您现在的位置是:首页 >技术交流 >Flink+Pulsar、Kafka问题分析及方案 -- 事务阻塞网站首页技术交流
Flink+Pulsar、Kafka问题分析及方案 -- 事务阻塞
Pulsar、Kafka的事务设计
Pulsar跟Kafka在设计事务功能时,在消费者读取消息的顺序方面,都采用了类似的设计。
比如说,先创建txn1,然后创建txn2,这两个事务生产消息到同一个topic/partition里,但是txn2比txn1先完成了,这个时候该不该让txn2生产的消息给consumer读取到?
Kafka设计文档中介绍如下:
Discussion on Transaction Ordering. In this design, we are assuming that the consumer delivers messages in offset order to preserve the behavior that Kafka users currently expect. A different way is to deliver messages in “transaction order”: as the consumer fetches commit markers, it enables the corresponding messages to be consumed.

Kafka采用的是offset order,就是说按照消息持久化的顺序来分发给consumer,而不是事务完成的顺序。
即txn2比txn1先完成了,也不会让txn2的消息立刻让consumer读取到,必须等到txn1完成才行。这种事务之间可能会有阻塞的行为,是用户必须要知晓的。
另外,这种阻塞的现象仅限于在同一个topic/partition,多个topic/partition之间的事务不会互相阻塞。
Pulsar也采用了类似的设计。
They are dispatched in published order instead of committed order. Since the consumer can only read messages before maxReadPosition, it increases end-to-end latency.
deep-dive-into-transaction-buffer-apache-pulsar
可以使用下面的测试代码进行验证:
public class TransactionTest {
private static final String topicName = "persistent://test/tb1/testTxn1";
static PulsarAdmin admin;
static PulsarClient client;
static ProducerBuilder<byte[]> producerBuilder;
static ConsumerBuilder<byte[]> consumerBuilder;
@BeforeClass
public static void initialize() throws PulsarClientException {
admin = PulsarAdmin.builder()
.serviceHttpUrl("http://164.90.77.83:8081")
.build();
client = PulsarClient.builder()
.serviceUrl("pulsar://164.90.77.83:6650")
.enableTransaction(true)
.build();
producerBuilder = client.newProducer()
.sendTimeout(0,TimeUnit.SECONDS)
.topic(topicName);
consumerBuilder = client.newConsumer()
.topic(topicName);
}
@AfterClass
public static void end() throws PulsarClientException {
admin.close();
client.close();
}
/**
* 使用两个事务txn1, txn2, txn2完成后查看是否能读取数据。
* 结论:
* 1. txn2由于在txn1后面创建,所以尽管txn2完成了,但是txn1没完成,就会阻塞txn2,txn2的数据不会被读取到。
* 2. txn1完成后,txn1、txn2的数据都能读取到,而且数据的顺序跟数据的produce顺序是相同的。(注意:不是跟事务的创建顺序相同)
*/
@Test
public void task() throws Exception{
admin.topics().resetCursor(topicName + "-partition-0", "my-subscription", MessageId.latest);
Consumer<byte[]> consumer=consumerBuilder.clone()
.subscriptionName("my-subscription")
.subscribe();
Producer<byte[]> producer=producerBuilder.clone()
.create();
Transaction transaction1 = client.newTransaction().build().join();
Transaction transaction2 = client.newTransaction().build().join();
producer.newMessage(transaction1).value("transaction1 test".getBytes()).send();
producer.newMessage(transaction2).value("transaction2 test".getBytes()).send();
Message<byte[]> message;
// commit txn2, but not commit txn1
transaction2.commit().join();
message = consumer.receive(8, TimeUnit.SECONDS);
assert message == null;
// commit txn1
transaction1.commit().join();
message = consumer.receive(8, TimeUnit.SECONDS);
assert message != null;
assert new String(message.getData()).equals("transaction1 test");
consumer.acknowledge(message);
message = consumer.receive(8, TimeUnit.SECONDS);
assert message != null;
assert new String(message.getData()).equals("transaction2 test");
consumer.acknowledge(message);
}
}
下面是Kafka的测试代码:
public class KafkaProducerTransactionalUnitTest {
private static final String TOPIC_NAME = "test_topic";
private static final String KAFKA_ADDRESS = ":9092";
private static final String CLIENT_ID = "test_client_id";
private static final int TRANSACTION_TIMEOUT_IN_MS = 3000;
private static KafkaProducer<String, String> kafkaProducer;
@BeforeAll
public static void init() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, KAFKA_ADDRESS);
props.put(ProducerConfig.CLIENT_ID_CONFIG, CLIENT_ID);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "kafka_producer_id");
props.put(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, TRANSACTION_TIMEOUT_IN_MS);
kafkaProducer = new KafkaProducer<>(props);
kafkaProducer.initTransactions();
}
@AfterAll
public static void cleanup() {
kafkaProducer.close();
}
/**
* start two producer with different transactionalId, produce messages to the same topic.
