您现在的位置是:首页 >学无止境 >什么是栈,为什么函数式编程语言都离不开栈?网站首页学无止境
什么是栈,为什么函数式编程语言都离不开栈?
文章目录
一、什么是栈,什么是FILO
栈是一种具有特殊访问方式的存储空间,它的特殊性在于,最后进入这个空间的数据,最先出去,可以画图来描述一下这种操作方式。
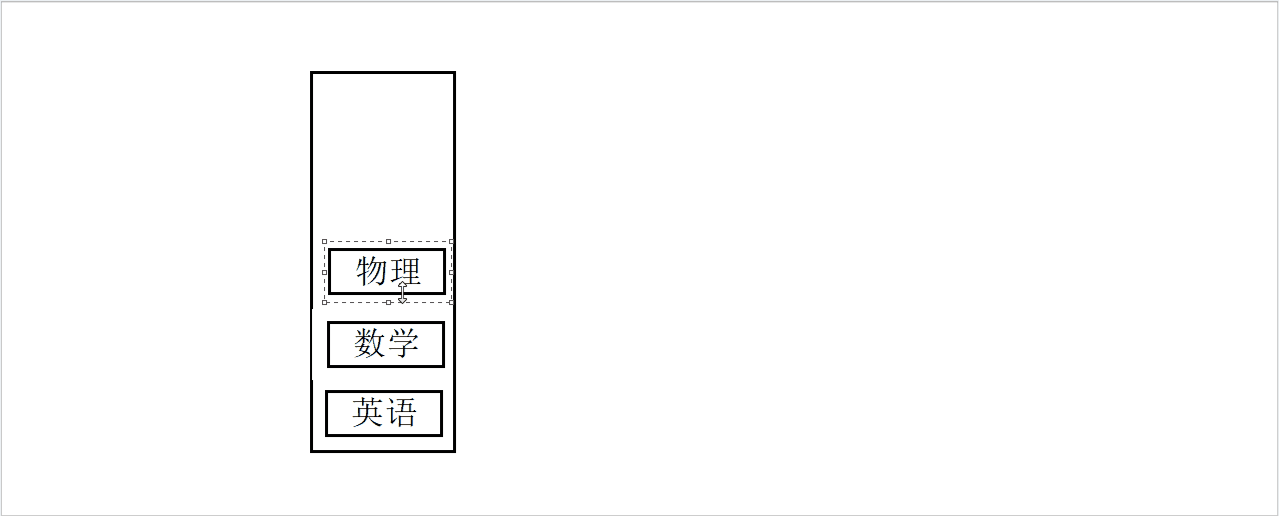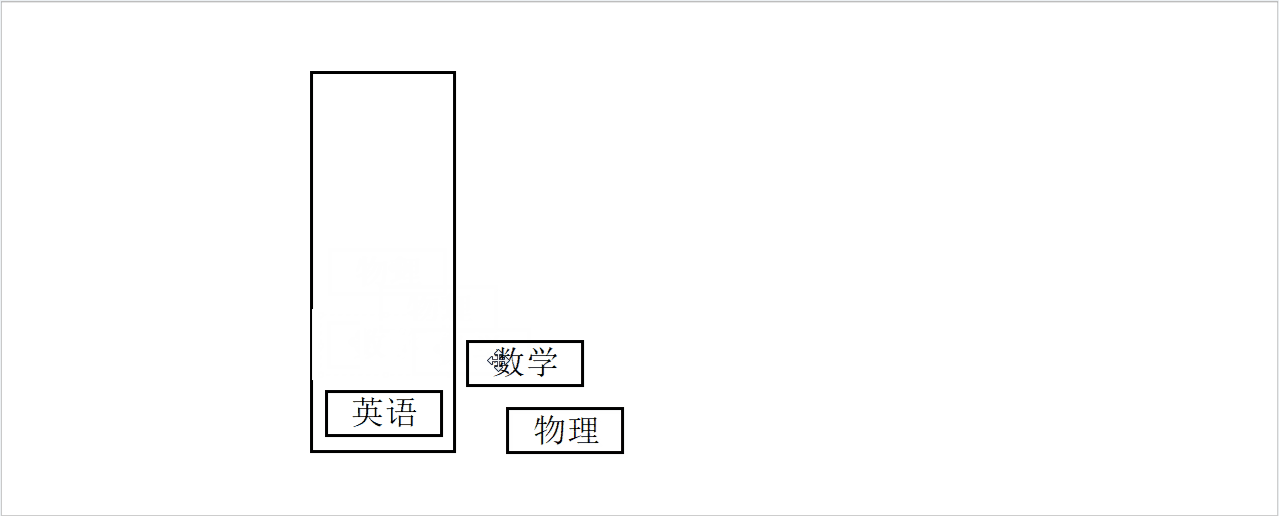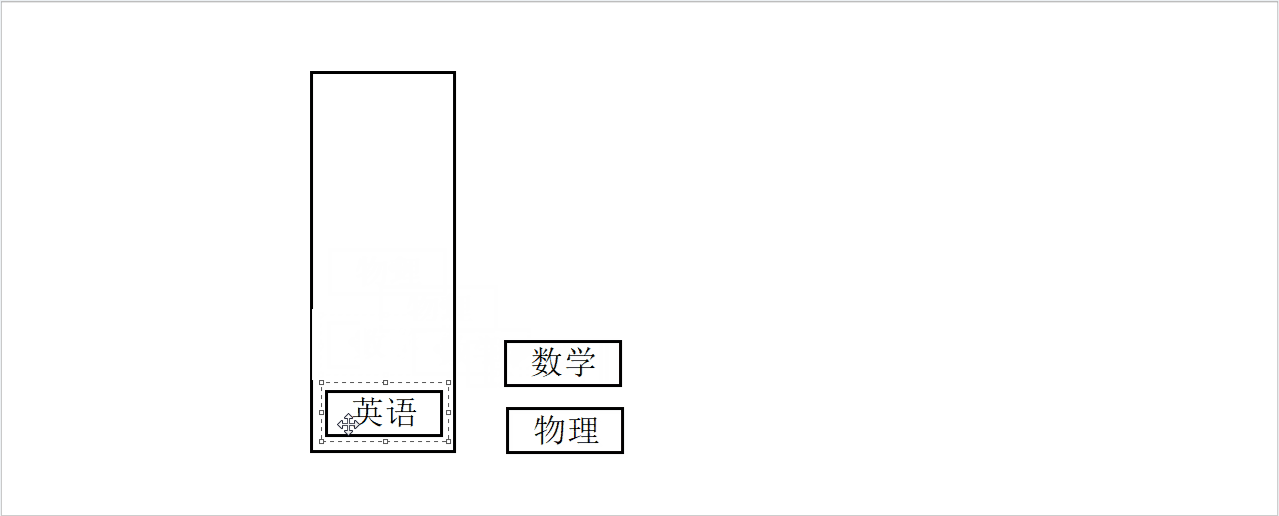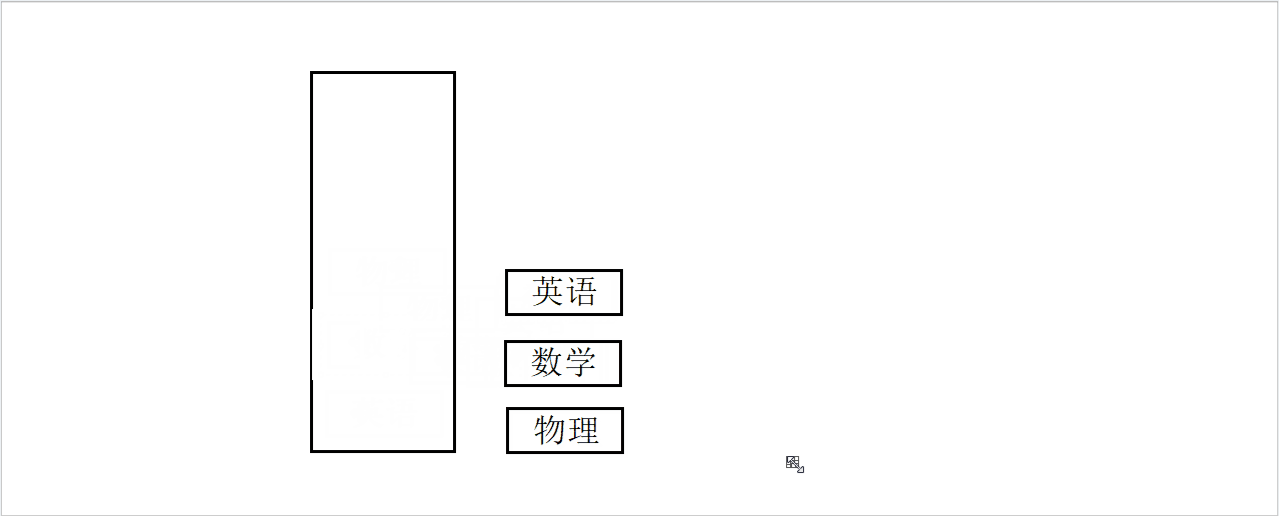
