您现在的位置是:首页 >技术教程 >Redis数据一致性问题的三种解决方案网站首页技术教程
Redis数据一致性问题的三种解决方案

1、首先redis是什么
Redis(Remote Dictionary Server ),是一个高性能的基于Key-Value结构存储的NoSQL开源数据库。大部分公司采用Redis来实现分布式缓存,用来提高数据查询效率。
2、为什么会选Redis
在Web应用发展的初期,系统的访问和并发并不高,交互也比较少。但随着业务的扩大,访问量的提升,使得服务器负载和关系型数据库出现瓶颈,而导致瓶颈的源头,主要体现在磁盘IO上。随着互联网的进一步发展,对系统性能有了更高的要求,Redis的出现,解决了很多问题。至于我们为什么要选择Redis,我总结为以下六个原因:
1)、基于内存存储,可以降低对关系型数据库的访问频次,从而缓解数据库压力
2)、数据IO操作能支持更高级别的QPS,官方发布的指标是10W;
3)、提供了比较多的数据存储结构,比如string、list、hash、set、zset等等。
4)、采用单线程实现IO操作,避免了并发情况下的线程安全问题。
5)、可以支持数据持久化,避免因服务器故障导致数据丢失的问题
6)、Redis还提供了更多高级功能,比如分布式锁、分布式队列、排行榜、查找附近的人等功能,为更复杂的需求提供了成熟的解决方案。
3、 应用场景
