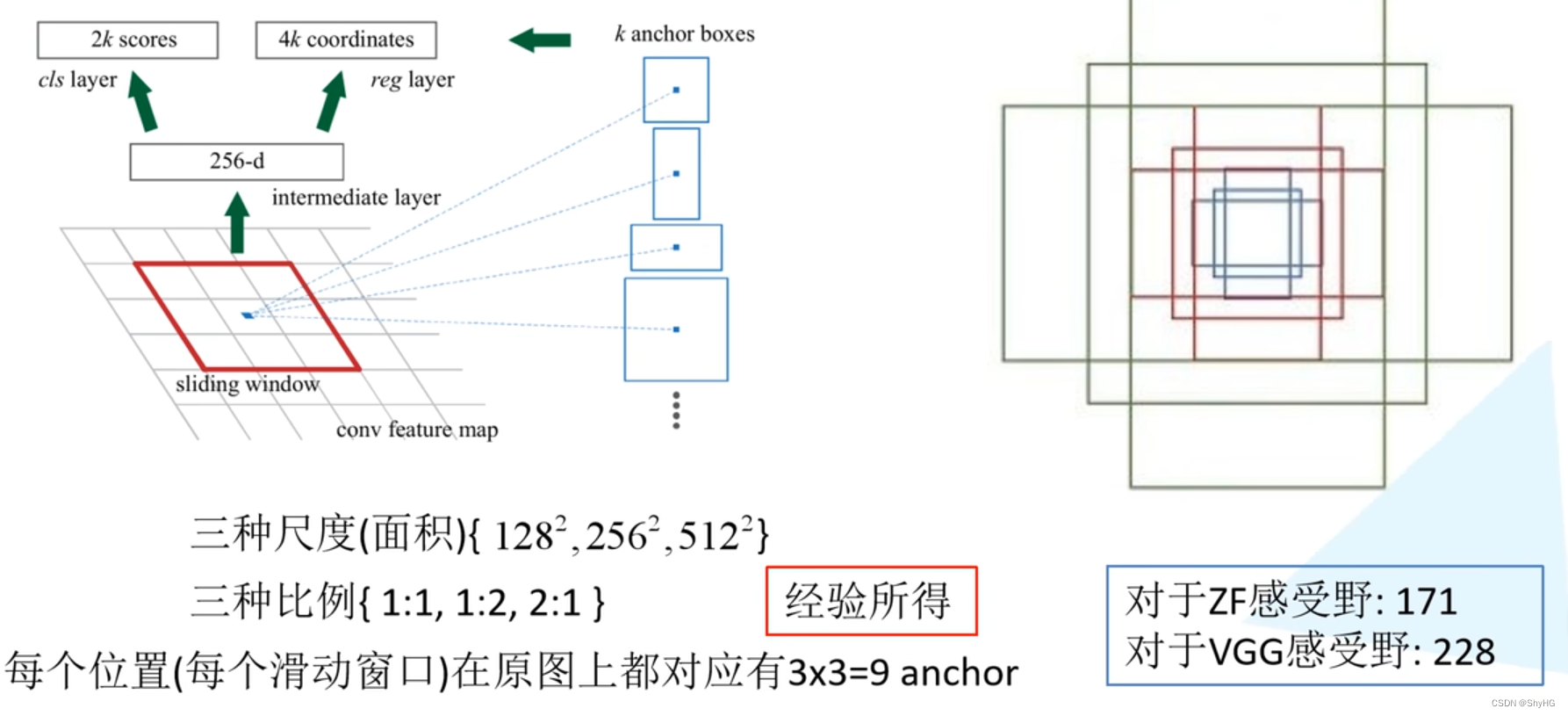
- anchor的选择,论文中提出使用9个anchor
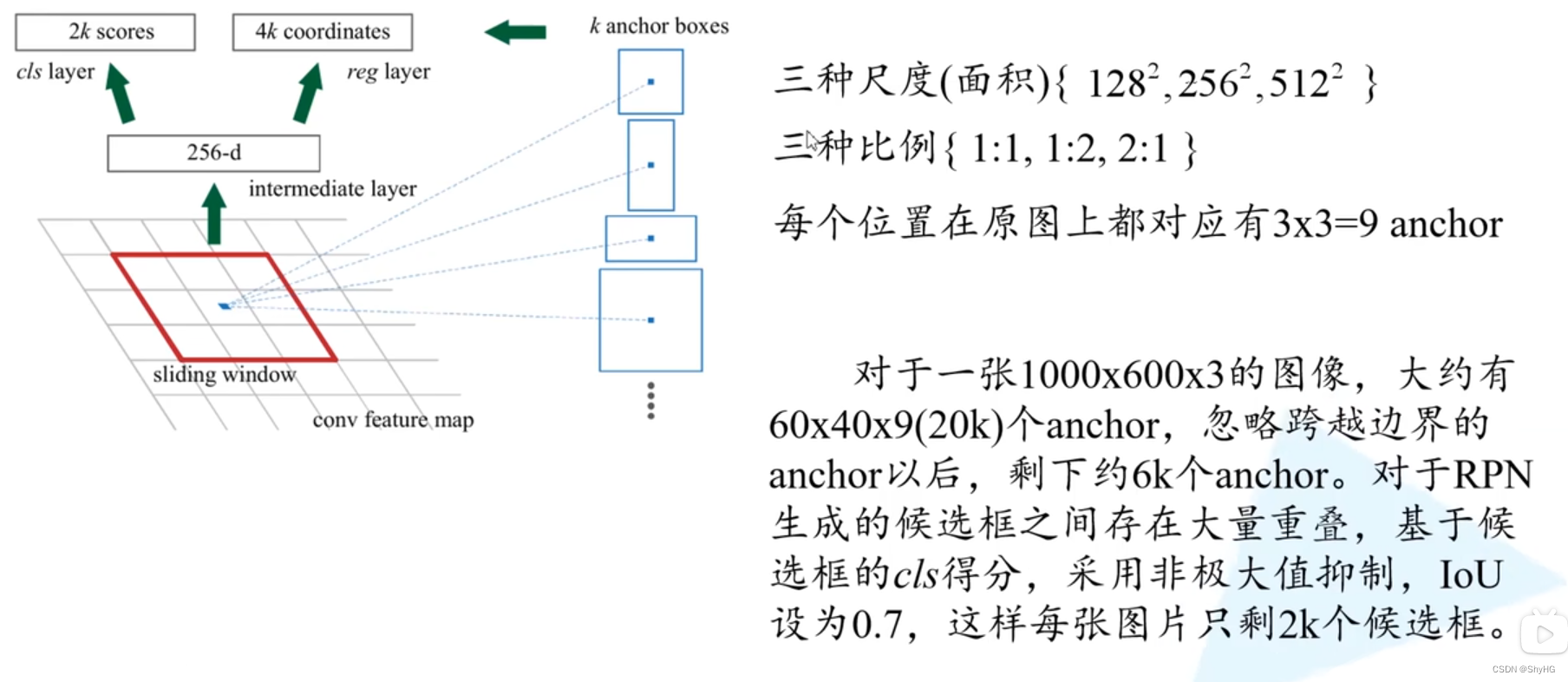
- 对于最终的anchor选择,采用如下策略
- RPN训练样本选择策略
- 随机采样256个样本,按照1:1的比例来选取,如果正样本少于128个,则使用负样本来补充

