您现在的位置是:首页 >技术交流 >SQL调优-性能参数介绍网站首页技术交流
SQL调优-性能参数介绍
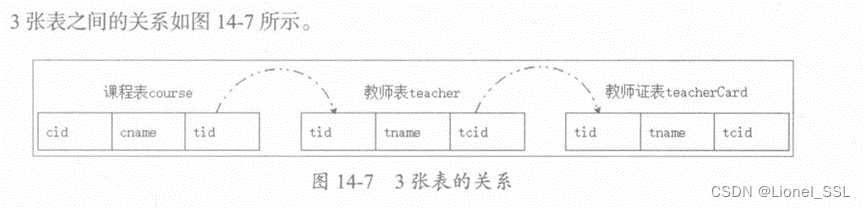
-- 课程表
create table course
(
cid int(3),
cname varchar(20),
tid int(3)
);
-- 教师表
create table teacher
(
tid int(3),
tname varchar(20),
tcid int(3)
);
-- 教师证表
create table teacherCard
(
tcid int(3),
tcdesc varchar(200)
);
explain + select语句分析
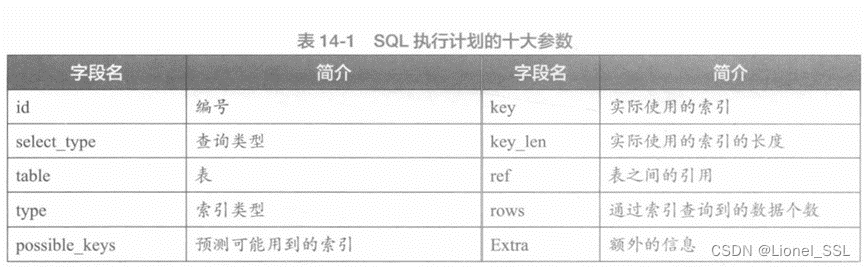
1.id:
查询课程编号为2或教师证编号为 3 的教师信息,并分析此 SQL的执行计划
explain select t.* from teacher t, course c, teacherCard tc
where t.tid = c.tid and t.tcid = tc.tcid and ( c.cid = 2 or tc.tcid = 3);

SQL引擎约定:当id值相同时,table 按照从上往下顺序执行,即此 SQL 实际的执行顺序是先t表,再 tc 表,最后c表。
注意:此时t表和 tc 表各有3条数据,c表有4条数据。如果此时继续向t表再插入3条数据(即t表共6条数据、c表4条、tc表3条)
insert into teacher values(4,'tz',1);
insert into teacher values(5,'tw',2);
insert into teacher values(6,'tl',3);

可以发现,3 张表的执行顺序变为先执行 tc 表,再执行t表,最后执行c表。
结合多表查询笛卡尔积知识可知,多表连接查询时,为了提高查询效率,SQL引擎会先查询数据量较小的表再查询数据量较大的表。
explain select tc.tcdesc from teacherCard tc where tc.tcid =
(select t.tcid from teacher t where t.tid =
(select c.tid from course c where c.cname ='sql')
);

可以发现,此时的 id 值不同。SQL引擎约定:id 值越大,查询的优先级越高。
其原因是,在执行子查询时,先查内层 SOL 再查外层 SQL。
2.select_type
SIMPLE 简单查询,不包含子查询、UNION 查询
PRIMARY 主查询,即包含子查询 SQL 中的最外层SELECT 语句
SUBQUERY 子查询,即包含子询 SQL 中的内层 SELECT 语句(非最外层)
Derived 衍生查询,使用到了临时表的查询
UNION 联合查询,使用到了 UNION的查询
UNION RESULT 告知 SQL 编写者,哪些表之间存在UNION查询。
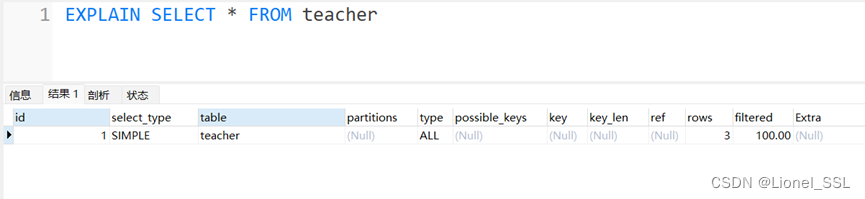
Simple 示例:
EXPLAIN SELECT * FROM teacher

