您现在的位置是:首页 >学无止境 >大数据系列——Hive理论网站首页学无止境
大数据系列——Hive理论
概述
Hive是一个数据仓库管理工具,将结构化的数据文件映射为一张数据库表,并提供类SQL(HQL)查询功能。由Facebook实现并开源,最后捐赠给Apache发展为顶级项目。
以RDBMS数据库为元数据存储服务,
以Hadoop HDFS来存储数据,
以MapReduce(默认)、Tez、Spark为计算引擎来计算其所辖的数据,
以Zookeeper(或同等应用)作为其分布式协调服务,实现高可用。
主要用来存储结构化数据,适应读多写少的应用场景,仅仅支持select、insect(实际为追加append),不支持delete、update。
下面从如下几个方面介绍下其相关理论:
架构
核心知识点
部署方式
优缺点分析
常见应用场景
调优经验
API应用
一、架构
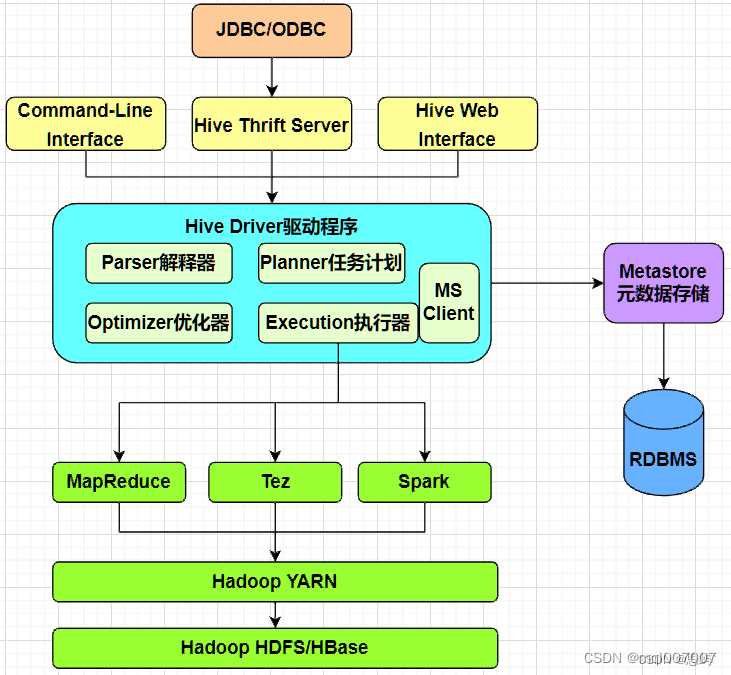
二、核心知识点
Hive拥有类似于RDBMS数据库的表,其相应元数据也存储在RDBMS数据库中,但其内部与RDBMS数据库有很大不同,详见下图:
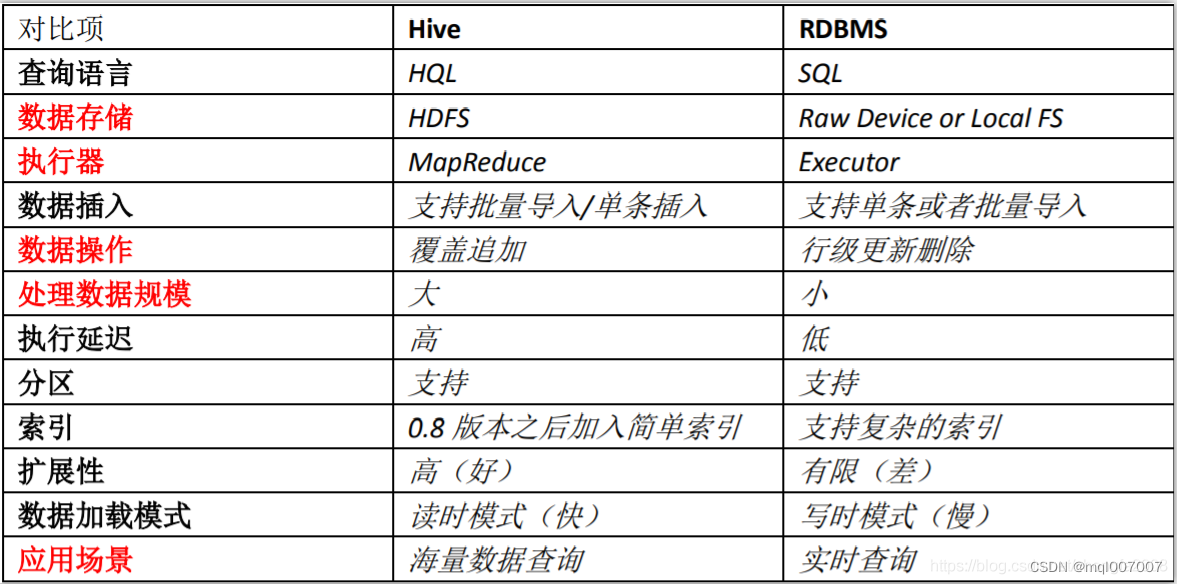
1、数据模型
1.1、Hive有下面一些数据类型,详见下图:

Hive不支持日期类型,在Hive里日期都是用字符串来表示的,而常用的日期格式转化操作则是通过自定义函数进行操作。
Hive是用Java开发的,Hive里的基本数据类型和Java的基本数据类型也是一一对应的,
STRING类型对应Java的string类型,该类型相当于数据库的varchar类型,是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
有符号的整数类型:TINYINT、SMALLINT、INT和BIGINT分别等价于Java的byte、short、int和long原子类型,它们分别为1字节、2字节、4字节和8字节有符号整数。
浮点数据类型FLOAT和DOUBLE,对应于Java的基本类型float和double类型。
BOOLEAN类型相当于java的基本数据类型boolean。
Hive有三种复杂数据类型 ARRAY、MAP 和 STRUCT(结构体)。ARRAY 和 MAP 与 Java 中的 Array 和 Map 类似,而STRUCT 与 C语言中的 Struct 类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
复杂数据类型的声明必须使用尖括号指明其中数据字段的类型。定义三列,每列对应一种复杂的数据类型,如下所示。
CREATE TABLE complex(
col1 ARRAY< INT>,
col2 MAP< STRING,INT>,
col3 STRUCT< a:STRING,b:INT,c:DOUBLE>
)
1.2、Hive的存储结构包括数据库、表、外部表、视图:
数据库(database):在 HDFS 中表现为${hive.metastore.warehouse.dir}目录下一个文件夹。
表(table):在 HDFS 中表现所属 database 目录下一个文件夹。具体可包括分区表(partition)、桶(bucket)
分区表(partition):在 HDFS 中表现为 table 目录下的子目录。
桶(bucket): 在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散 列之后的多个文件。
外部表(external table):与 table 类似,不过其数据存放位置可以指定任意 HDFS 目录路径。
视图(view):与传统数据库类似,只读,基于基本表创建。
1.3、Hive的数据文件存储格式:
Hive中没有定义专门的数据格式,数据格式由用户指定,列分隔符(通常为空格、" "、"x001")、行分隔符(" "),具体文件格式有Textfile、SequenceFile、RCFile、ORCFile、Parquet、Avro。
Textfile(行式存储)
文本格式,Hive的默认格式,数据不压缩,磁盘开销大、数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