- 正负样本的定义:1.所有anchor中和真值的IOU最大认为是正样本(其实是对后面标准的补充) 2.只要anchor和真值的IOU大于0.7则被认为是正样本

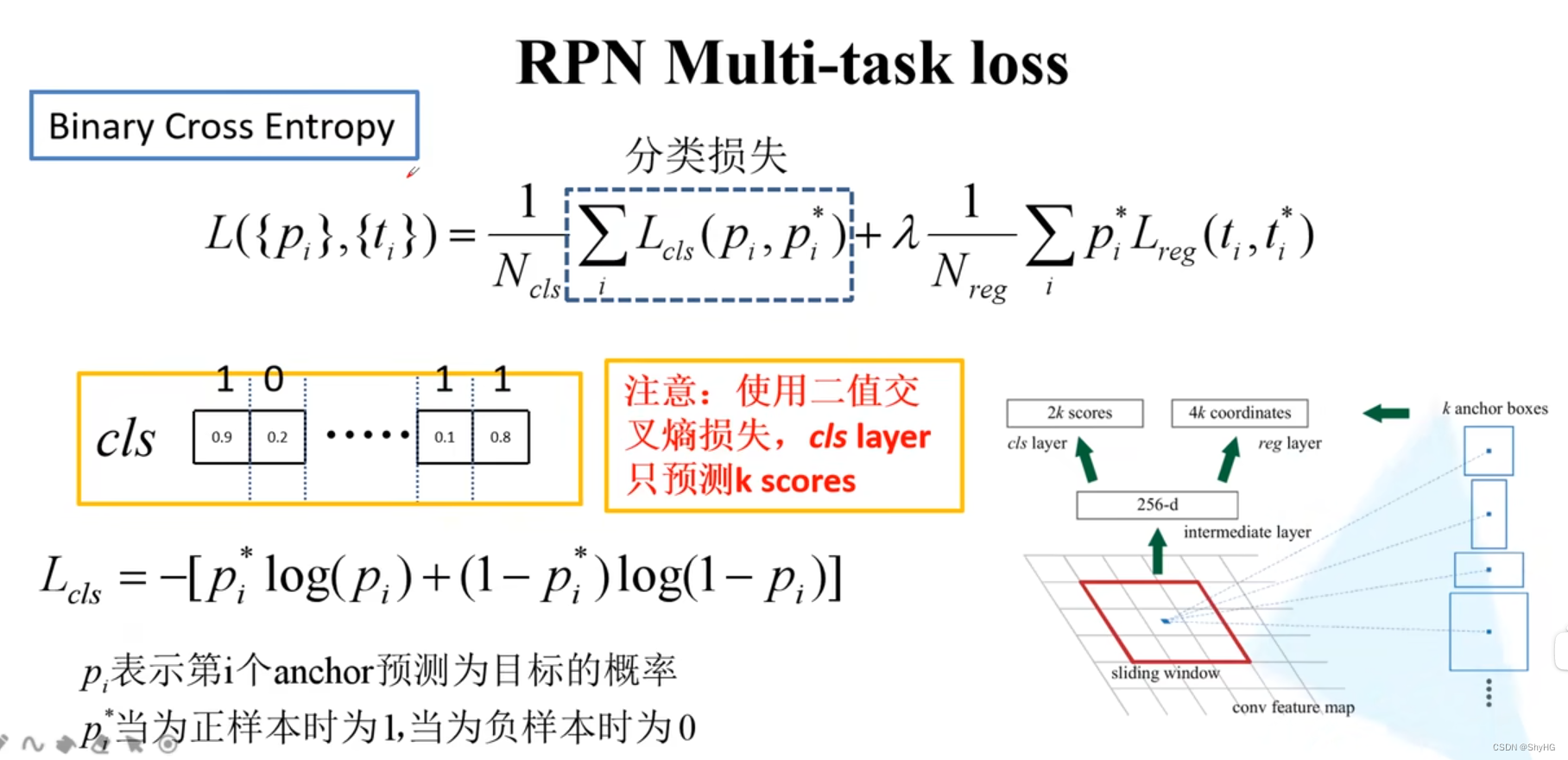
- RPN Loss计算,由分类损失和边界框回归损失两部分组成

- 分类损失,是一个sofrmax cross entropy
- 举例:第一个位置的损失 L c l s = − l o g ( 0.9 ) L_{cls}=-log(0.9) Lcls=−log(0.9)第二个位置的损失是 L c l s = − l o g ( 0.2 ) L_{cls}=-log(0.2) Lcls=−log(0.2),图中的标签可以onehot为[1,0],[0,1]…

- pytorch中的实现采用下面这个版本,是下图中的实现方法,分类损失采用二值交叉熵
- 使用sigmoid输出K个值,而不是上图中的2K,同样计算一下,第一个位置为 L c l s = − [ l o g ( 0.9 + ( 1 − 1 ) ∗ l o g ( 1 − 0.9 ) ] L_{cls}=-[log(0.9+(1-1)*log(1-0.9)] Lcls=−[log(0.9+(1−1)∗log(1−0.9)],第二个位置为 L c l s = − [ 0 ∗ l o g ( 0.2 ) + ( 1 − 0 ) l o g ( 1 − 0.2 ] ) L_{cls}=-[0*log(0.2)+(1-0)log(1-0.2]) Lcls=−[0∗log(0.2)+(1−0)log(1−0.2])
- 边界框回归损失,和Fast RCNN中的方法基本一样,使用 s m o o t h L 1 smooth_{L1} smoothL1损失函数,表达式如下图
- 仍然是预测4个参数,经过转换到最终的位置和宽高

- Faster RCNN训练方法如下
- 原论文中采用分布的方式来训练,训练RPN->训练Fast RCNN->微调RPN->微调Faster RCNN
- 在最终的方法中可以同时开始训练RPN和Faster RCNN,即联合训练

风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结