您现在的位置是:首页 >技术杂谈 >ResNet (深度残差网络)网站首页技术杂谈
ResNet (深度残差网络)
ResNet 算法概述
解决的核心问题:网络的退化现象
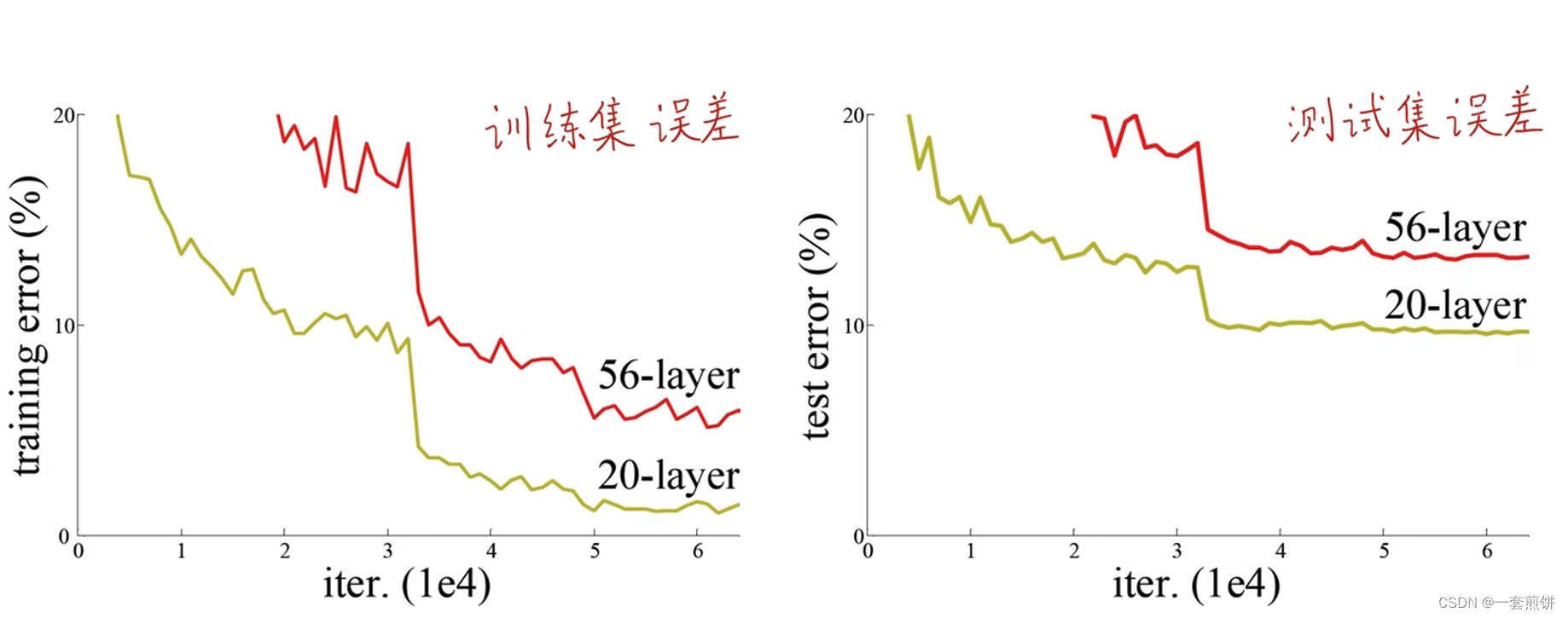
网络层数在变深之后,性能不如浅层时候的性能 。注意:网络退化既不是梯度消失也不是梯度爆炸。
