您现在的位置是:首页 >技术教程 >【云原生-深入理解Kubernetes-2】容器 Linux Cgroups 限制网站首页技术教程
【云原生-深入理解Kubernetes-2】容器 Linux Cgroups 限制
文章目录

系列文章目录
【云原生-深入理解Kubernetes-1】容器的本质是进程
?关于作者
大家好,我是秋意零。
? CSDN作者主页
- ? 博客主页
? 简介
- ? 普通本科生在读
- 在校期间参与众多计算机相关比赛,如:? “省赛”、“国赛”,斩获多项奖项荣誉证书
- ? 各个平台,秋意零 账号创作者
- ? 云社区 创建者
点赞、收藏+关注下次不迷路!
欢迎加入云社区
回顾
上一章提到,容器本质是一个进程,通过 Linux 系统 NameSpace 技术实现资源隔离(障眼法),通过它修改了进程看待整个操作系统“视角”,只能看到某些指定的内容。
一、Docker Engine 和 Hypervisor 区别
- 在之前虚拟机与容器技术的对比图中,不应该把 Docker Engine(或其他容器管理工具) 跟 Hypervisor 放在相同的位置,因为 Hypervisor 是对创建出来的虚拟机隔离环境负责,而 Docker Engine(或其他容器管理工具)是借助宿主机本身 NameSpace 实现的。
- 所以应该把 Docker Engine(或其他容器管理工具)放在和宿主机其他应用程序同级别的位置。都是宿主机统一管理,只不过这些进程设置了 Namespace 参数。而 Docker 在这里,更多的是辅助和管理。
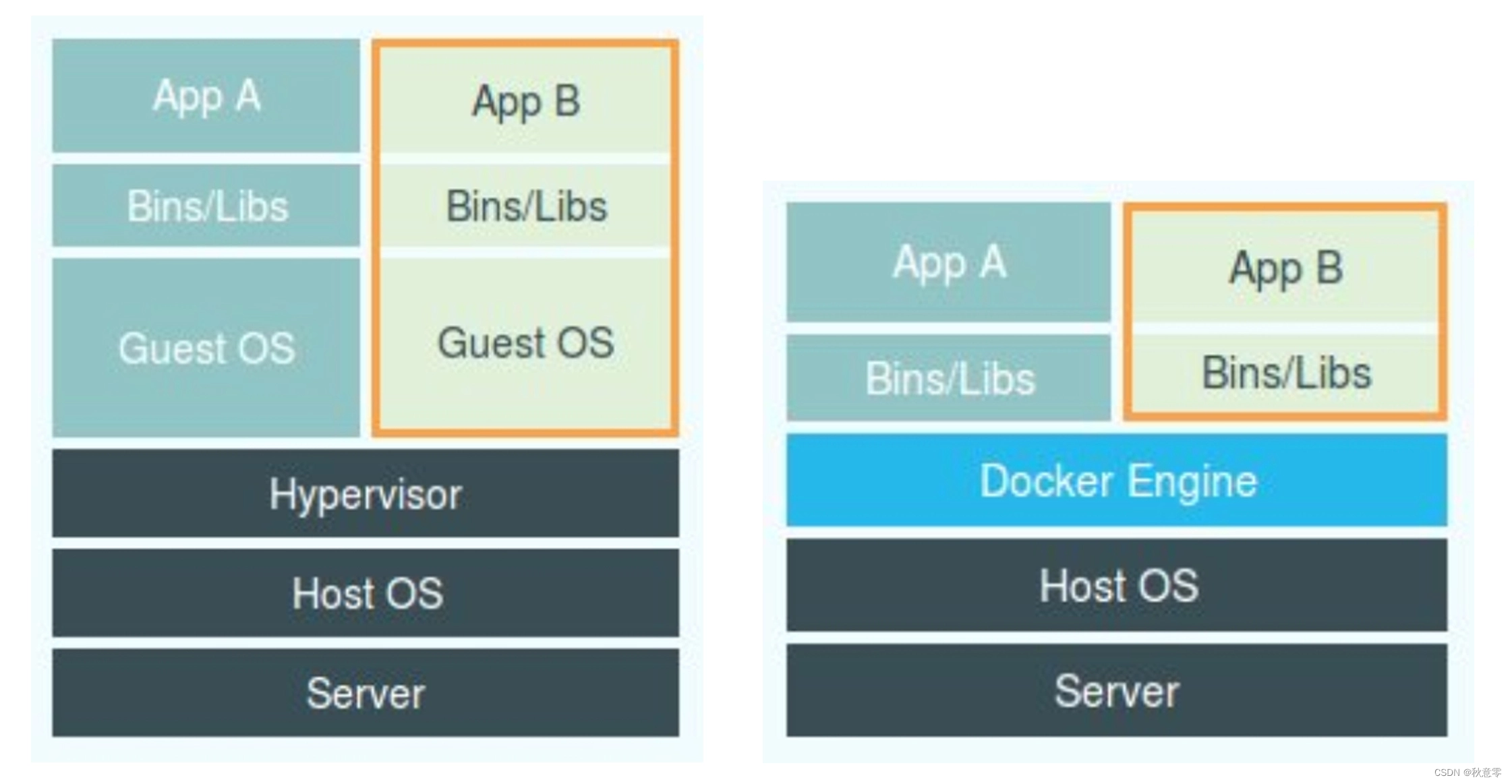
二、容器比虚拟机受欢迎?