对应的hive API为:org.apache.hadoop.mapred.TextInputFormat和org.apache.hive.ql.io.HiveIgnoreKeyTextOutputFormat
SequenceFile(行式存储)
Hadoop提供的一种二进制文件格式是Hadoop支持的标准文件格式(其他生态系统并不适用),可以直接将对序列化到文件中,所以sequencefile文件不能直接查看,可以通过Hadoop fs -text查看。具有使用方便,可分割,可压缩,可进行切片。
压缩支持NONE, RECORD, BLOCK(优先)等格式,可进行切片。
对应hive API为:org.apache.hadoop.mapred.SequenceFileInputFormat和org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
RCFile(列式存储)
是一种行列存储相结合的存储方式,先将数据按行进行分块再按列式存储,保证同一条记录在一个块上,避免读取多个块,有利于数据压缩和快速进行列存储。
对应的hive API为:org.apache.hadoop.hive.ql.io.RCFileInputFormat和org.apache.hadoop.hive.ql.io.RCFileOutputFormat
ORCFile(列式存储)
orcfile是对rcfile的优化,可以提高hive的读写、数据处理性能,提供更高的压缩效率(目前主流选择之一)。
Parquet(列式存储)
可提供对其他 hadoop 工具的可移植性, 包括Hive, Drill, Impala, Crunch, and Pig
对应的hive API为:org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat和org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
Avro
Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理Avro数据。
对应的hive API为:org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat和org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat
Hive元数据信息存储在Hive MetaStore中,如文件路径、文件格式、列、数据类型、分隔符,Hive默认的分格符有三种,分别是A(Ctrl+A)、B和^C,即ASCii码的1、2和3,分别用于分隔列,分隔列中的数组元素,和元素Key-Value对中的Key和Value。
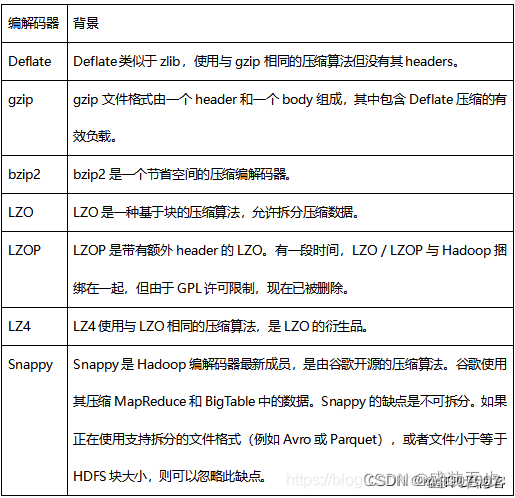
1.4、常用的压缩编解码器如下表:
2、元数据存储及服务
2.1、Metadata即元数据
Hive将元数据存储在RDBMS数据库中,如Derby、MySQL等。
Hive中的元数据包括(表名、表所属的数据库名、 表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等)。
2.2、Metastore
Metastore服务: 用于客户端连接metastore服务,metastore再去连接RDBMS(例如:MySQL)数据库来存取元数据。
有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道RDBMS数据库的用户名和密码,只需要连接metastore服务即可。
3、Thriftserver
是一个软件框架服务,允许客户端使用包括Java、C++、Ruby和其他很多种语言,通过编程的方式远程访问Hive。
Thrift 是 Facebook 开发的一个软件框架,可以用来进行可扩展且跨语言的服务的开发, Hive 集成了该服务,能让不同的编程语言调用 Hive 的接口。
通过hiveServer/hiveServer2启动Thrift服务,客户端连接Thrift服务访问Hive数据库
4、Hive Driver驱动器
Driver 驱动器主要完成 HQL 查询语句从词法分析,语法分析,编译,优化,以及生成逻辑执行计划,生成的逻辑执行计划存储在 HDFS 中,并随后由计算引擎( MapReduce、Tez、Spark)来调用执行。
