您现在的位置是:首页 >技术杂谈 >vue导出word网站首页技术杂谈
vue导出word
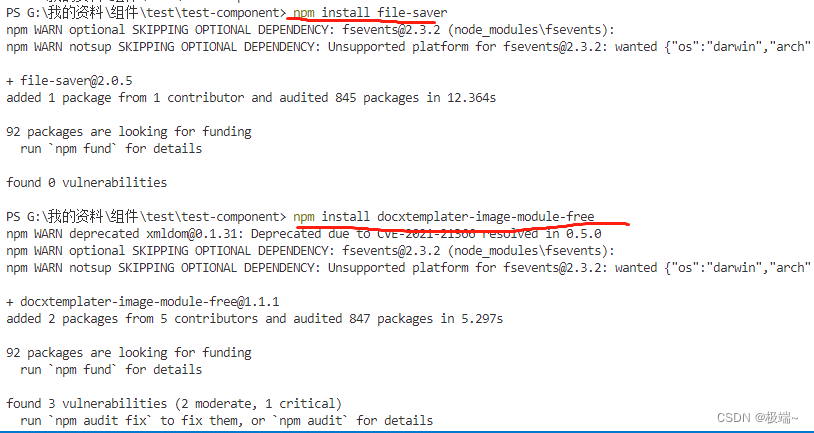
先在项目中安装所需要的依赖包
npm install file-saver
npm install docxtemplater-image-module-free
npm install docxtemplater
npm install pizzip
npm install jszip-utils
//angular-expressions 如果需要自定义图片尺寸需要安装此依赖包
如图,一定要装完整
然后设计需要导出的word模版,本地新建一个word文档。
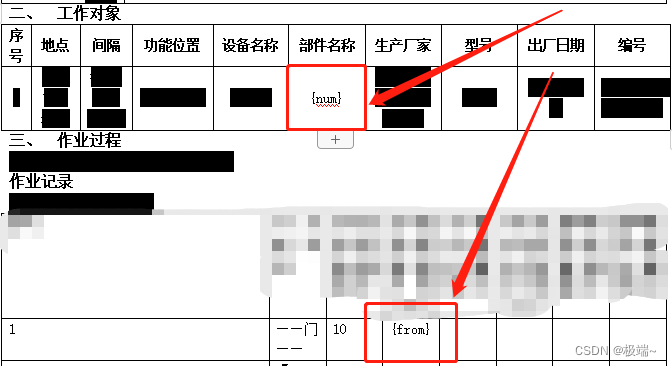
注意:
1)模板文件必须是docx文件。doc文件不能通过修改后缀名变为docx,必须另存时选择docx类型,才能实现类型转变。
2)使用英文下的花括号;
3)花括号内的键名前后不要有空格,且它与程序中的data对象的键名必须保持一致 ;
4)表格中想要循环添加的数据,需要在开头添加{#键名},在结尾处添加{/键名},一般对应的就是需要循环的数组名称。
5)图片居中不要使用{%%image2}
将编辑好的docx文档放在指定文件夹中(使用vue-cli2的放在static文件夹,vue-cli3的放在public文件夹)
新建js文件。export.js
如果不需要在word中插入图片
getBase64Sync和base64DataURLToArrayBuffer方法可直接忽略不写,单纯word可以忽略代码里图像部分
export function getBase64Sync(imgUrl) {
return new Promise(function (resolve, reject) {
// 一定要设置为let,不然图片不显示
let image = new Image();
// 解决跨域问题
image.crossOrigin = "anonymous";
//图片地址
image.src = imgUrl;
// image.onload为异步加载
image.onload = function () {
let canvas = document.createElement("canvas");
canvas.width = image.width;
canvas.height = image.height;
let context = canvas.getContext("2d");
context.drawImage(image, 0, 0, image.width, image.height);
//图片后缀名
let ext = image.src
.substring(image.src.lastIndexOf(".") + 1)
.toLowerCase();
//图片质量
let quality = 0.8;
//转成base64
let dataurl = canvas.toDataURL("image/" + ext, quality);
//返回
resolve(dataurl);
};
});
}
//在实际使用过程中遇到了一点问题就是客户在短时间内大量下载文件,导致浏览器崩溃,
//测试后发现是下载的word文件内存过大,原始的word模版只有几十k,导出的图片也只有200k,但下载后的文件高大10M
//搜索文件后发现通过canvas转base64的方式会有可能引起图片内存过大或者过小
//于是修改后采用了下面的方法转base64
export function getBase(imgUrl) {
return new Promise((resolve, reject) => {
window.URL = window.URL || window.webkitURL;
var xhr = new XMLHttpRequest();
xhr.open("get", imgUrl, true);
// 至关重要
xhr.responseType = "blob";
xhr.onload = function () {
if (this.status == 200) {
//得到一个blob对象
var blob = this.response;
console.log("blob", blob);
// 至关重要
let oFileReader = new FileReader();
oFileReader.onloadend = function (e) {
// 此处拿到的已经是 base64的图片了
base64 = e.target.result;
// return base64;
resolve(base64);
// console.log("方式一》》》》》》》》》", base64);
};
oFileReader.readAsDataURL(blob);
} else {
reject();
}
};
xhr.send();
});
}
//导入需要的依赖包
import PizZip from "pizzip";
import docxtemplater from "docxtemplater";
import JSZipUtils from "jszip-utils";
import { saveAs } from "file-saver";
//将base64格式的数据转为ArrayBuffer
function base64DataURLToArrayBuffer(dataURL) {
const base64Regex = /^data:image/(png|jpg|jpeg|svg|svg+xml);base64,/;
if (!base64Regex.test(dataURL)) {
return false;
}
const stringBase64 = dataURL.replace(base64Regex, "");
let binaryString;
if (typeof window !== "undefined") {