优势
- 因为虚拟机必须包含一个操作系统,进而让应用进程运行在这个虚拟机操作系统之上,这就不可避免地带来了额外的资源消耗和占用
- 根据实验,一个运行着 CentOS 的 KVM 虚拟机启动后,在不做优化的情况下,虚拟机自己就需要占用 100~200 MB 内存。此外,用户应用运行在虚拟机里面,它对宿主机操作系统的调用就不可避免地要经过虚拟化软件的拦截和处理,这本身又是一层性能损耗,尤其对计算资源、网络和磁盘 I/O 的损耗非常大。
- 相对于容器,这些消耗和占用都是不存在的,所以 ** “敏捷”和“高性能”是容器相较于虚拟机最大的优势 ** 。
劣势
隔离不彻底
不过,有利就有弊,基于 Linux Namespace 的隔离机制相比于虚拟化技术也有很多不足之处,其中最主要的问题就是:隔离得不彻底。如果你要在 Windows 宿主机上运行 Linux 容器,或者在低版本的 Linux 宿主机上运行高版本的 Linux 容器,都是行不通的。
安全问题
因为共享宿主机内核,容器中的应用暴露出来的攻击面就很大,所以生产环境中,没有人敢把运行在宿主机上的容器直接暴露到公网上。
三、Linux Cgroups 限制
虽然对容器的进程使用了 NameSpace 技术,但是对于宿主机上的进程和容器进程是处于同等级别的资源竞争关系。这就意味着,比如 100 号进程表面被隔离起来了,但是它还是会使用到宿主机上的资源(CPU、内存),也会被其他宿主机上的进程强占用资源,当然自己这个 100 号进程也有可能把所有资源吃光。这时就需要使用 Linux Cgroups 进行资源限制。
- Linux Cgroups 就是 Linux 内核中用来为进程设置资源限制的一个重要功能。
- Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,它以文件和目录的方式组织在 /sys/fs/cgroup 路径下,我们可以使用 mount -t 命令展现出来
[root@master ~]# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
可以看到,在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。这些是可以被 Cgroups 进行限制的资源种类。
[root@master ~]# ll /sys/fs/cgroup/
total 0
drwxr-xr-x 5 root root 0 May 18 15:09 blkio
lrwxrwxrwx 1 root root 11 May 18 15:09 cpu -> cpu,cpuacct
lrwxrwxrwx 1 root root 11 May 18 15:09 cpuacct -> cpu,cpuacct
drwxr-xr-x 5 root root 0 May 18 15:09 cpu,cpuacct
drwxr-xr-x 3 root root 0 May 18 15:09 cpuset
drwxr-xr-x 5 root root 0 May 18 15:09 devices
drwxr-xr-x 3 root root 0 May 18 15:09 freezer
drwxr-xr-x 3 root root 0 May 18 15:09 hugetlb
drwxr-xr-x 5 root root 0 May 18 15:09 memory
lrwxrwxrwx 1 root root 16 May 18 15:09 net_cls -> net_cls,net_prio
drwxr-xr-x 3 root root 0 May 18 15:09 net_cls,net_prio
lrwxrwxrwx 1 root root 16 May 18 15:09 net_prio -> net_cls,net_prio
drwxr-xr-x 3 root root 0 May 18 15:09 perf_event
drwxr-xr-x 5 root root 0 May 18 15:09 pids
drwxr-xr-x 5 root root 0 May 18 15:09 systemd
在子系统对应的资源种类下,你就可以看到该类资源具体可以被限制的方法。
cpu.cfs_period_us:限制进程在某一段时间内cpu.cfs_quota_us:只能被分配到总量为某一段 CPU 时间
[root@master ~]# ls /sys/fs/cgroup/cpu,cpuacct/
cgroup.clone_children cpuacct.stat cpu.cfs_quota_us cpu.stat system.slice
cgroup.event_control cpuacct.usage cpu.rt_period_us kubepods.slice tasks
cgroup.procs cpuacct.usage_percpu cpu.rt_runtime_us notify_on_release user.slice
cgroup.sane_behavior cpu.cfs_period_us cpu.shares release_agent
使用 Cgroups 子系统配置文件
- 前提知识
我们在 /sys/fs/cgroup/cpu 目录下创建一个 container 目录,这个目录被称为“控制组”,操作系统会在你新创建的 container 目录下,自动生成该子系统对应的资源限制文件。
$ cd /sys/fs/cgroup/cpu
$ mkdir container
#自动生成该子系统对应的资源限制文件。
$ ls container/
cgroup.clone_children cpuacct.usage cpu.rt_period_us notify_on_release
cgroup.event_control cpuacct.usage_percpu cpu.rt_runtime_us tasks