Hive 的核心是驱动引擎, 驱动引擎由四部分组成具体包括,解析器、编译器、优化器、执行器。
4.1、解析器(SQL Parser)
将 SQL 字符串转换成抽象语法树 AST,对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误
4.2、编译器(Physical Plan)
将 AST 编译生成逻辑执行计划,具体对HQL语句进行词法、语法、语义的编译(需要跟元数据关联),编译完成后会生成一个逻辑执行计划,具体依赖计算引擎( MapReduce、Tez、Spark)
4.3、优化器(Query Optimizer):
对逻辑执行计划进行优化,减少不必要的列、使用分区、使用索引等
4.4、执行器(Execution):
执行器是将逻辑执行计划转化为相应的物理执行计划,依赖具体的计算引擎( MapReduce、Tez、Spark),然后调用底层的调度框架(YARN)来执行转换后的物理计划
5、用户接口
5.1、CLI:是指Shell命令行,Hive命令行模式
进入hive安装目录,输入bin/hive的执行程序,或者输入 hive –service cli,用于linux平台命令行查询,查询语句基本跟mysql查询语句类似
5.2、Hive 远程服务 (端口号10000) 启动方式 (Thrift服务),通过JDBC/ODBC或beeline进行操作, 与传统数据库JDBC和ODBC类似。
bin/hive –service hiveserver2 &(&表示后台运行)
直接连接HiveServer2服务,通过JDBC/ODBC进行访问Hive,可支持多种语言,包括java、C#、Python等
5.3、WebUI:是指可通过浏览器访问Hive
Hive 2.0 以后才支持Web UI的
bin/hive –service hwi (& 表示后台运行)
用于通过浏览器来访问hive,浏览器访问地址是:IP:端口/hwi
6、计算引擎
Hive目前支持三种计算引擎,MapReduce(默认)、Spark、Tez;
基于Spark引擎,目前Spark和Hive有下面三种应用方式:
6.1、Hive on Spark:
用户侧基于HQL提交数据处理逻辑,然后在内部再转换成Spark任务进行处理,计算执行流程采用Spark的执行流程。
6.2、Spark on Hive:
用户侧基于Spark Sql 或 Spark API提交数据处理逻辑,然后直接操作Hive进行数据处理,计算执行流程采用Spark的执行流程。
6.3、Spark on Spark Hive Catelog:
用户侧基于Spark Sql 或 Spark API提交数据处理逻辑,然后直接依赖Hive Catelog扩展的逻辑进行数据处理,计算执行流程采用Spark的执行流程。
7、计算执行调度
Hive提交的数据处理逻辑,不管计算引擎采用那种方式,执行计算任务的调度都由Hadoop的调度组件Yarn来调度。
8、数据存储
Hive的数据既可以存储在HDFS,也可以存储在Hbase(底层还是存储在HDFS),因为Hive提供的HQL操作的便利性,一般应用为了方便数据的处理,都会和Hive进行集成一起实现业务场景要求。
因为Hive主要用于大数据量的离线数据计算分析,数据都是不变的,一般都是存储在HDFS上的数据。
9、作业执行流程
具体作业执行流程,依赖具体的计算引擎,下面列举一下MR计算引擎的作业流程:
9.1、用户提交查询等任务给Driver
9.2、驱动程序将Hql发送编译器,检查语法和生成查询计划
9.3、编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
9.4、编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树 转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划 (MapReduce), 最后选择最佳的策略。
9.5、将最终的计划提交给Driver。到此为止,查询解析和编译完成。
9.6、Driver将计划Plan转交给ExecutionEngine去执行。