* producer1 start txn1 -> producer2 start txn2 -> producer2 commit txn2 -> consumer consume messages.
* check if consumer can consume messages in txn2.
* result: txn1 will block the messages in txn2.
*/
@Test
public void testTwoProducerStuck() {
// Set up producer2 properties
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, KAFKA_ADDRESS);
props.put(ProducerConfig.CLIENT_ID_CONFIG, CLIENT_ID);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "kafka_producer2_id");
props.put(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 30000);
KafkaProducer<String, String> kafkaProducer2 = new KafkaProducer<>(props);
kafkaProducer2.initTransactions();
// set up consumer
Properties consumerProps = new Properties();
consumerProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, KAFKA_ADDRESS);
consumerProps.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");
consumerProps.put(ConsumerConfig.GROUP_ID_CONFIG, "test_transaction");
consumerProps.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
consumerProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumerProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
consumer.subscribe(Collections.singletonList(TOPIC_NAME));
try {
// start txn1
kafkaProducer.beginTransaction();
String message = "Hello, Kafka";
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, message);
kafkaProducer.send(record);
// kafkaProducer.commitTransaction();
// start txn2 and commit
kafkaProducer2.beginTransaction();
message = "Hello, Kafka2";
record = new ProducerRecord<>(TOPIC_NAME, message);
kafkaProducer2.send(record);
kafkaProducer2.commitTransaction();
// consume messages and check
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(5));
assert records.isEmpty();
// commit txn1
kafkaProducer.commitTransaction();
// consume messages and check
records = consumer.poll(Duration.ofSeconds(5));
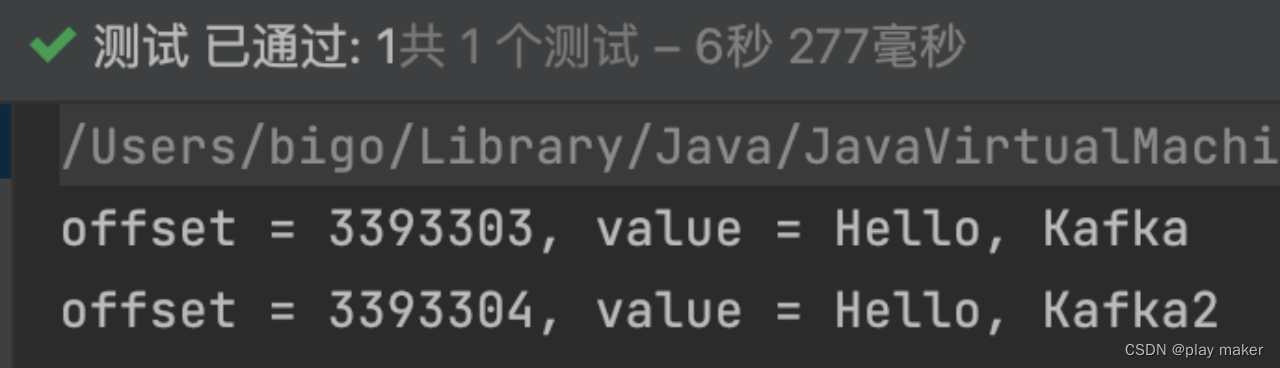
for (ConsumerRecord<String, String> record1 : records) {
System.out.printf("offset = %d, value = %s%n", record1.offset(), record1.value());
}
assert !records.isEmpty();
} catch (Exception ex) {
System.out.println(ex);
Assertions.fail("Failed to produce message with transaction");
} finally {
kafkaProducer2.close();
}
}
}
问题分析及方案
问题
Pulsar、Kafka这么设计的原因当然还是为了流式场景,因此,当我们尝试在其他场景中使用Kafka、Pulsar,那么这种设计就可能造成不少的麻烦。
就Flink而言,问题主要在于残留某些OPEN的事务没完结,导致后续的事务数据无法读取到。
有下面一些情形:
-
case1:
Flink可能有不从Checkpoint/Savepoint启动的场景:- 比如说用户创建一个topic,进行一些测试工作,这个时候会残留一些事务没结束掉。测试完成后准备用于线上生产,这个时候就会不从Checkpoint/Savepoint启动,而如果该topic还残留了OPEN的事务,就会导致线上生产的事务数据都无法读取到。
- 还有可能前面启动过任务,但是从来没成功打过checkpoint,这也会残留OPEN的事务。
-
case2:
Flink从Checkpoint/Savepoint启动时,对于前面没完结的事务都会存储在Checkpoint/Savepoint里,启动时会调用recoverAndCommit/recoverAndAbort方法来处理掉,一般这是没啥问题的。但是如果Flink任务成功执行了initializeState方法,即成功创建了新事务,但是在成功执行snapshotState前就失败挂掉了,则这个新创建的事务也是无法记录到Checkpoint/Savepoint里的,因此也会导致遗漏某些事务没有被完结。这种case也是很常见的。