假设有一个盒子和三本书,依次将三本书他们放入盒子中。
入栈模拟图
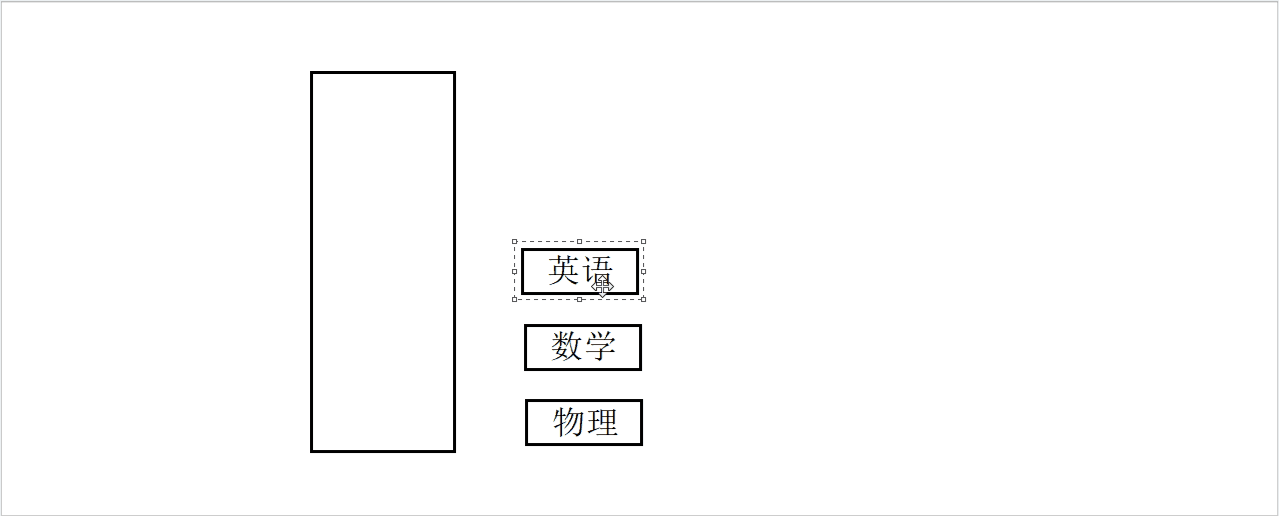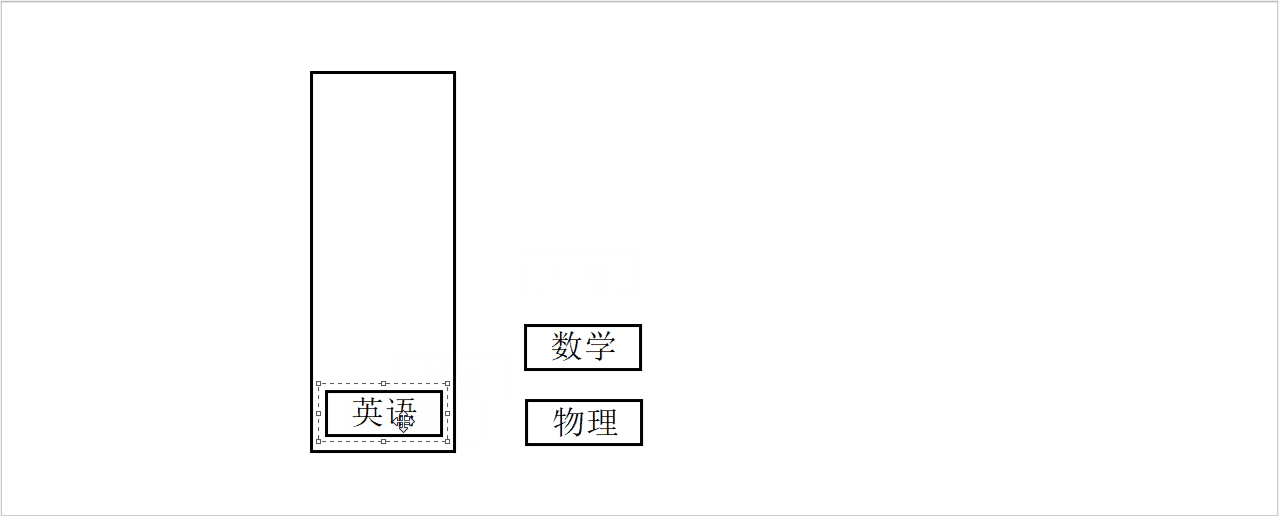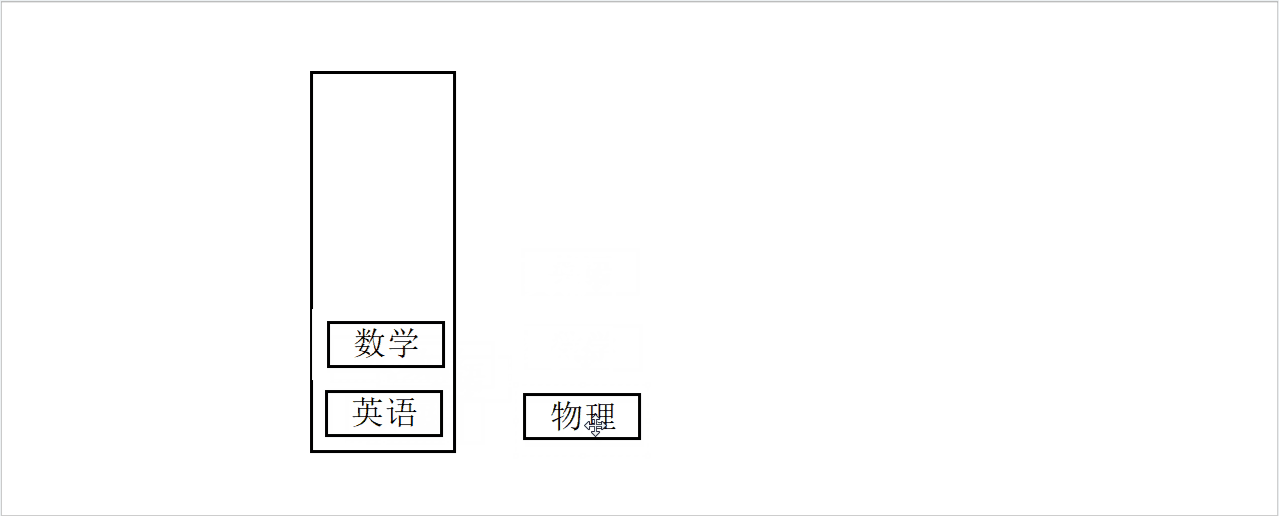