您现在的位置是:首页 >技术交流 >设计模式实战 | 迭代器模式 | 分词器网站首页技术交流
设计模式实战 | 迭代器模式 | 分词器
简介设计模式实战 | 迭代器模式 | 分词器
1、场景
假设有下面这样一个字符串属性, 代表着属性逐级调用, 我们需要解析出每一个字段属性方便我们后续进行业务处理。
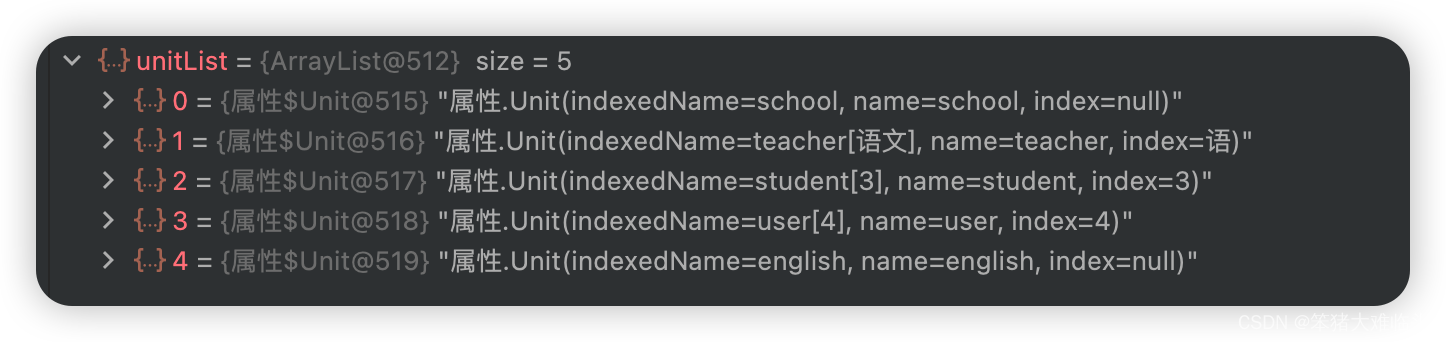
String properties = "school.teacher[语文].student[3].user[4].english.score";
2、传统写法
遍历该属性字符串然后不断截取出每一个字段, 然后按顺序收集到集合中
public static void main(String[] args) {
String properties = "school.teacher[语文].student[3].user[4].english.score";
int index = -1;
List<Unit> unitList = new ArrayList<>();
while((index = properties.indexOf(".")) != -1){
String prop = properties.substring(0,index);
properties = properties.substring(index+1);
Unit unit = new Unit();
unit.setIndexedName(prop);
if (prop.contains("[")){
int ltIndex = prop.indexOf("[");
unit.setName(prop.substring(0,ltIndex));
unit.setIndex(prop.substring(ltIndex+1,ltIndex+2));
}else {
unit.setName(prop);
}
unitList.add(unit);
}
}
@Data
public static class Unit {
private String indexedName;
private String name;
private String index;
}
运行结果:
3、迭代器模式
基于面向对象处理和分治的思想, 可以认为 属性字符串 school.teacher[语文].student[3]的处理逻辑和 子串teacher[语文].student[3] 的处理逻辑是一致的。 所以只需要逐级迭代获取出子串,然后将子串交给该逻辑处理, 然后该逻辑又会不断重复只不过处理的逻辑单元变小了而已。
/**
分词单元: 负责将一个属性字符串分解成各个部分
*/
@Data
public class PropertyUnit {
private String fullName;
private String indexedName;
private String name;
private String index;
private String children;
public PropertyUnit(String fullname) {
this.fullName = fullname;
int delim = fullname.indexOf('.');
if (delim > -1) {
name = fullname.substring(0, delim);
children = fullname.substring(delim + 1);
} else {
name = fullname;
children = null;
}
indexedName = name;
delim = name.indexOf('[');
if (delim > -1) {
index = name.substring(delim + 1, name.length() - 1);
name = name.substring(0, delim);
}
}
}
/**
分词器:
实现了迭代器, 通过将next方法将子串的处理交给下一个分词单元, 这样就可逐级迭代每个属性字段。
*/
public class PropertyTokenizer implements Iterable<PropertyTokenizer>, Iterator<PropertyTokenizer> {
private PropertyUnit cur;
public PropertyTokenizer(String fullName) {
this.cur = new PropertyUnit("."+fullName);
}
@Override
public Iterator<PropertyTokenizer> iterator() {
return this;
}
@Override
public boolean hasNext() {
return cur.getChildren() != null;
}
@Override
public PropertyTokenizer next() {
this.cur = new PropertyUnit(this.cur.getChildren());
return this;
}
public String getIndexedName() {
return cur.getIndexedName();
}
public String getFullName() {
return cur.getFullName();
}
public String getName() {
return cur.getName();
}
public String getIndex() {
return cur.getIndex();
}
public String getChildren() {
return cur.getChildren();
}
public static void main(String[] args) {
String properties = "school.teacher[语文].student[3].user[4].english.score";
// 迭代器遍历
Iterator<PropertyTokenizer> iterator = new PropertyTokenizer(properties).iterator();
while (iterator.hasNext()) {
PropertyTokenizer next = iterator.next();
System.out.println(next.getIndexedName());
}
System.out.println("==========");
// 增强for循环遍历
PropertyTokenizer tokenizer1 = new PropertyTokenizer(properties);
for (PropertyTokenizer propertyTokenizer1 : tokenizer1) {
System.out.println(propertyTokenizer1.getIndexedName());
}
}
}
运行结果:
school
teacher[语文]
student[3]
user[4]
english
score
4、总结
- 通过改进,将整体的分词逻辑交给具体的迭代分词器处理。 与传统写法不同的是,如果
每个属性单元可能会有不同的处理逻辑,此方法依旧可以进行扩展只需要在next获取具体的分词单元即可而不影响整体处理逻辑。 - 实际上就是将外部的遍历的逻辑放到的对象的递归调用里面,
这个思想在许多场景里面是非常有用, 因为对象是可以多态的, 每一个态的具体处理逻辑又可以不同,但整体逻辑又是相同, 所以最终所以所组合出来的逻辑分支数量是指数级的, 如果不做这样的处理全部放到外部遍历处理就会产生大量的嵌套的if else分支处理逻辑。 - 当然迭代器模式主要用于
数据的迭代, 通过创建不同的迭代器可以将不同数据的不同迭代里逻辑独立出来, 比如这里就是一个场景, 还有一些复杂的数据结构图和树等存在各种什么深度、广度遍历、前序遍历逻辑都可以创建不同的迭代器去处理。所以如果你的业务数据有自己的不同的迭代逻辑就可以使用此模式去处理。 - 很多人固定认为迭代器与集合绑定就是对集合的处理, 但这只是广义上所谓的"集合"。
本质是对数据的迭代, 这个数据可以是任何东西 - 基于此思想可以去扩展其他不同的属性逐级分词处理逻辑
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结