缓存,作为Key-Value形态的内存数据库,Redis 最先会被想到的应用场景便是作为数据缓存
分布式锁,分布式环境下对资源加锁
分布式共享数据,在多个应用之间共享
排行榜,自带排序的数据结构(zset)
消息队列,pub/sub功能也可以用作发布者 / 订阅者模型的消息

4、redis用作缓存时
4.1、作为缓存使用流程
缓存由于其高并发和高性能的特性,已经在项目中被广泛使用。在读取缓存方面,大家没啥疑问,都是按照下图的流程来进行业务操作。
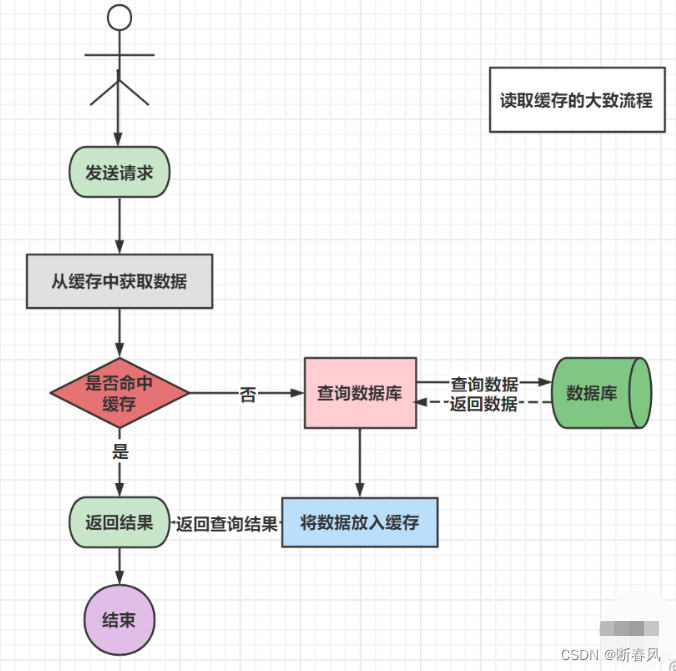
4.2、数据性一致性问题
例如我们使用Redis来作为缓存时,让请求先访问到Redis,而不是直接访问数据库。而在这种业务场景下,可能会出现缓存和数据库数据不一致性的问题。
在更新的时候,操作缓存和数据库无疑就是以下四种可能之一:
● 先更新缓存,再更新数据库
● 先更新数据库,再更新缓存
● 先删除缓存,再更新数据库
● 先更新数据库,再删除缓存
4.2.1、先更新缓存,再更新数据库
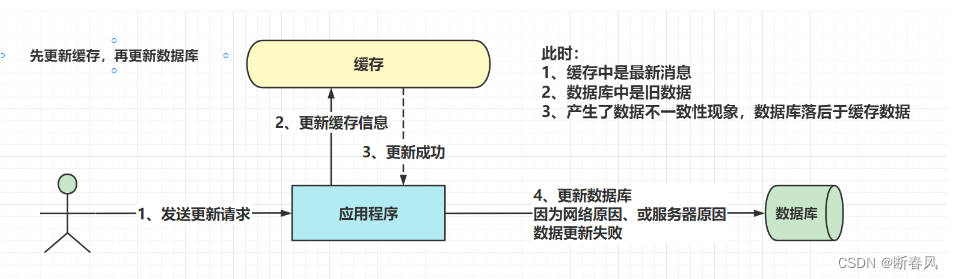
如果我成功更新了缓存,但是在执行更新数据库的那一步,服务器突然宕机了,那么此时,我的缓存中是最新的数据,而数据库中是旧的数据。
脏数据就因此诞生了,并且如果我缓存的信息(是单独某张表的),而且这张表也在其他表的关联查询中,那么其他表关联查询出来的数据也是脏数据,结果就是直接会产生一系列的问题。