那是如何解决退化现象的呢?引入残差模块
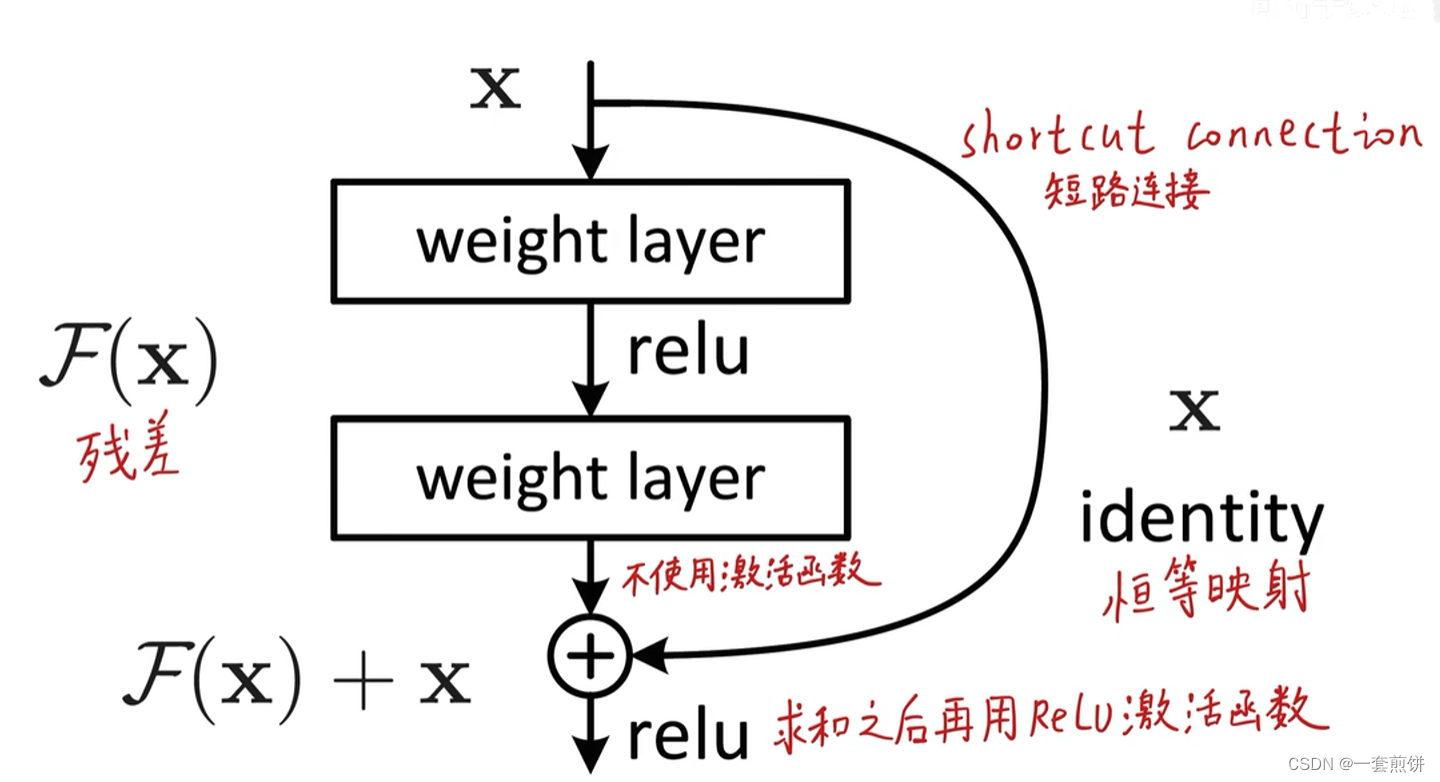
把模型的输入分成两条路:右边 的支路 为跳跃链接,将输入进行恒等映射。左边的结构为两层神经网络,这个模块的含义是不需要输入去拟合底层真正的分布,而是在输入的基础上进行哪些修改,只要拟合残差就行。(加了残差模块只会比原来的更好)