binaryString = window.atob(stringBase64);
} else {
binaryString = new Buffer(stringBase64, "base64").toString("binary");
}
const len = binaryString.length;
const bytes = new Uint8Array(len);
for (let i = 0; i < len; i++) {
const ascii = binaryString.charCodeAt(i);
bytes[i] = ascii;
}
return bytes.buffer;
}
/**
* 参数明细
* tempDocxPath 模板文件路径
* wordData 导出数据
* fileName 导出文件名
* imgSize 自定义图片尺寸
*/
export const exportWord = (tempDocxPath, wordData, fileName, imgSize) => {
//这里要引入处理图片的插件
var ImageModule = require("docxtemplater-image-module-free");
// const expressions = require("angular-expressions");
// 读取并获得模板文件的二进制内容
JSZipUtils.getBinaryContent(tempDocxPath, function (error, content) {
if (error) {
throw error;
}
//设置图片尺寸大小
// expressions.filters.size = function (input, width, height) {
// return {
// data: input,
// size: [width, height],
// };
// };
// function angularParser(tag) {
// const expr = expressions.compile(tag.replace(/’/g, "'"));
// return {
// get(scope) {
// return expr(scope);
// },
// };
// }
// 图片处理
let opts = {};
opts = {
//图像是否居中
centered: false,
};
opts.getImage = (chartId) => {
//console.log(chartId);//base64数据
//将base64的数据转为ArrayBuffer
return base64DataURLToArrayBuffer(chartId);
};
opts.getSize = function (img, tagValue, tagName) {
//console.log(img);//ArrayBuffer数据
//console.log(tagValue);//base64数据
//console.log(tagName);//wordData对象的图像属性名
//自定义指定图像大小
if (imgSize.hasOwnProperty(tagName)) {
return imgSize[tagName];
} else {
return [600, 350];
}
};
// 创建一个PizZip实例,内容为模板的内容
let zip = new PizZip(content);
// 创建并加载docxtemplater实例对象
let doc = new docxtemplater();
doc.attachModule(new ImageModule(opts));
doc.loadZip(zip);
doc.setData(wordData);
try {
// 用模板变量的值替换所有模板变量
doc.render();
} catch (error) {
// 抛出异常
let e = {
message: error.message,
name: error.name,
stack: error.stack,
properties: error.properties,
};
console.log(
JSON.stringify({
error: e,
})
);
throw error;
}
// 生成一个代表docxtemplater对象的zip文件(不是一个真实的文件,而是在内存中的表示)
let out = doc.getZip().generate({
type: "blob",
mimeType:
"application/vnd.openxmlformats-officedocument.wordprocessingml.document",
});
// 将目标文件对象保存为目标类型的文件,并命名
saveAs(out, fileName);
});
};
在需要导出word的文件中引入刚才的js文件
import { exportWord, getBase64Sync } from "@/plugins/export.js";
使用方法
async exportWordTest() {
//具体数据根据实际情况灵活变动
let data = {
num: '测试num',
from:'测试来源'
image: await getBase64Sync(url),
};
exportWord("test.docx", data, "测试.docx");
}
打开生成的word文档
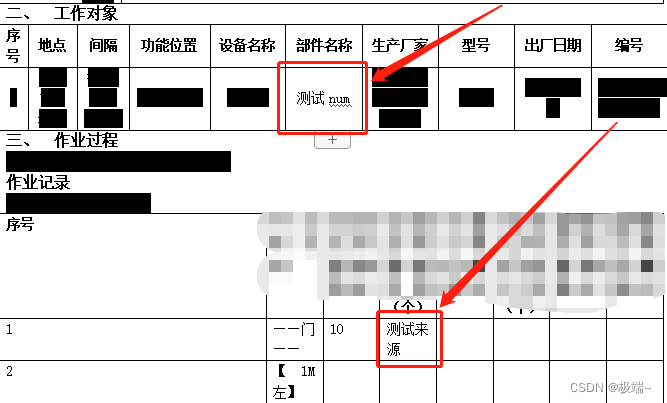
完成。
遇见报错:Error: Can’t find end of central directory : is this a zip file ?
我的原因是我的word模板直接修改的后缀docx,需要另存为docx才可以。
文章借鉴:https://zhuanlan.zhihu.com/p/497941780






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结