4.2.2、先更新数据库,在更新缓存
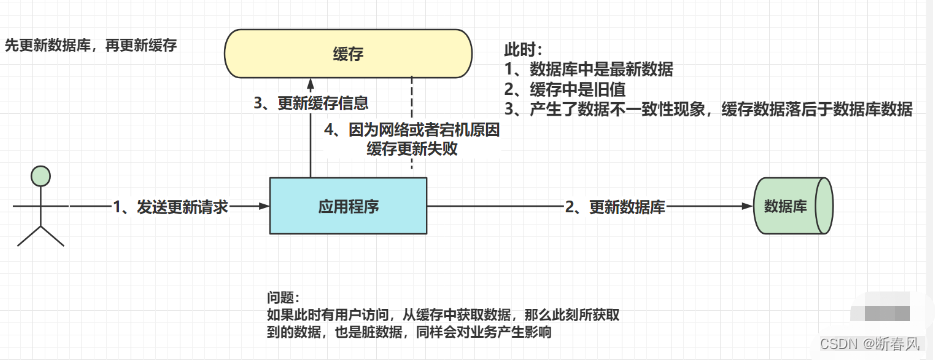
只有等到缓存过期之后,才能访问到正确的信息。那么在缓存没过期的时间段内,所看到的都是脏数据。
以上两图中只要执行第二步时失败了,就必然会产生脏数据。
4.2.3、先删除缓存,在更新数据库
这种方式在没有高并发的情况下,是可能保持数据一致性的。
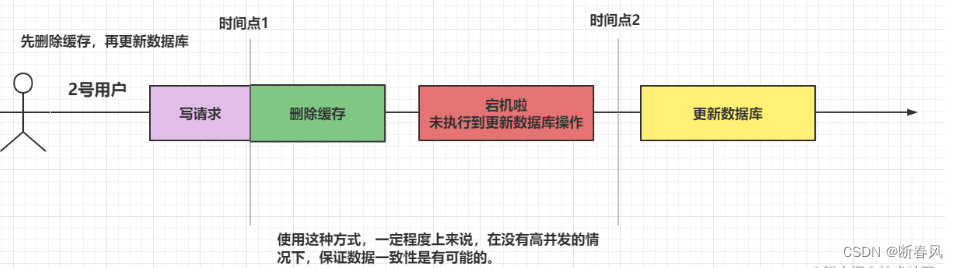
如果只有第一步执行成功,而第二步失败,那么只有缓存中的数据被删除了,但是数据库没有更新,那么在下一次进行查询的时候,查不到缓存,只能重新查询数据库,构建缓存,这样其实也是相对做到了数据一致性。
但如果是处于读写并发的情况下,还是会出现数据不一致的情况:
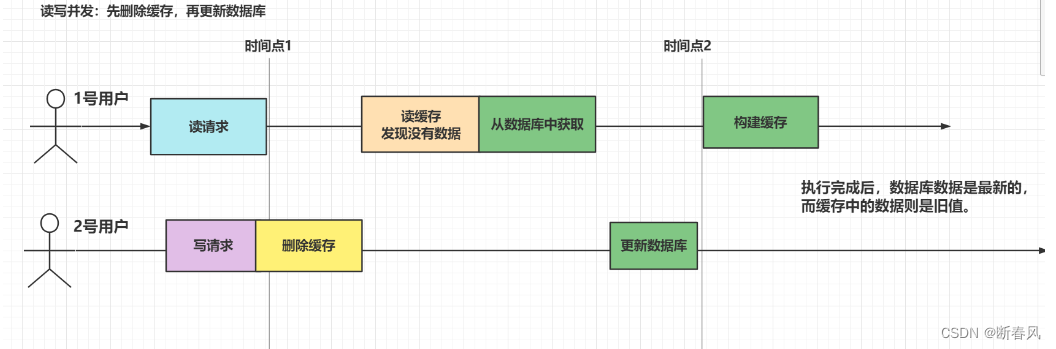
执行完成后,明显可以看出,1号用户所构建的缓存,并不是最新的数据,还是存在问题的
4.2.4、先更新数据库,在删除缓存
如果更新数据库成功了,而删除缓存失败了,那么数据库中就会是新数据,而缓存中是旧数据,数据就出现了不一致情况。
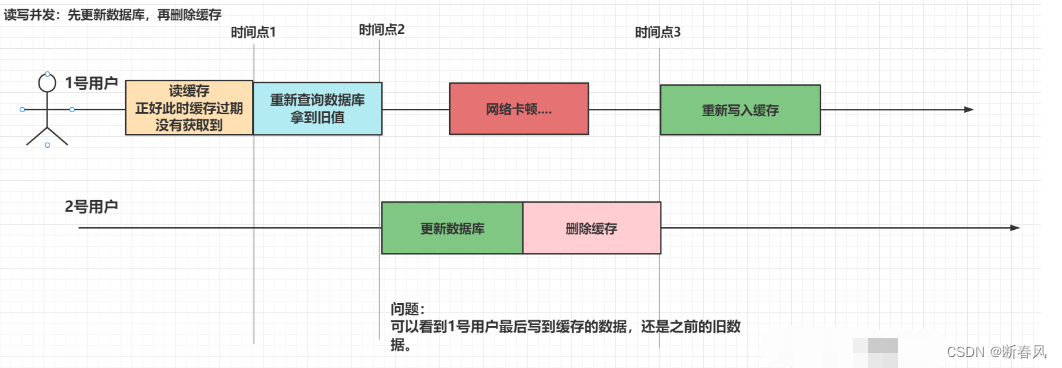
和之前一样,如果两段代码都执行成功,在并发情况下会是什么样呢?