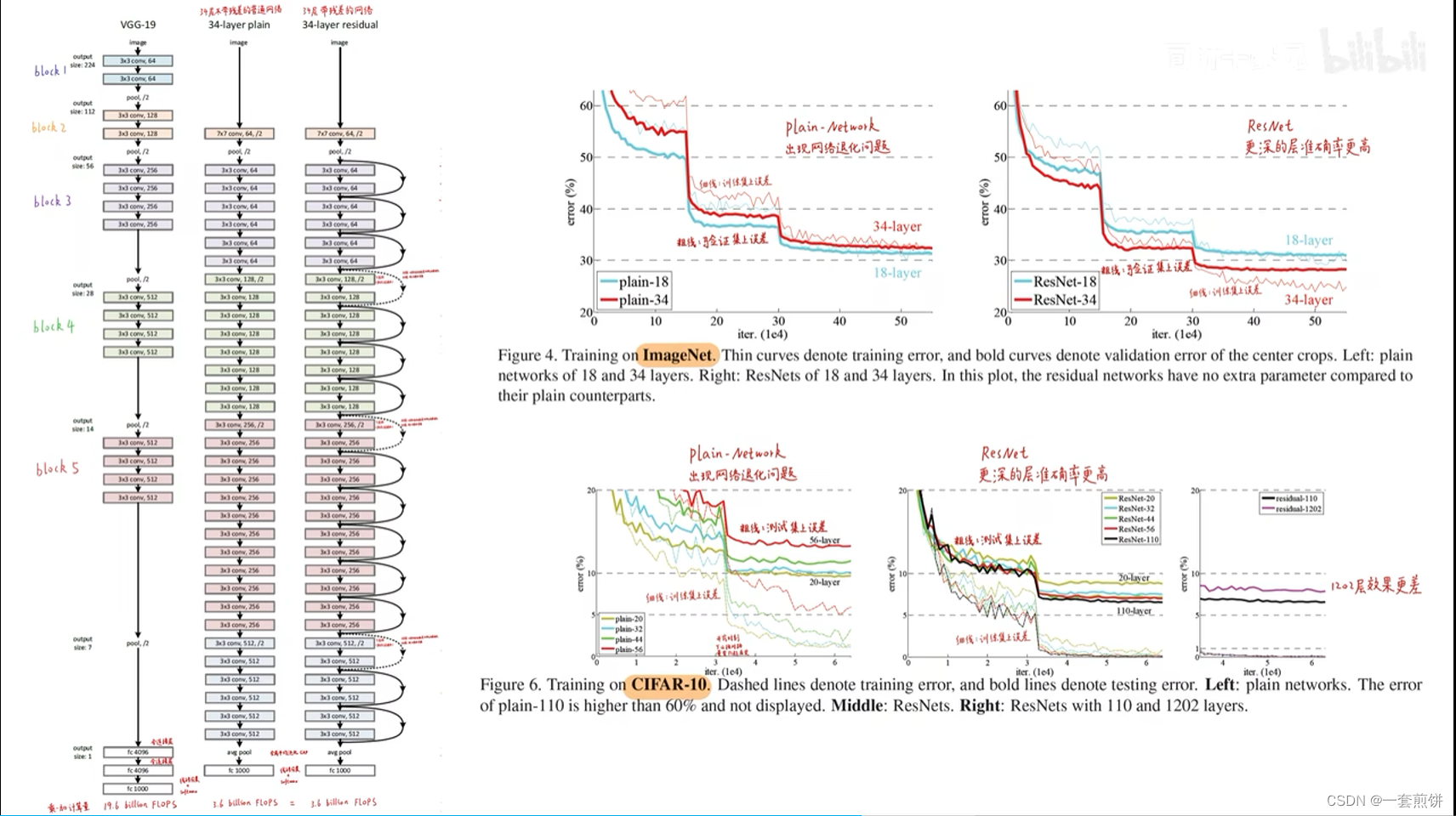
真正的残差模块是很多层堆叠起来的。如上图所示
残差:真实值和预测值之间的偏差
问题:能不能无限层数的进行对堆叠?
论文中进行了对比试验,堆叠了1202层。用CIFAR-10数据集,最后呈现的效果是出现过拟合,作者将其原因归结为该数据集过小。(好比是中科院院士去做小学数学题)如下图所示

