您现在的位置是:首页 >技术教程 >【C++】 哈希 (上)网站首页技术教程
【C++】 哈希 (上)
文章目录
1. 哈希概念
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立
一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置
取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称
为哈希表(Hash Table)(或者称散列表)
2. 哈希表
key跟存储位置建立映射(关联)关系
直接定址法(常用)

每一个值都有一个唯一位置
特点:适用于范围比较集中的数据
除留余数法(常用)
特点:范围不集中,分布分散
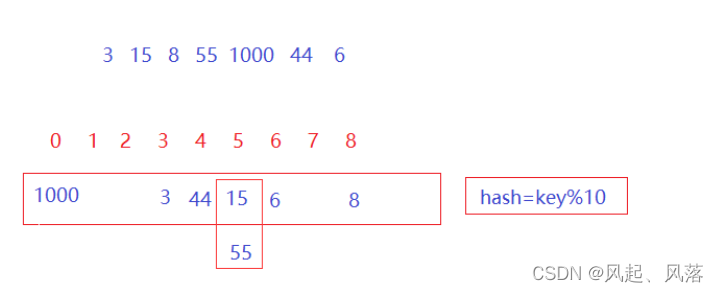
当前数据非常分散,虽然最大值已经达到1000,但是空间使用效率太低,所以不应该开1000个空间储存
所以想要把分散的数据,映射到固定的空间中
key值跟存储位置的关系,是模出来的
不同的值有可能映射到相同的位置 即哈希冲突
如55与15取模后的值都为5
解决哈希冲突方法1 ——闭散列
闭散列又称 开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明哈希表中必然还有空位置,则可以把key存放到冲突位置中的下一个位置去
如何寻找下一个位置?
线性探测
若有两个取模相同的值,则将先进来的占住当前取模位置,后进来的向后探测,若有空位置则放入

因为是先将2取模,所以2占住了映射2的位置,而当将102取模时,由于位置被2占住,所以向后寻找空位置,即在映射4的位置
hashi=key%len
len代表 表的长度
若当前位置已经被占住,hashi+i (i>=0)
i从0开始,不断增加直到找到一个没有占住的位置,超过该表的长度
3. 闭散列的实现
当使用除留余数法解决问题时
不同的值映射在相同的位置,即哈希冲突/哈希碰撞
使用线性探测处理,依次找后面位置存储 hashi + i (1,2,3,4)
如何处理删除数据?

假设要删除33,因为33取余后为3,所以先去位置为3的地方去找,没有找到,则继续向后寻找
寻找到空才结束

假设把33直接删除,当再次查找13时,由于提前遇到空,则直接结束
所以找到后,并不能直接删除,因为会影响查找
设置三种状态: 空、存在、删除
定义数据结构

需要使用枚举来表示三种状态 删除 存在 空
表示状态的state 也应该默认设为空,不然有可能造成 映射位置 没有数据但是 状态为存在的情况
insert
hashi=key%len
len代表 表的长度
若当前位置已经被占住,hashi+i (i>=0)
len为 _tables.size() 还是 _tables.capacity()?

假设将hashi的大小设为capacity
若当前位置为空,则将值填入进去,并且将状态设置为存在,会造成越界
在vector中 operator[] 会做越界检查,下标是否小于size

无法访问10后面的数据的,会造成越界
len为_tables.size()

线性探测


若从3位置开始,则+7时,绕过去导致达到0位置处,所以需要将index%size,从而达到0位置处

若当前位置存在,则继续向后走,若遇到空或者删除状态,则停下来填入数据,并将其设置为存在状态,存储的数据个数+1
负载因子
哈希表冲突越多,效率越低
若表中位置都满了,就需要扩容 ,提出负载因子的概念
负载因子 = 填入表的元素个数 / 表的长度
表示 表储存数量的百分比
填入表的元素个数 越大,表示冲突的可能性越大,
填入表的元素个数 越小,表示冲突的可能性越小
所以在开放定址法时,应该控制在0.7-0.8以下,超过就会扩容
扩容

需要注意的是 整形 除以整形 不存在小数

可以选择将其分子扩大10倍,则除出来的结果 为整数

表为空没有处理,无法扩容
size的大小没有变化,改变的caoacity的大小
但是增加的capacity的空间是不能被访问到的



size刚开始时为10,通过扩容size变为20
再次寻找13时,13%20 ==13 , 而13所在位置是4 ,所以是找不到的
说明当前扩容方法是不可以的
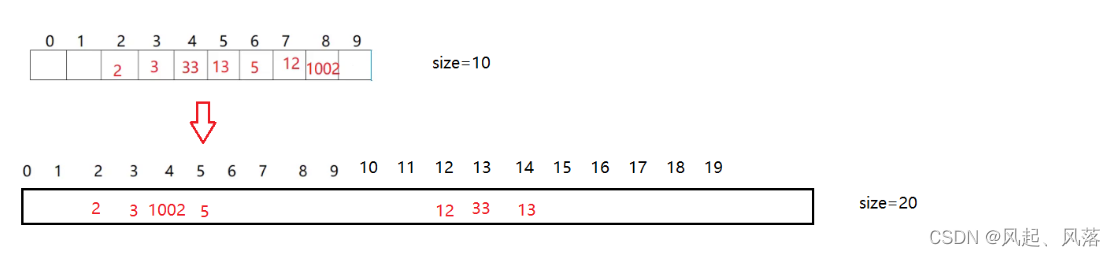
开辟一块新的空间,将原来空间内的数据都重新计算在新空间的映射位置
映射关系变了
原来冲突的值可能不冲突了
原来不冲突的值可能冲突了