在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它 分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作。
与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。
执行引擎接收来自数据节点的结果;执行引擎发送这些结果值给驱动程序;驱动程序将结果发送给Hive接口。
10、HQL(Hive Sql相关知识)
Hive Sql详细内容比较多,下面从几个大的分类来简要列举下相关概念,具体语法推荐参考下面一些网友的整理。
10.1、SQL 基础操作
筛选指定字段
DISTINCT 去重
CASE 条件赋值
Where 条件查询
标量子查询
ORDER BY 排序
Hive SQL 数据排序
AND, OR 和 NOT 逻辑连接
LIMIT 和 OFFSET 限制结果数量
10.2、SQL 高级操作
常用聚合统计函数
GROUP BY 数据分组
聚合统计函数
Hive SQL 的操作及运算
Hive SQL 语句的执行顺序
Hive SQL 语句设置参数变量
TABLESAMPLE 查询样本
LateralView 行转列
SQL 多表查询
JOIN 连接查询
UNION 数据拼接
WITH AS 临时中间表
10.3、窗口计算
SQL 窗口计算
SQL 移动窗口
Hive sql 专用窗口函数
10.4、多维度分析
多维度分析 CUBE
指定维度 Grouping Sets
按层级聚合 With Rollup
多维分组标记 Grouping ID
Grouping 函数
10.5、Hive SQL 函数介绍
Hive SQL 函数
数学计算函数
分组聚合函数
collect_list 和 collect_set 函数
ntile 分组切片函数
集合函数
类型转换函数
时间日期函数
条件函数
if 条件
字符处理函数
表生成函数(UDTF)
XPath 解析
详细参见下面一些整理,比较详细。
三、部署方式
1、内嵌模式 Local/Embedded Metastore Database (Derby)
元数据存储在内置的derby数据库中;
不需要单独配置metastore,也不需要单独启动metastore服务;
Derby数据库和metastore服务都嵌入在主HiveServer进程中,当启动HiveServer进程时,Derby和metastore都会启动;
每次只能支持一个活动用户,不能多个实例同时访问DB(即支持并发),没启动;
适用于测试体验,不适用于生产环境;
2、本地模式 Remote Metastore Database
元数据使用外置的RDBMS,常见的是MySQL数据库;
不需要单独配置metastore, 也不需要单独启动metastore服务;
Hive Metastore服务与主HiveServer在同一进程中运行,但是存储元数据的数据库在单独的进程中运行,并且可以在单独的主机上,metastore服务将通过JDBC与metastore数据库进行通信;
每一个用户必
须要有对元数据数据库metastore的访问权限,即每一个客户端使用者需要知道访问的用户名和密码才行,需要暴露metastore数据库用户和metastore服务;
Hive根据hive.metastore.uris 参数值来判断,如果为空,则为本地模式或者hive.metastore.local设置为true;
每启动一次hive服务,都内置启动了一个metastore服务,如果使用多个客户端进行访问,就需要有多个Hiveserver服务,此时会启动多个Metastore可能出现资源竞争现象;
适用于公司内部同时使用Hive的环境或运维测试集群环境搭建过程,不适用于生产环境;
3、远程模式 Remote Metastore Server (带HA的集群模式)
Metastore服务在其自己的单独JVM中运行,位于独立的进程;
HiveServer也在自己的单独JVM中运行,位于独立的进程;
该模式需要将hive.metastore.local设置为false,将hive.metastore.uris设置为metastore服务器URL,如果有多个metastore服务器,将URL之间用逗号分隔,metastore服务器URL的格式为:thrift://ip:port,...;