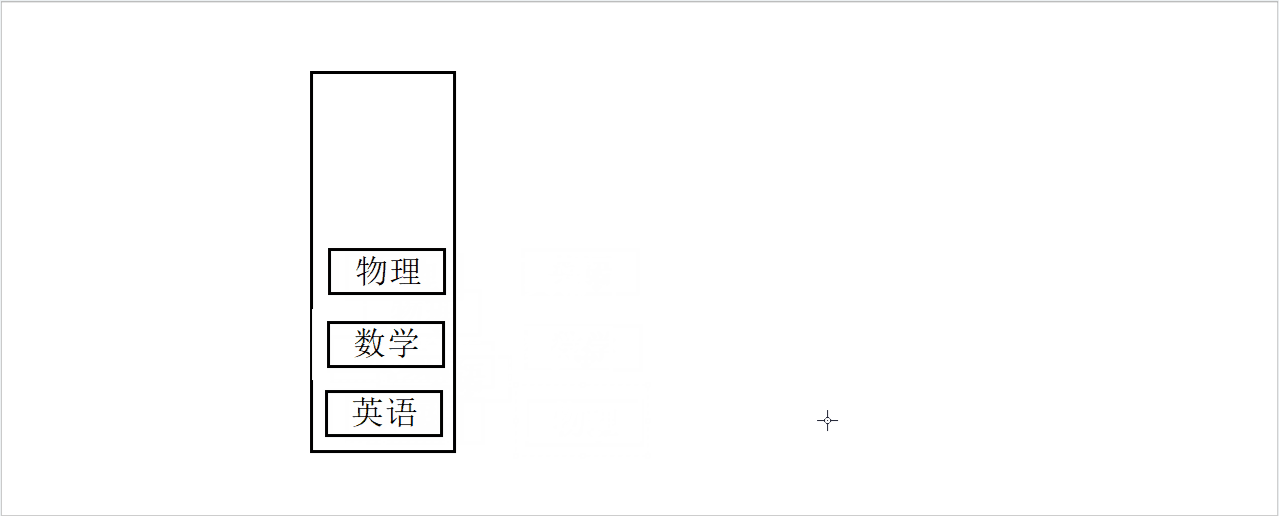
现在有一个问题,如果一次只能取一本,我们如何将书从盒子中取出来?
显然必须从盒子的最上边开始取,依次取出,和放入的顺序刚好相反。
出栈模拟图
从程序化的角度来讲,应该有一个标记,这个标记一直指示着盒子最上边的书。
如果说,上图中的盒子就是一个栈,我们可以看出栈的两个基本操作:入栈和出栈。入栈就是将一个新元素放到栈顶,出栈就是从栈顶取出一个元素,栈顶的元素总是最后入栈,需要出栈时,有最先被从栈中取出。栈的这种操作被称为:LIFO(last in first out),后进先出
二、栈的作用是什么,为什么编程语言函数调用都选择用栈?