PRIMARY SUBQUERY示例:
explain select tc.tcdesc from teacherCard tc where tc.tcid =
(select t.tcid from teacher t where t.tid =
(select c.tid from course c where c.cname ='sql')
);

在from子查询中只有一张表,那么该子查询就是一个 Derived
在 from 子查询中如果存在 table1 union table2 ,则 table1 的 select_type 是 Derived,table2 是UNION。
explain select cr.cname from (select * from course where tid = 1
union select * from course where tid = 2
) cr;

3. type
type表示使用的索引类型,需要注意,对 type 进行优化的前提是表中存在索引。索引类型的性能由高到低依次:system > const > eq_ref> ref> fulltext > ref_or_null> index_merge > unique_subquery > index_subquery > range > index > ALL,达到各个索引级别的条件如下。
system:
只有一条数据的系统表,或 衍生表只有一条数据的主查询。
const
仅仅能查到⼀条数据的SQL,⽤于primary key 或 unique的索引(其他索引类型不属于)
explain select * from test01 where tid =1;

eq_ref
唯⼀性索引,表索引与另外表的主键进⾏关联,两张表之间每条数据要⼀⼀对应(每个都要⼀⼀对应,不能⼀个对应多个,不能没有对应),查询的数据在表中是唯⼀性,不能有重复。
alter table teacherCard add constraint pk_tcid primary key(tcid);
alter table teacher add constraint uk_tcid unique index(tcid) ;
# 对 teacher 表进行索引唯一查询
explain select t.tcid from teacher t, teacherCard tc where t.tcid = tc.tcid;

ref
非唯一性索引。对于每个索引键的查询,返回不唯一的数据(0条或多条)
-- 给teacher表的name字段建索引(值有重复)
alter table teacher add index index_name(tname);
select * from teacher where tname='tz';

为了区分system/const、eq ref和ref,现在做以下小结。
system/const:查询结果只有一条数据
eq_ref:查询结果有多条数据,但是每个索引值对应的数据是唯一的。
ref:查询结果有多条数据,但是每个索引值对应的数据是0或多条
range
: 表示在某个范围内使用到了索引,通常见于 where 后面是范围查询的情况,如、>=、<=等。需要注意,由于 SQL 优化器会自动优化进而可能造成干扰,因此在between、>使用 in 等关键字进行范围查询时,索引有时候会失效,从而转为无索引的情况。
index
:全索引扫描,会查询全部的索引。
explain select t.tcid from teacher t

因为许多的索引类型与具体的使用场景有着密切关系,如要达到 system/const 的条件是结果集中只能有一条数据,因此在实际开发时,我们只要能达到ref或range 级别就已经不错了。
4.5.possible_key & key
possible keys 是 SQL引擎预测可能会用到的索引,但仅仅是一种预测,并不一定准确。key 表示实际查询使用到的索引。
6. key_len
索引的长度,可用于了解索引的定义情况,以及判断复合索引是否被完全使用。
create table test_kl
(
name char(20) not null default ''
);
alter table test_kl add index index_name(name) ;
explain select * from test_kl where name ='' ;

在UTF-8编码格式下,1个字符占3个字节,因此20个字符长度的name共占60个字节。此外GBK格式下1个字符占2个字节;Latin-1格式下1个字符占1个字节
(如果索引的字段允许为 NULL,则会占用1个字节作为标识)
-- 新增name1字段,name1可以为null
alter table test_kl add column name1 char(20);
alter table test_kl add index index_name1(name1);
explain select * from test_kl where name1 ='';

-- 增加一个复合索引
drop index index_name on test_kl;
drop index index_name1 on test_kl;
alter table test_kl add index name_name1_index(name,name1);
explain select * from test_kl where name1 ='';
explain select * from test_kl where name ='';

(60+60+1)

VARCHAR这种可变长字节也有自己的特性:SQL引擎会额外增加2个字节,用于标识可变长字节
-- varchar并且可以为null
alter table test_kl add column name2 varchar(20) ;
alter table test_kl add index name2_index (name2);
explain select * from test_kl where name2 ='';

(60+2+1)
7. ref
指明当前表参照的字段
alter table course add index tid_index (tid)
explain select * from course c,teacher t where c.tid = t.tid and t.tname = 'tw';

8. rows
实际执行时,通过索引查询到的数据条数





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结