简单分析
- Kafka因为使用的事务ID号都是固定的,因此使用固定的事务ID号去abort残留的事务即可。
- Pulsar事务ID号是不断变化的,不从checkpoint/snapshot启动就无法得知事务ID号,也就无法执行abort操作。
因为Pulsar事务commit操作幂等性的PR引入了一个clientName的配置,每个客户端使用的clientName都是固定的,因此我们可以增加一个接口,abort掉clientName对应的所有事务。
细节分析
Kafka方案
参考FlinkKafkaProducer 源码分析的 Abort残留的事务小节。
Pulsar方案
Pulsar由于是根据clientName去abort事务,而且一个subtask只有一个clientName,即
prefix + “-” + subtaskIndex (同一个job的多个并发子任务的prefix值都是相同的)
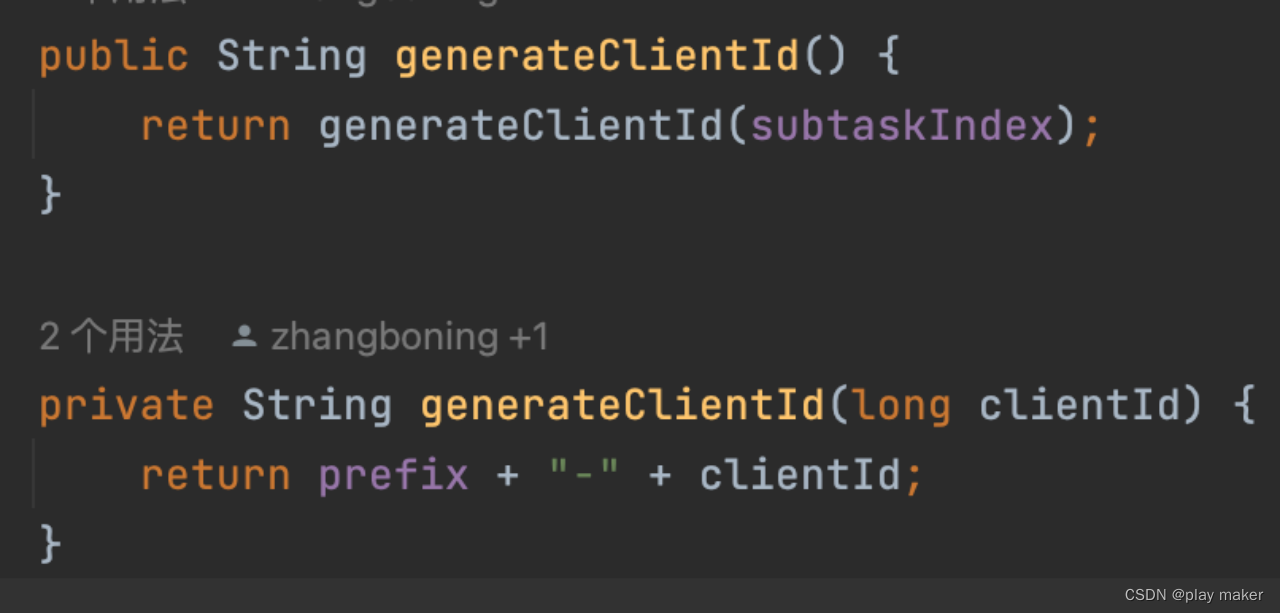
因此直接根据这一个clientName去abort即可。
所有并发子任务的clientName范围为[0 , parallelism)。
针对前面两个case进行处理:
-
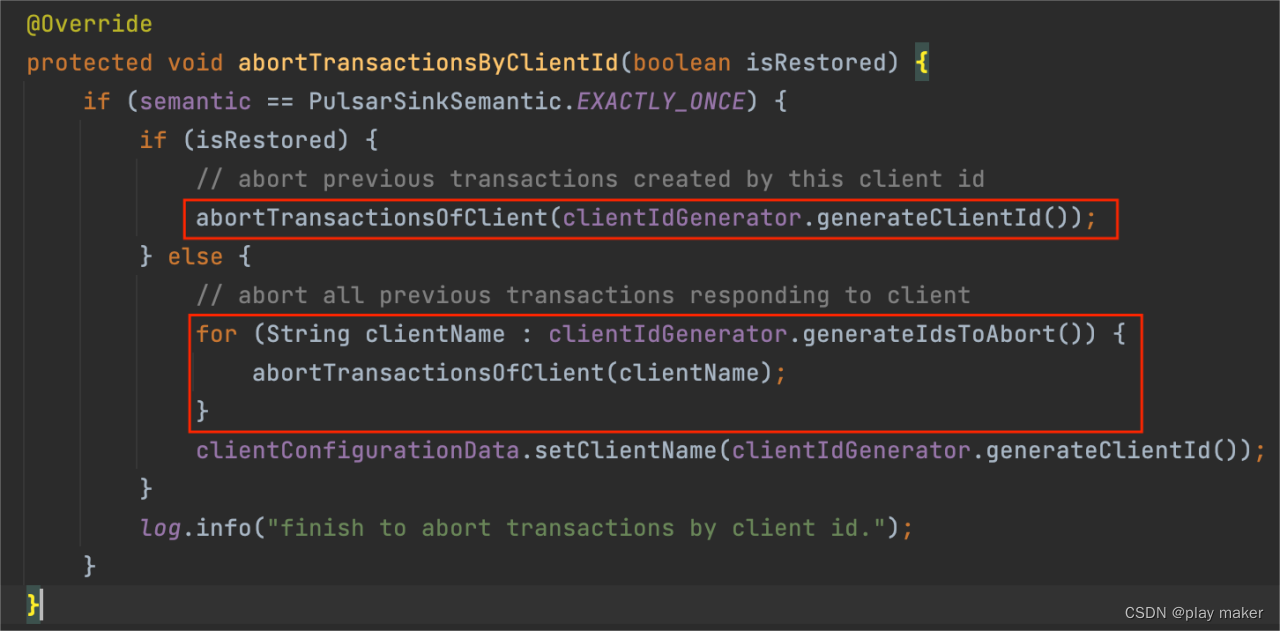
case1:从checkpoint/savepoint中恢复
只需要abort掉当前ClientName对应的事务即可,即下面第一个红框部分代码。
-
case2:不从checkpoint/savepoint中恢复
跟kafka一样,可能会发生重启任务后并发度增大的情况,假设前面启动时的并发度为P1,当前启动的并发度为P2,因此前面的任务执行使用的ClientName范围为[0,P1 ),我们需要把这些ClientName对应的事务都abort一次,但是P1是不可知的。- 如果P2大于P1,即增加并发度,则
[0,P2 )肯定包含[0,P1 ),此时对[0,P2 )遍历abort一次即可。 - 如果P1大于P2,即降低并发度,则
[0,P2 )是[0,P1 )的子集,此时无法猜测要abort多少事务ID。
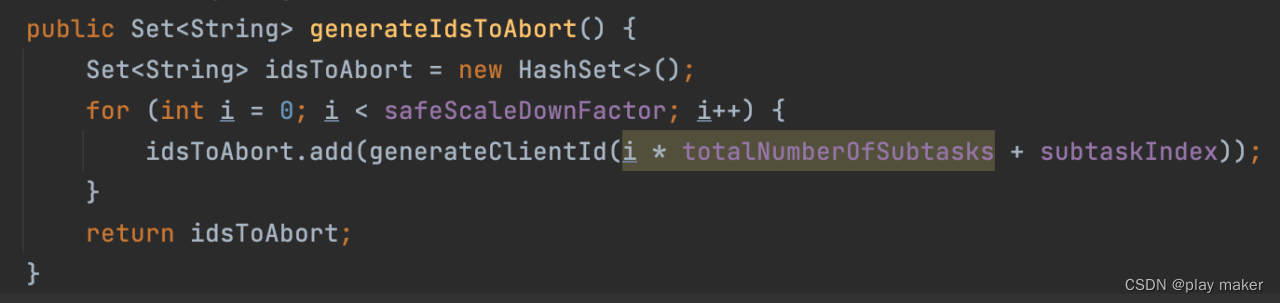
我们采用跟Kafka一样的策略:设定一个参数safeScaleDownFactor,即Flink任务减低并发度的比例不能超过这个,默认值为5。
比如说,第一次启动Flink任务的并发度为10,则第二次启动Flink任务的并发度至少为10/5=2。
通过这种方式,我们得知P1、P2的关系:P2*5>=P1
即[0,P2 * 5 )肯定包含[0,P1 )。
因此,我们对[0,P2 * 5 )范围内的ClientName都abort一次即可。
[0,P2 * 5 )范围内的ClientName还会平均分摊到当前P1个子任务去abort,各个子任务之间不会互相干扰,操作的ClientName都是不重叠的。
- 如果P2大于P1,即增加并发度,则






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结