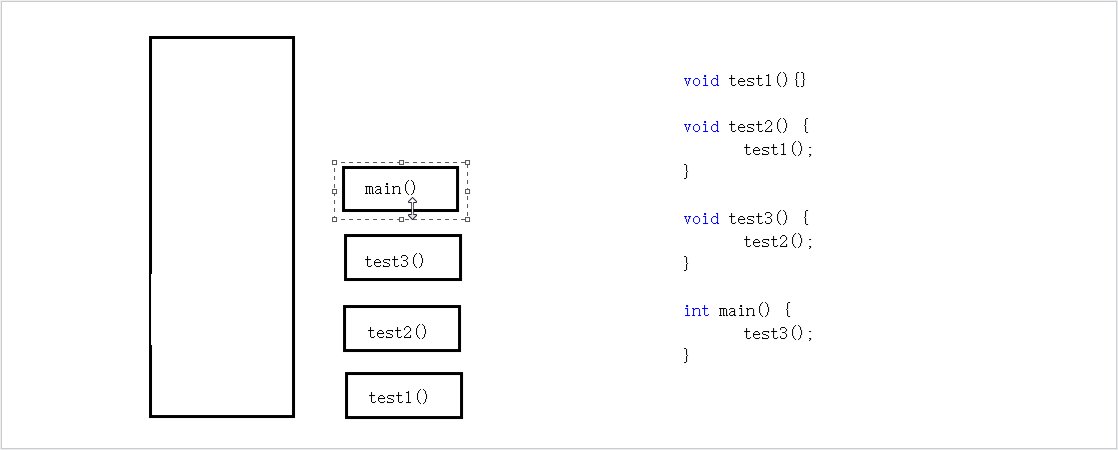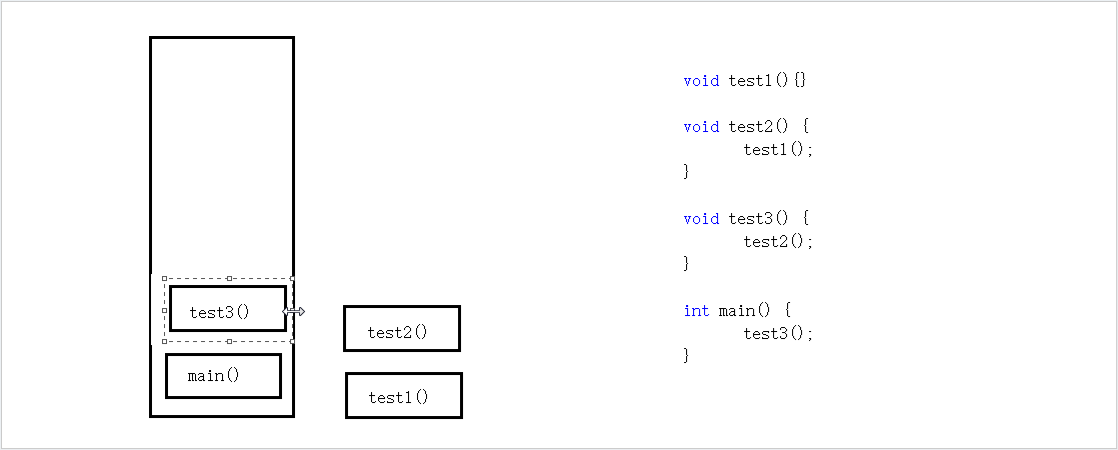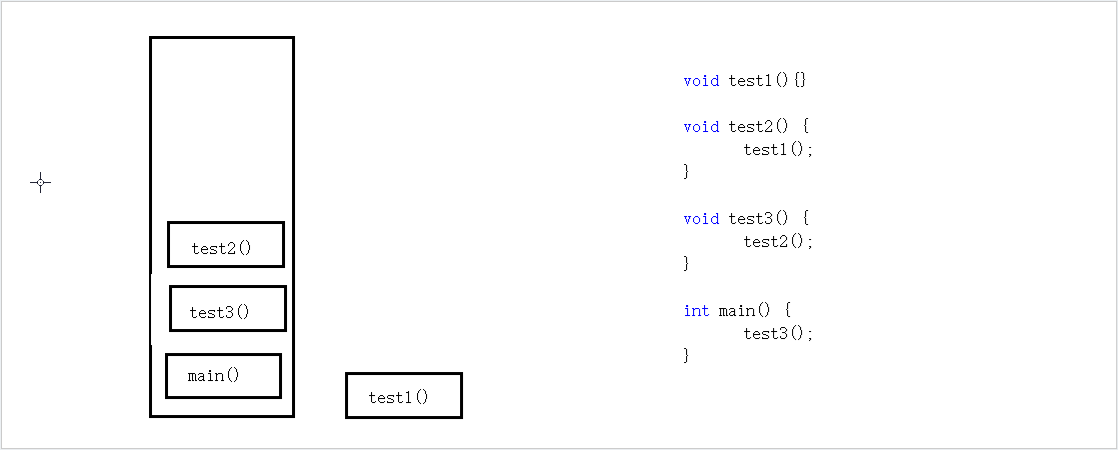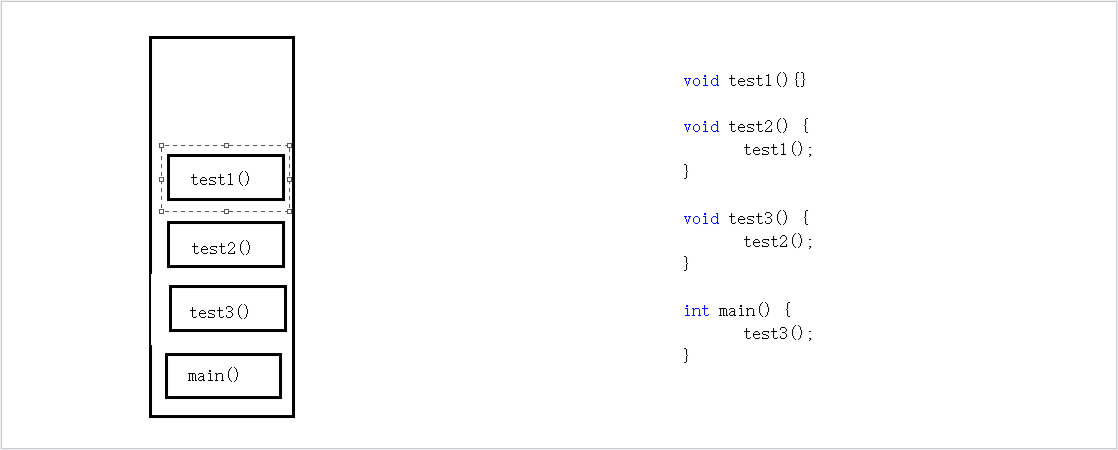
为何现如今所有的编程语言都会采用栈来进行函数调用?函数调用的状态之所以用栈来记录是因为这些数据的存活时间满足“先进后出”(FILO)顺序,而栈的基本操作正好就是支持这种顺序访问的。下面用一组程序举例。
void test1(){}
void test2() {
test1();
}
void test3() {
test2();
}
int main() {
test3();
}
这个程序运行的顺序为:main() ——》 test3() ——》 test2() ——》 test1() ——》 return from test1() ——》 return from test2() ——》 return from test3() ——》 return from test4().
可以看到,调用者的生命周期总是长于被调用者的生命周期,并且后者在前者之内。被调用者的数据总是后于调用者的,而其释放顺序总是先于调用者,所以正好可以满足LIFO顺序,选用栈这种数据结构来实现函数调用则是一种自然而然的选择。
三、使用C模拟实现解析栈
前面说过栈的两个基本操作,入栈和出栈,都只是对栈顶进行操作,栈可以用数组实现也可以用链表实现,这里讲解用数组实现,因为数组实现相对来说更优一些,数组实现在尾部插入数据代价比较小。
1.结构体的定义
由于各种操作都只在栈顶进行,选择定义一个top来记录栈顶的位置,为了节省空间选择定义一个capacity来记录最大长度,如果等于top的话进行扩容。
typedef int STDataType;
typedef struct StackNode {
STDataType* arr;
int capacity;
int top;
}STNode;
2.栈的创建及销毁
由于函数内有对参数指针的引用,加上assert预防程序崩溃,易于调试,top初始化为-1(也可以初始化为0,个人偏向初始化为-1),两者的区别就是一个是栈顶指向栈顶数据,一个指向栈顶数据的下一个,其实本质上差不多。
void STInit(STNode* pst)
{
assert(pst);
pst->arr = NULL;
pst->capacity = 0;
pst->top = -1;
}
void STDestroy(STNode* pst)
{
assert(pst);
free(pst->arr);
pst->arr = NULL;
pst->capacity = 0;
pst->top = 0;
}
3.实现入栈操作
