您现在的位置是:首页 >其他 >Redis分片集群网站首页其他
Redis分片集群
目录
搭建分片集群
主从(一个主节点、多个子节点,读写分离)和哨兵(解决主节点宕机问题)可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
海量数据存储问题
高并发写的问题
使用分片集群可以解决上述问题,分片集群特征:
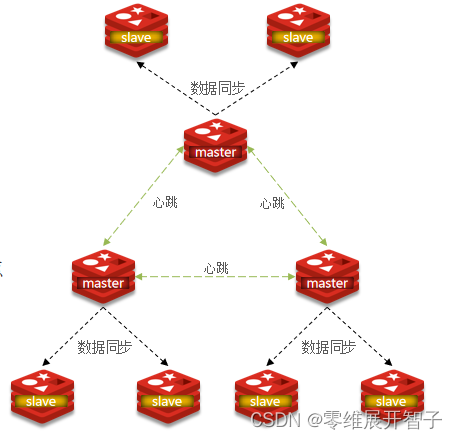
集群中有多个master,每个master保存不同数据
每个master都可以有多个slave节点
master之间通过ping监测彼此健康状态
客户端请求可以访问集群任意节点,最终都会被转发到正确节点
散列插槽
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到。
数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分
key中不包含“{}”,整个key都是有效部分
例如:key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值。
如何将同一类数据固定的保存在同一个Redis实例?
这一类数据使用相同的有效部分,例如key都以{typeId}为前缀
集群伸缩
redis-cli --cluster提供了很多操作集群的命令,可以通过下面方式查看:

故障转移
当集群中有一个master宕机会发生什么呢?
首先是该实例与其它实例失去连接
然后是疑似宕机
最后是确定下线,自动提升一个slave为新的master
数据迁移
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移。其流程如下:
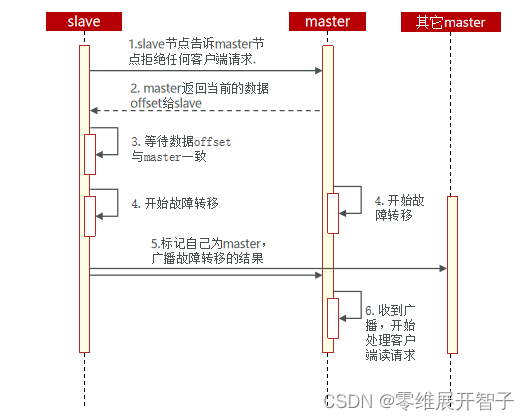
手动的Failover支持三种不同模式:
缺省:默认的流程,如图1~6歩
force:省略了对offset的一致性校验
takeover:直接执行第5歩,忽略数据一致性、忽略master状态和其它master的意见
RedisTemplate访问分片集群
RedisTemplate底层同样基于lettuce实现了分片集群的支持,而使用的步骤与哨兵模式基本一致:
1、引入redis的starter依赖(你一定引入过了,但是我还是要说一下)
2、配置分片集群地址
spring:
redis:
cluster:
nodes: # 指定分片集群的每一个节点信息
- 192.168.150.101:7001
- 192.168.150.101:7002
- 192.168.150.101:7003
- 192.168.150.101:8001
- 192.168.150.101:8002
- 192.168.150.101:8003
ip+端口号记得改成你自己的
3、配置读写分离 和哨兵设置一样
话说回来,这个redis的分片集群和elasticsearch的分片集群好像吖






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结