下图是有一个普通的线性网络,输入x想拟合成H(x)的分布,之前的网络是依据堆叠的网络去进行拟合。
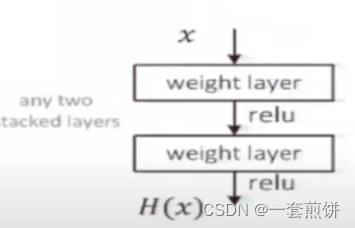
但是残差网络是在现象网络的基础上加了一个分支,如下图所示:

上面的这个网络不再是x去拟合H(x),而是x拟合F(x),假如输入足够好,那残差就为0 ,如果输入不是很理想,那残差可以在x的基础上进行优化,也就是堆叠的网络只负责在x的基础上进行优化即可。最后进行残差和输入逐元素相加()。
如果两者的元素结构不一样怎么办?在论文中提出了三种解决方法:
(1)在下采样时,对多出来的分支通道用0做填充(里面的元素全部为0)
(2)在下采样时,对分支通道做1×1的卷积,把维度调成成和残差块一样.
(3)不管是在下采样还是普通卷积操作的时候,在分支通道里做1×1卷积
最后证明,不管是卷积还是padding,对分支通道不做任何处理时最好的。

所有的卷积块是3×3的,下采样的步长为2 ,不用pooling。分支路径是没有要学习的参数的,所以ResNet要学习的参数两和计算量和原来的线性网络是没有区别的。
在数据集CIFAR-10上,无残差模块的网络随着层数的加深,训练效果相对浅层的效果差,但是加了残差模块的随着网络层数的加深,训练效果相对于浅层的效果要好很多,收敛速度会更快,在优化上没有什么困难。如下图所示:
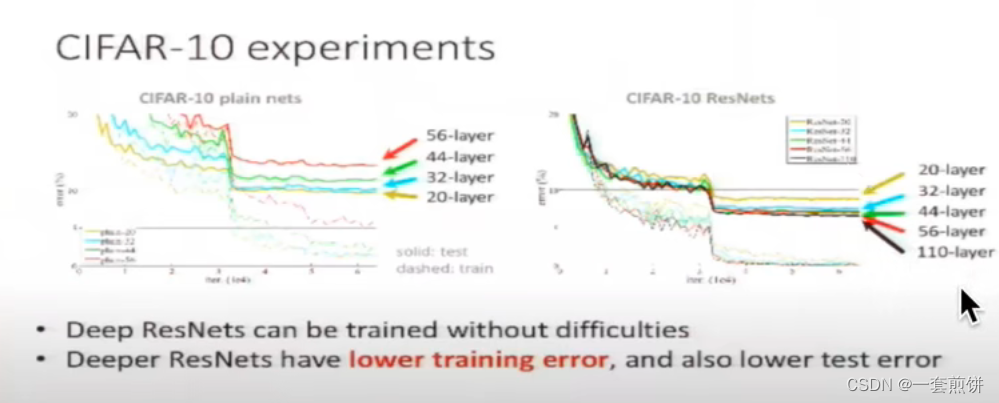