还是会造成数据的不一致性。
但是此处达成这个数据不一致性的条件明显会比起其他的方式更为困难 :
● 时刻1:读请求的时候,缓存正好过期
● 时刻2:读请求在写请求更新数据库之前查询数据库,
● 时刻3:写请求,在更新数据库之后,要在读请求成功写入缓存前,先执行删除缓存操作。
这通常是很难做到的,因为在真正的并发开发中,更新数据库是需要加锁的,不然没一点安全性~
一定程度上来讲,这种方式还是解决了一定程度上的数据不一致性问题的。
4.3、总结
以上四种方式无论选择那种方式,如果实在多服务或时并发的情况下,其实都是有可能产生数据不一致性的。
为了解决这个存在的问题有以下方式:
4.3.1、延迟双删
先进行缓存清除,再执行update,最后(延迟N秒)再执行缓存清除。进行两次删除,且中间需要延迟一段时间

public void write(String key,Object data){
// 延迟双删伪代码
deleteRedisCache(key); // 删除redis缓存
updateMysqlSql(obj); // 更新mysql
Thread.sleep(100); // 延迟一段时间
deleteRedisCache(key); // 再次删除该key的缓存
}
延迟双删的流程图:
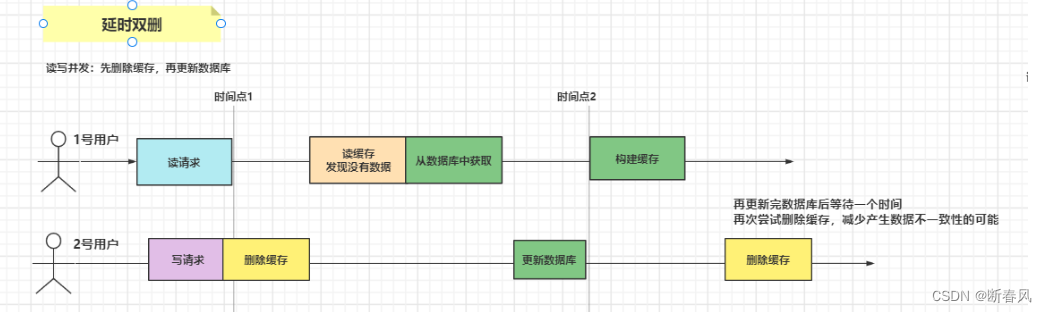
解决这样的问题,其实最好的方式就是在执行完更新数据库的操作后,先休眠一会儿,再进行一次缓存的删除,以确保数据一致性
首先延迟删除的时间需要大于 1号用户执行流程的总时间
就是1号用户从数据库读取数据 写入缓存时间
4.3.2、通过发送MQ,在消费者线程去同步Redis
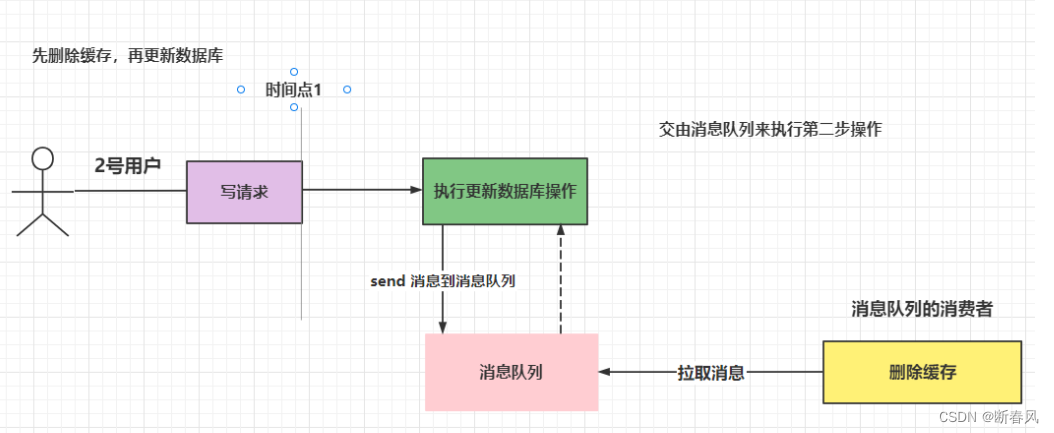
无论是更新缓存还是删除缓存,在同时操作缓存和数据库时,都无法保证两者都能一次性操作成功,所以我们最好的办法就是重试,这个重试并不是立即重试,因为缓存和数据库可能因为网络或者其它原因停止服务了,立即重试成功率极低,而且重试会占用线程资源,显然不合理,所以我们需要采用异步重试机制。
异步重试我们可以使用消息队列来完成,因为消息队列可以保证消息的可靠性,消息不会丢失,也可以保证正确消费,当且仅当消息消费成功后才会将消息从消息队列中删除。
优点1:可以大幅减少接口的延迟返回的问题
优点2:MQ本身有重试机制,无需人工去写重试代码
优点3:解耦,把查询Mysql和同步Redis完全分离,互不干扰
4.3.3、Canal 订阅日志实现
当我们业务修改数据时,我们只需要更新数据库,无需修改缓存,那什么时候修改缓存呢?
