您现在的位置是:首页 >技术交流 >第一章 认识网络爬虫网站首页技术交流
第一章 认识网络爬虫
第一章 认识网络爬虫
1.1 什么是网络爬虫
网络爬虫: 一种按规则,自动请求网站并提取网页数据的程序或脚本
网络爬虫分类(按照系统结构和技术划分):
1.通用网络爬虫
2.聚焦网络爬虫
3.增量式网络爬虫
4.深层网络爬虫
1.通用网络爬虫
通用网络爬虫:访问全互联网资源
主要用于将互联网中的网页下载到本地,形成一个互联网网页的备份.这类爬虫对速度和存储空间要求高,对抓取网页顺序要求不高
2.聚焦网络爬虫
聚焦网络爬虫:选择性的访问那些与目标主题相关的网页
只访问与目标主题相关的网页,在一定程度上节省了网络资源
3.增量式网络爬虫
增量式网络爬虫:只抓取新产生或发生变化的网页
只抓新的和变化的网页,不重复抓不变的网页,减少访问时间和存储空间的消耗,但是实现难度大,技术要求高
4.深层网络爬虫
深层网络爬虫:抓取深层网页
抓取的网页层数较深,实现难度大
扩展:网页按存在方式划分,分为表层和深层.表层网页可直接通过超链接访问, 深层网页不能通过链接访问,需要提交关键字,比如注册后的网页
实际运用中网络爬虫系统通常由以上四种爬虫结合使用
1.2 网络爬虫的应用场景
大多数依赖数据支撑的应用场景都需要爬虫,包括搜索引擎, 舆情分析与监测,聚合平台,出行类软件等
1.搜索引擎
谷歌,百度,必应等搜索引擎利用爬虫从互联网中采集海量数据
2.舆情分析与监测
政府或企业通过爬虫采集论坛评论,博客,新闻媒体,微博等的数据,发掘热点,并进行舆情控制和引导
3.聚合平台
聚合平台如返利网,慢慢买等运用爬虫对一些电商平台的商品信息进行采集,并放在自己的平台,横向对比,帮用户寻找实惠的商品价格
4.出行类软件
出行类软件,如飞猪,携程,去哪儿等 用爬虫访问官方售票网站刷新余票,有余票时通知用户付款买票.(官方售票网站不欢迎此行为,容易造成网站瘫痪)
1.3网络爬虫的合法性探究
爬虫的抓取行为经常会给网站增加压力,严重时可能影响对网站的正常访问,为了约束爬虫的恶意行为,网站加入反爬措施来阻止爬虫,同时,爬虫也研究了网站防爬的应对策略
1.3.1robots协议
为了维护网络环境,保证网站与爬虫之间的利益平衡,爬虫设计者及爱好者发布了行业规范---robots协议/爬虫协议,网站管理员在网站根目录放一个符合robots协议的robots.txt文件,告知爬虫哪些数据可以爬,哪些数据禁止爬取.
当爬虫访问网站时,先检查根目录是否存在robots.txt文件,如果存在,就按照文件内容爬取相应内容,如果不存在,则可以爬取所有没有口令保护的页面
在网站链接后面加robots.txt即可查看robots.txt文件.比如访问豆瓣获取robots文件 https://www.douban.com/robots.txt 内容如下
User-agent: * Disallow: /subject_search Disallow: /amazon_search Disallow: /search Disallow: /group/search Disallow: /event/search Disallow: /celebrities/search Disallow: /location/drama/search Disallow: /forum/ Disallow: /new_subject Disallow: /service/iframe Disallow: /j/ Disallow: /link2/ Disallow: /recommend/ Disallow: /doubanapp/card Disallow: /update/topic/ Disallow: /share/ Disallow: /people/*/collect Disallow: /people/*/wish Disallow: /people/*/all Disallow: /people/*/do Allow: /ads.txt Sitemap: https://www.douban.com/sitemap_index.xml Sitemap: https://www.douban.com/sitemap_updated_index.xml # Crawl-delay: 5 User-agent: Wandoujia Spider Disallow: / User-agent: Mediapartners-Google Disallow: /subject_search Disallow: /amazon_search Disallow: /search Disallow: /group/search Disallow: /event/search Disallow: /celebrities/search Disallow: /location/drama/search Disallow: /j/
robots.txt中通过空行分隔的语句组成一条记录,每条记录通常由User-agent开头,后面指定了爬虫名称,其中*针对所有爬虫,比如示例第一行(*只能出现一次).