如果栈已经满了,则进行扩容,将数据放到栈顶。
void STPush(STNode* pst,STDataType x)
{
assert(pst);
if (pst->capacity==pst->top+1)
{
int newcapacity = pst->capacity == 0 ? 4 : pst->capacity * 2;
STDataType* temp = NULL;
temp = (STDataType*)realloc(pst->arr,sizeof(STDataType) * newcapacity);
if (temp == NULL)
{
perror("malloc error");
return;
}
pst->arr = temp;
pst->capacity = newcapacity;
}
pst->arr[++pst->top] = x;
}
4.获取栈顶元素及出栈操作
出栈操作将栈顶元素向下移动即可,甚至无需删除数据,因为再次进行入栈会将其覆盖掉。获取栈顶元素要获取top的下一个位置,因为top是先存后加。
bool STEmpty(STNode* pst)
{
return pst->top == -1;
}
void STPop(STNode* pst)
{
assert(pst);
assert(!STEmpty(pst));
pst->top--;
}
STDataType STTop(STNode* pst)
{
assert(pst);
assert(!STEmpty(pst));
return pst->arr[pst->top];
}
5.获取栈中有效元素个数
由于数组偏移度是从0开始存数据,所以指向栈顶的top比实际上个数要少1,真正有效元素个数要将top+1。
int StackSize(STNode* pst)
{
assert(pst);
return pst->top+1;
}
源代码分享
//stack.h
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdbool.h>
typedef int STDataType;
typedef struct StackNode {
STDataType* arr;
int capacity;
int top;
}STNode;
void STInit(STNode* pst);
void STPush(STNode* pst,STDataType);
void STPop(STNode* pst);
void STDestroy(STNode* pst);
bool STEmpty(STNode* pst);
STDataType STTop(STNode* pst);
//stack.c
#include "stack.h"
bool STEmpty(STNode* pst)
{