需要独立启动Metastore服务和HiveServer服务;客户端直接对接HiveServer2服务,不需要关心HiveServer、Metastore服务、metastore元数据数据库;
可以配置协同管理应用实现高可用(HA),例如:配置Zookeeper来实现高可用,实际本质是通过Zookeeper来协同管理HiveServer2提供实例来实现的。
适用于生产环境,具有下面一些优势:
a. 在应用端不用部署Hadoop和Hive客户端;
b. 相比hive-cli方式,HiveServer2不用直接将HDFS、Metastore服务、Metadata元数据库暴漏给用户;
c. 有安全认证机制,并且支持自定义权限校验;
d. 有HA机制,解决应用端的并发和负载均衡问题;
e. JDBC方式,可以使用任何语言,方便与应用进行数据交互;
f. 从2.0开始,HiveServer2提供了WEB UI。
四、优缺点分析
1、缺点
a、Hive的HQL表达能力有限
b、迭代式算法无法表达
c、Hive的效率比较低,查询延迟很严重
d、Hive自动生成的MapReduce作业,通常情况下不够智能化
e、Hive调优比较困难,粒度较粗
f、不支持事务,不支持记录级别的增删改操作
2、优点:
a、提供了统一的元数据管理,可宿主在不同的RDBMS系统中
b、操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
c、避免了人工去写MapReduce,减少开发人员的学习成本
d、Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合
e、Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高
f、Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
g、支持横向扩展(Scale-out),可自由的扩展集群规模
h、可集成不同的计算引擎来实现计算服务,支持MR(默认)、Tez、Spark
i、可集成HDFS或Hbase作为存储,分别实现不同数据计算及管理应用
j、支持成熟的JDBC和ODBC驱动程序,用于ETL和BI应用处理
k、有庞大活跃的社区
五、常见应用场景
1、大数据离线分析
分析大量的埋点日志,例如:用户网上行为日志,统计时间段内的pv、uv数量、销售分析、广告点击分析等;
分析大量的设备采集数据,例如:传感器;
分析大量的商品订单数据,依据大量的订单数据,划分不同的分析维度,来达到预期目的;
2、数据仓库
加载大数据量的格式化文本数据进入数据库仓库用于分析,例如:加载用户信息及其上网行为数据到数据仓库,经过分析运算描绘出用户画像;
加载大数据量的业务数据,按时间维度落入数据仓库,用于决策分析,例如:加载订单信息,经过维度计算得出用户的购买趋势及喜好;
3、商业智能及数据挖掘
加载所有的历史数据,通过不同的观测维度来计算可能的发展趋势,用于提供领导决策,进而影响公司业务和战略。
4、其他一些基础应用
实现商品信息的行列互换;
Top N排名(基于窗口函数实现);
多维度分析事实数据;
......
六、调优经验
PS:后续逐渐把实践调优过程补充上来
七、API应用:
各个平台一般都有相应的操作组件,下面介绍下java和DoNet平台下的访问组件。
java平台:
1、走JDBC通道,加入如下依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>版本</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>版本</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>版本</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>版本</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>版本</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>版本</version>
</dependency>
DoNet平台:
走ODBC通道






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结