User-agent下面的Disallow与Allow则分别指定该爬虫不被允许和允许爬取的目录.在整个robots.txt中至少一条Disallow.
Sitemap是网站地图的路径.主要说明网站更新时间,更新频率网址重要程度等信息
扩展:robots协议是君子协议,没有实际约束,对于某些不讲武德的爬虫来说,没有太大作用尽管robots没有强制约束力,但是我们也要遵守协议,违背协议可能会吃牢饭.
1.3.2防爬虫应对策略
尽管有robots协议约束爬虫,但总有很多爬虫不讲武德,经常发送多个请求重复访问网站,给网站造成很大压力.
因此网站管理员也会根据爬虫的特点,从来访客户端程序中选出爬虫,并采取防爬措施阻止爬虫访问.于此同时爬虫也采取一些应对策略继续访问网站.
常见应对策略包括添加User-Agent字段, 降低访问频率,设置代理服务器,识别验证码等
1.添加User-agent字段
浏览器访问网站时携带固定的User-agent(用户代理,用来描述浏览器类型/版本,操作系统/版本,浏览器插件,浏览器语言等信息),向网站表明身份
爬虫访问网站时也可以模拟浏览器行为,在请求时携带User-agent,将自己伪装成一个浏览器.如此可蒙混过关,避免被拒绝访问
2.降低访问频率
一个账户在短时间多次访问网站,可能被运维发现是爬虫,从而被加入黑名单禁止访问网站.爬虫可通过降低访问频率,减少被运维发现的风险.此方法会降低爬虫效率,为弥补这个不足,可适当调整操作,如爬一次页面休息几秒,或限制每天抓取的网页数量.
3.设置代理服务器
爬虫反复使用一个ip访问网站时,容易被网站识别身份后屏蔽,封禁.此时可通过在爬虫和web服务器(网站)之间设置代理服务器.爬虫先发请求给代理服务器,代理服务器再发给web服务器(网站).这时web服务器记录的就是代理服务器的ip.
4.识别验证码
有些网站监测某个客户端的ip访问过于频繁,会提供验证码,让客户登录验证.对于这种情况,爬虫除了输入账号密码,还要像实际登录一样,通过滑动,点击等,识别验证码.如此才能继续访问网站,由于验证码种类多,不同验证码通过不同的技术识别,具有一定技术难度.
1.4爬虫的工作原理和流程
1.4.1爬虫的工作原理
互联网中的多种爬虫尽管使用场景不同,但工作原理大同小异,下面介绍两种爬虫工作原理
1.通用网络爬虫工作原理
爬虫从一个或多个初始url开始,获取对应的网页数据,并不断从该网页数据获取新的url放入队列直到满足一定条件后停止.工作原理如下图
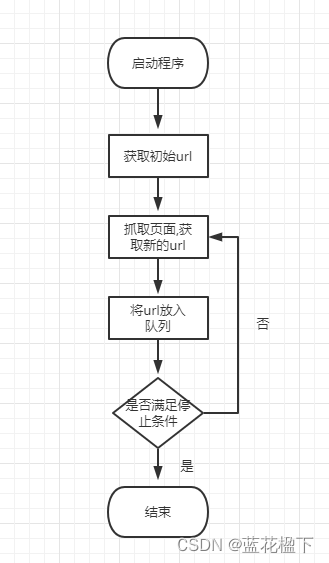
1.获取初始url:初始url是精心挑选的单个/多个url.可以由用户指定,也可以由待采集的初始网页指定
2.抓取页面,获取新的url:抓取初始url对应的网页,将网页存储到初始网页数据库,抓取的同时对网页进行解析,获取新的url
3.将新的url放入url队列
4.若爬虫满足设置的停止条件,就停止采集,若不满足,则继续抓取新的url对应的网页,循环执行.如果没有设置停止条件,爬虫会一直执行,直到没有采集到新的url