return pst->top == -1;
}
void STInit(STNode* pst)
{
assert(pst);
pst->arr = NULL;
pst->capacity = 0;
pst->top = -1;
}
void STDestroy(STNode* pst)
{
assert(pst);
free(pst->arr);
pst->arr = NULL;
pst->capacity = 0;
pst->top = 0;
}
void STPush(STNode* pst,STDataType x)
{
assert(pst);
if (pst->capacity==pst->top+1)
{
int newcapacity = pst->capacity == 0 ? 4 : pst->capacity * 2;
STDataType* temp = NULL;
temp = (STDataType*)realloc(pst->arr,sizeof(STDataType) * newcapacity);
if (temp == NULL)
{
perror("malloc error");
return;
}
pst->arr = temp;
pst->capacity = newcapacity;
}
pst->arr[++pst->top] = x;
}
void STPop(STNode* pst)
{
assert(pst);
assert(!STEmpty(pst));
pst->top--;
}
STDataType STTop(STNode* pst)
{
assert(pst);
assert(!STEmpty(pst));
return pst->arr[pst->top];
}
int StackSize(STNode* pst)
{
assert(pst);
return pst->top+1;
}
//test.c
#include "stack.h"
void test1()
{
STNode ST;
STInit(&ST);
STPush(&ST, 1);
STPush(&ST, 2);
STPush(&ST, 3);
STPush(&ST, 4);
STPush(&ST, 5);
STPush(&ST, 6);
STPush(&ST, 7);
while (!STEmpty(&ST))
{
printf("%d ", STTop(&ST));
STPop(&ST);
}
STDestroy(&ST);
}
int main()
{
test1();
}

✨本文收录于数据结构理解与实现
下几期会继续带来栈的练习题以及与栈刚好相反的堆(FIFO)。如果文章对你有帮助记得点赞收藏关注。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结