cgroup.procs cpu.cfs_period_us cpu.shares
cpuacct.stat cpu.cfs_quota_us cpu.stat
后台运行 while 死循环,并返回改进程号(PID)是 98158,也可以使用 jobs 命令查看后台进程号(PID)是多少
$ while : ; do : ; done &
[1] 98158
$ jobs -l
[1]+ 98158 Running while :; do
:;
done &
使用 top 命令,可以看到 CPU 利用率,可以把我 2核 CPU 占用了 50%
$ top
%Cpu(s): 50.0 us, 3.1 sy, 0.0 ni, 46.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
现在我们查看 container 目录下的 cpu.cfs_quota_us 文件默认内容是 -1 表示没有任何限制, cpu.cfs_period_us 文件默认内容是 100000 us(100ms)
[root@test_2 cpu]# cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
-1
[root@test_2 cpu]# cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us
100000
- 限制
我们可以通过修改上诉两个文件内容,来限制某个进程 cpu 利用率
向 container 组里的 cpu.cfs_quota_us 文件写入 10000 us (10ms),这意味着每 100 ms 的时间里,被改控制组限制的进程只能使用 10 ms 的 CPU 时间,也就是说只能使用到 10% 的 CPU 带宽。
[root@test_2 cpu]# echo 10000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
我们把限制的进程 PID 写入 container 组里的 tasks 文件,这样能对该进程进行限制了
$ echo 98158 > /sys/fs/cgroup/cpu/container/tasks
可以看到之前的 CPU 使用率为 50%,现在为 5.2%,在 50%的基础上,使用率只要 10% 了,也就是 5%
$ top
%Cpu(s): 5.2 us, 0.5 sy, 0.0 ni, 94.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
对于容器来说,它在 system.slice 子系统下面,为每个容器创建以 docker-容器id.scope 命名为规则的目录,容器启动进程之后,把这个进程的 PID 填写到对于的控制组的 tasks 文件即可。
$ docker run -dit --cpu-period=100000 --cpu-quota=20000 --name=qyl_centos centos
e2a823c812f71c594990308a06c5c4c805a2285851c0418ab086e366ef8006c5
$ ls /sys/fs/cgroup/cpu,cpuacct/system.slice/docker-e2a823c812f71c594990308a06c5c4c805a2285851c0418ab086e366ef8006c5.scope
cgroup.clone_children cpuacct.stat cpu.cfs_period_us cpu.rt_runtime_us notify_on_release
cgroup.event_control cpuacct.usage cpu.cfs_quota_us cpu.shares tasks
cgroup.procs cpuacct.usage_percpu cpu.rt_period_us cpu.stat
查看 qyl_centos 容器的 PID 是多少,这里可以看到是 1822
[root@master01 ~]# docker top qyl_centos
UID PID PPID C STIME TTY TIME CMD
root 1822 1801 0 15:54 pts/0 00:00:00 /bin/bash
查看 tasks 文件中进程 PID,可以看到是 1822,与上述 qyl_centos 容器 PID 一致
$ cat /sys/fs/cgroup/cpu,cpuacct/system.slice/docker-e2a823c812f71c594990308a06c5c4c805a2285851c0418ab086e366ef8006c5.scope/tasks
1822
也可以看 cpu.cfs_period_us 和 cpu.cfs_quota_us 是和 docker run 运行容器时限制一致
$ cat /sys/fs/cgroup/cpu,cpuacct/system.slice/docker-e2a823c812f71c594990308a06c5c4c805a2285851c0418ab086e366ef8006c5.scope/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu,cpuacct/system.slice/docker-e2a823c812f71c594990308a06c5c4c805a2285851c0418ab086e366ef8006c5.scope/cpu.cfs_quota_us
20000
✊ 最后
? 我是秋意零,欢迎大家一键三连、加入云社区
? 我们下期再见(⊙o⊙)!!!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结