2.聚焦网络爬虫工作原理
聚焦网络会根据一定的算法对网页进行筛选,保留与主题相关的url舍弃与主题无关的url.其目的性更强.工作原理如下图
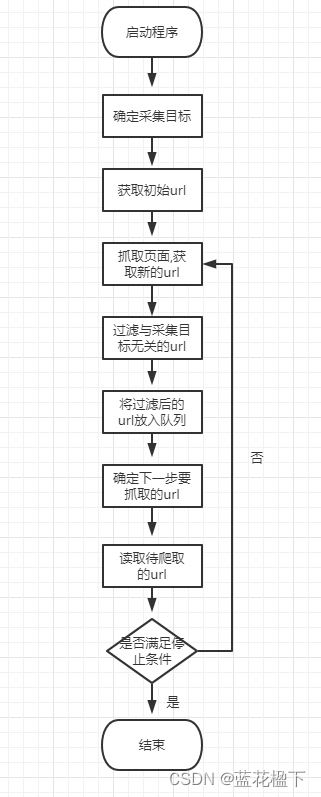
1.根据需求确定爬虫的采集目标,进行相关描述
2.获取初始url
3.根据初始url抓取网页,获取新的url
4.过滤掉与采集目标无关的url
5.将过滤后的url放入队列
6.根据抓取策略,确认url优先级.并确定下一步要抓取的url
7.把下一步要抓的url读取出来.准备根据url抓取新的网页
8.若满足停止条件或没有新的url,停止抓取,不满足停止条件则继续抓,一直循环
1.4.2爬虫爬取网页的流程
下面是爬虫爬取网页的流程图
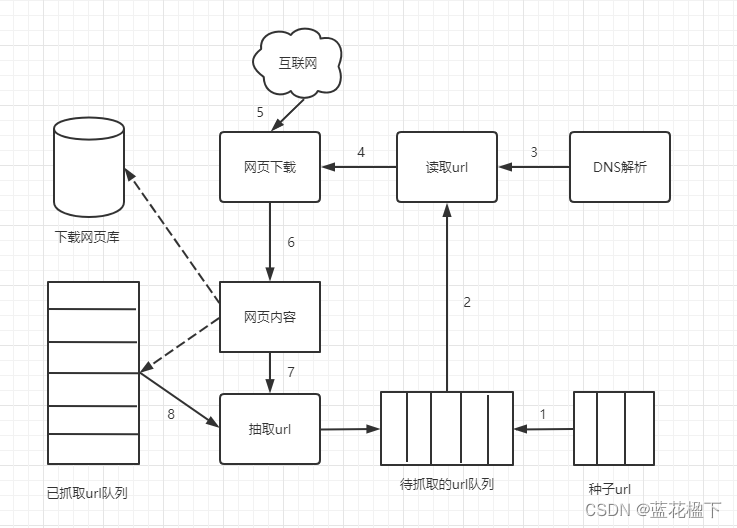
1.选择一些网页将网页的链接(url)作为种子url放入待抓取的url队列
2.从待抓取的url队列中依次读取url
3.通过DNS解析url,把url地址转换为ip
4.将服务器ip和网页的相对路径给网页下载器
5.下载器将网页内容下载至本地
6.将下载的网页存储到页面库,等待建立索引并等待后续处理.同时将下载过的ur放入已抓取队列
7.从刚下载的网页中抽取url
8.检查抽取的url是否在已抓取url队列,如果没有,放入待抓取队列
重复以上循环,直到抽取的url为空
1.5网络爬虫实现技术探究
1.5.1网络爬虫的实现技术
为满足用户快速采集数据,市面上出现一些可视化界面的爬虫工具.如八爪鱼采集器,火车头采集器等.除此之外也可以自己开发爬虫工具.目前开发爬虫的工具主要有php,go,c++,java, python,后文用python编写爬虫,所以单独介绍一下python
python在网络爬虫方向已经有完善的生态圈子,拥有较强的多线程处理能力,但网页解析能力不够强大
选择python的原因:
语法简洁
容易上手
开发效率高:爬虫的代码 需要根据不同的网站内容进行局部修改,非常适合python这样灵活的语言去实现
模块丰富:python有丰富的内置模块,第三方模块,以及成熟的框架,能够帮开发快速实现爬虫的基本功能.
1.5.2python实现网络爬虫的流程
互联网上虽然有千奇百怪的网页,但使用python开发爬虫的基本流程都是一样的.流程如下
1.抓取网页数据
根据url向网站发请求并获取数据,(类似于浏览器输入网址,获取页面内容)
2.解析网页数据
采用不同的解析方法在整个网页数据中提取出想要的数据
3.存储数据
将提取的数据存在在本地或数据库,方便后期对数据进行研究
本章小结:
爬虫的概念,应用场景,robots协议,防爬应对策略,爬虫工作原理,抓取网页的详细流程,爬虫的实现技术python,python实现爬虫的流程






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结