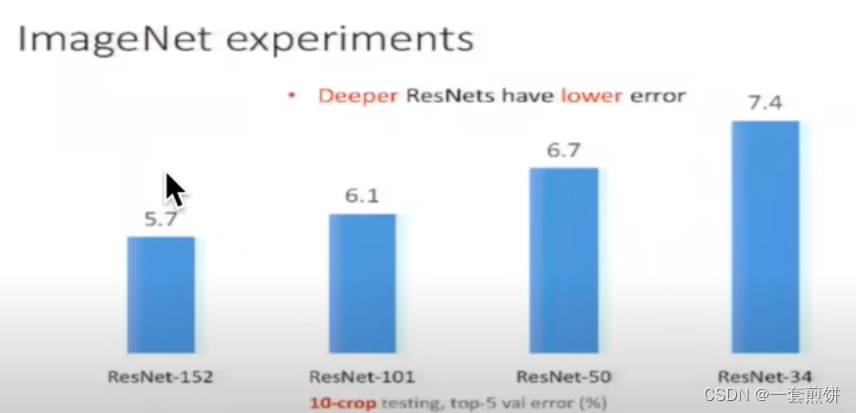
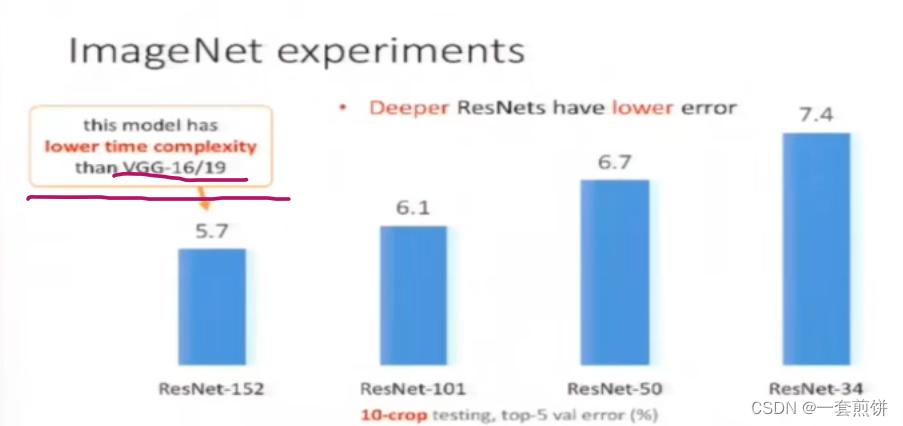
在论文中实验了不同层数的ResNet ,从下图可以看出模型越深,误差越小
为什么ResNet能解决网络退化,背后的机理是什么?
角度1:

补充上述: 恒等映射的梯度是1,意味着把深层的出入到底层,把底层的传入到深层,在传统的线性网络中,特别是用sigmoid函数,就会出现中间商赚差价,梯度逐渐变小,最后得到的梯度基本为0。
角度2:

补充上述:第一条,前面的模型与标签值之差。如下图的解释:

上图中左右两边的解释是一样的,左图所示:第一个分类器开始进行分类,将蓝色球和红色球划分出来,但是经过分类器1最后得到的结果是有一些分类出现了错误。及时这样的分类结果不是很理想,可以用分类器2来修正上一个分类器1的分类错误,也就是将分类出错的球变大,然后在进行分类,但是这个2也会出错,那将错误的用分类器3进行修正拟合,最终将这几个模型放在一起,那么弱分类器就变成了强分类器,并且能够拟合出分线性的决策边界。
所以角度2中的第一条:残差网络的分支也是在修正上一层的误差,如果上一层的输出足够好,那么残差就为0.如果不够好就去修正这个残差。
第二条:长短时记忆网络他是一种循环网络,用来处理序列数据的

遗忘门:最上面的横线就是遗忘门,贯穿了每一个模块,下面的一些是残差。
Relu激活函数也是一种残差。重要的时候输出,不重要的时候就抹平。
角度3:

补充上述:恒等映射,意思是输入和输出是一样的函数很难用传统的线性模型来实现。
角度4:

角度5:
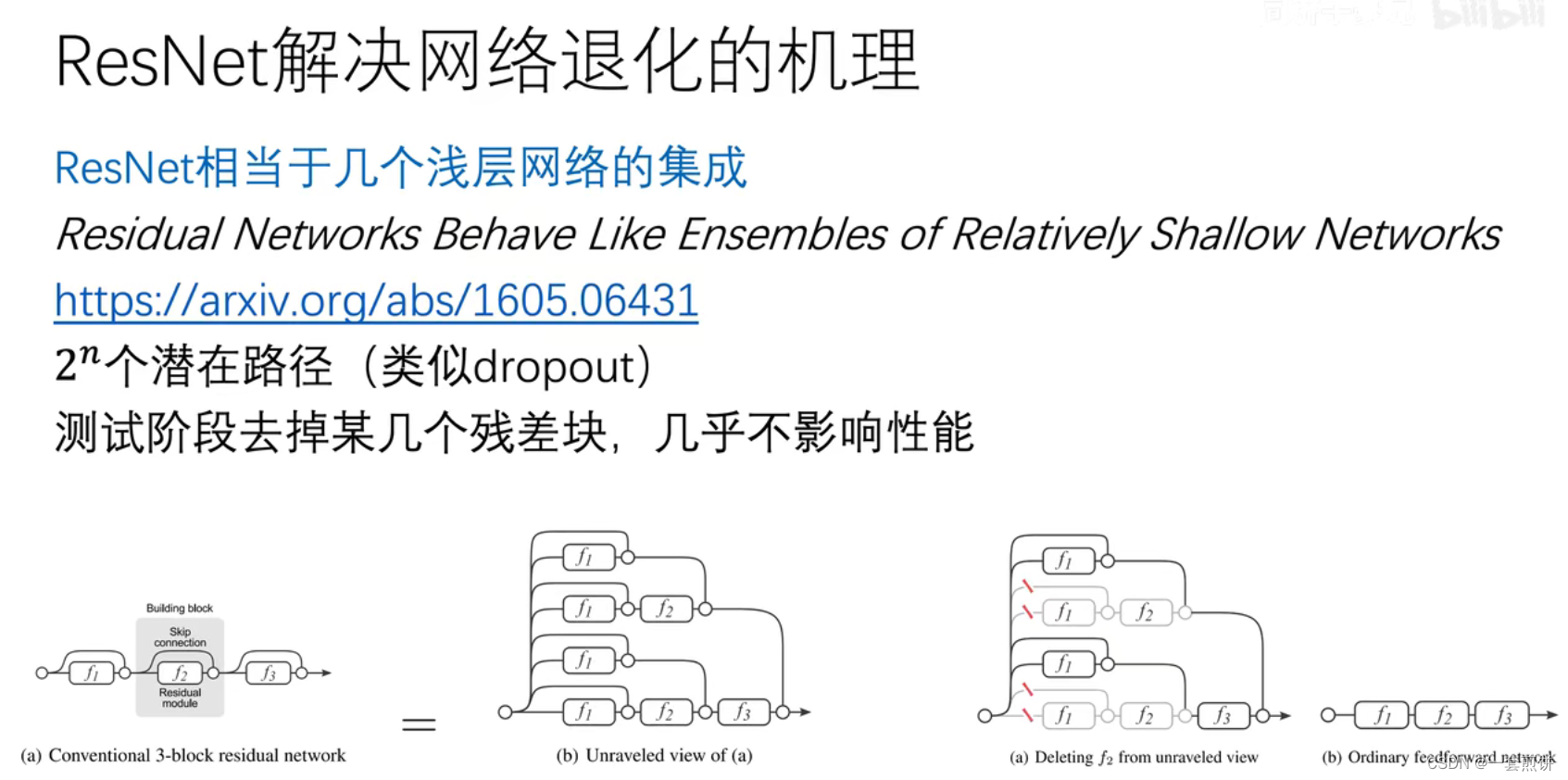
角度6:


Deep Residual Learning for Image Recognition—论文精读

视频链接:ResNet论文精读:Deep Residual Learning for Image Recognition_哔哩哔哩_bilibili






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结