创建newht,将其中的_tables的size进行扩容
通过 复用insert的方式,完成对新表的映射
交换旧表与newht的_tables ,以达到更新数据的目的
Find

若当前位置的状态为存在或者删除,则继续找, 遇见空 就结束
若在循环中找到了,则返回对应位置的地址,若没找到则返回nullptr
虽然把要删除的数据的状态改为DELETE,但是数据本身还是在的
所以Find还是可以找到的
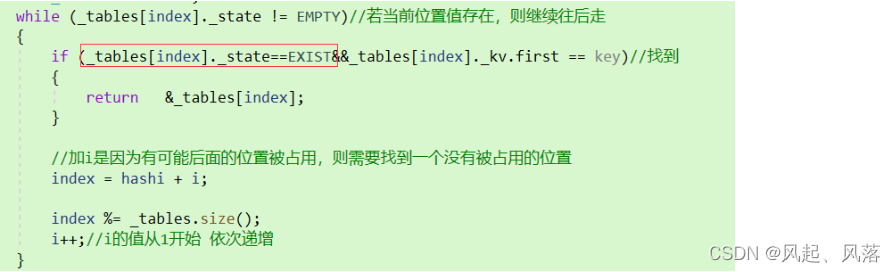
所以只有当前位置的数据状态为EXIST时并且当前位置的数据等于key值,才返回
Erase
 通过Find寻找要删除的数据,若找到了,则将其状态改为DELETE 将其数据个数减1 并返回true ,若没有找到,则返回false
通过Find寻找要删除的数据,若找到了,则将其状态改为DELETE 将其数据个数减1 并返回true ,若没有找到,则返回false
完整代码
#pragma once
#include<vector>
#include<iostream>
using namespace std;
enum State //表示三种状态
{
EMPTY, //空
EXIST,//存在
DELETE//删除
};
template<class K,class V>
struct HashData
{
pair<K, V>_kv;//对应的KV 数据
State _state=EMPTY;//表示状态
};
template<class K,class V>
class HashTable
{
public:
bool insert(const pair<K, V>& kv) //插入
{
//若数据已经有了,就不要插入了
if (Find(kv.first))
{
return false;
}
//负载因子超过0.7就扩容
if (_tables.size()==0 || _n * 10 / _tables.size() >= 7)
{
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
HashTable<K, V> newht;
newht._tables.resize(newsize); //将newht中的_tables 进行扩容
//遍历旧表,重新映射到新表
for (auto & data : _tables)
{
newht.insert(data._kv);//将旧表数据进行插入newht中
}
//将_tables 更新为newht中的数据
_tables.swap(newht._tables);
}
//key值%当前表的长度
size_t hashi = kv.first % _tables.size();
//线性探测
size_t i = 1;
size_t index = hashi;
while (_tables[index]._state == EXIST)//若当前位置值存在,则继续往后走
{
//加i是因为有可能后面的位置被占用,则需要找到一个没有被占用的位置
index = hashi + i;
//为了针对绕过去的情况
index %= _tables.size();
i++;//i的值从1开始 依次递增
}
_tables[index]._kv = kv;//填入数据
_tables[index]._state = EXIST;//设置为存在状态
_n++;
return true;
}
HashData<K, V>* Find(const K& key)//查找
{
if (_tables.size() == 0)
{
return false;
}
size_t hashi = key % _tables.size();
//线性探测
size_t i = 1;
size_t index = hashi;
while (_tables[index]._state != EMPTY)
{
if (_tables[index]._state==EXIST&&_tables[index]._kv.first == key)//找到
{
return &_tables[index];
}
//加i是因为有可能后面的位置被占用,则需要找到一个没有被占用的位置
index = hashi + i;
index %= _tables.size();
i++;//i的值从1开始 依次递增
//表里全是删除/存在状态的数据
if (index == hashi)
{
break;
}
}
return nullptr;
}
bool Erase(const K& key)
{
HashData<K, V>* ret = Find(key);
if (ret)
{
ret->_state == DELETE;
--_n;
return true;
}
else
{
return false;
}
}
private:
vector<HashData<K,V>> _tables;
size_t _n = 0; // 存储的数据个数
};
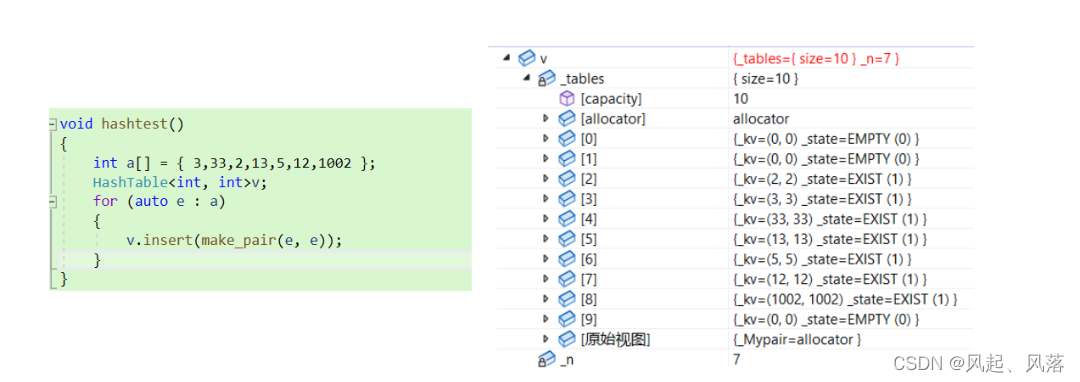
void hashtest()
{
int a[] = { 3,33,2,13,5,12,1002 };
HashTable<int, int>v;
for (auto e : a)
{
v.insert(make_pair(e, e));
}
}





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结