以mysql为例,在数据库一条记录发生变更时就会生成一条binlog日志,我们可以订阅这种消息,拿到具体的数据,然后根据日志消息更新缓存,订阅日志目前比较流行的就是阿里开源的canal,那么我们的架构就变为如下形式。
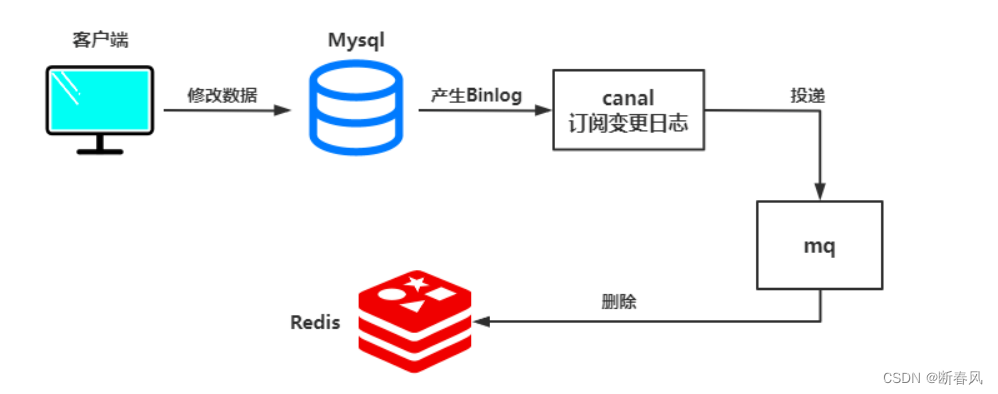
订阅数据库变更日志,当数据库发生变更时,我们可以拿到具体操作的数据,然后再去根据具体的数据,去删除对应的缓存。
当然Canal 也是要配合消息队列一起来使用的,因为其Canal本身是没有数据处理能力的。
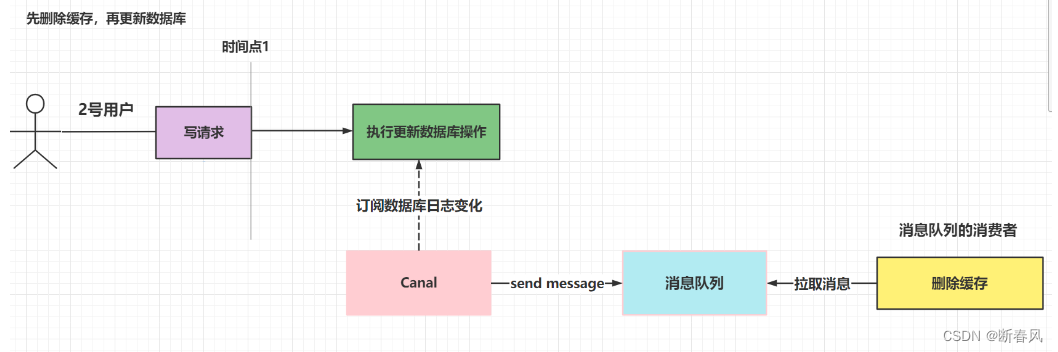
这个方式算的上彻底解耦了,应用程序代码无需再管消息队列方面发送失败问题,全交由 Canal来发送。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结