您现在的位置是:首页 >技术交流 >08- 算法解读 Mask R-CNN (目标检测)网站首页技术交流
08- 算法解读 Mask R-CNN (目标检测)
要点:
- Mask R-CNN 解读
参考资料:vision/references/detection at main · pytorch/vision · GitHub
四 Mask R-CNN 基本信息
4.1 环境配置
- Python3.6/3.7/3.8
- Pytorch1.10或以上
- pycocotools(Linux:
pip install pycocotools; Windows:pip install pycocotools-windows(不需要额外安装vs)) - 最好使用GPU训练
- 详细环境配置见
requirements.txt
4.2 文件结构
├── backbone: 特征提取网络
├── network_files: Mask R-CNN网络
├── train_utils: 训练验证相关模块(包括coco验证相关)
├── my_dataset_coco.py: 自定义dataset用于读取COCO2017数据集
├── my_dataset_voc.py: 自定义dataset用于读取Pascal VOC数据集
├── train.py: 单GPU/CPU训练脚本
├── train_multi_GPU.py: 针对使用多GPU的用户使用
├── predict.py: 简易的预测脚本,使用训练好的权重进行预测
├── validation.py: 利用训练好的权重验证/测试数据的COCO指标,并生成record_mAP.txt文件
└── transforms.py: 数据预处理(随机水平翻转图像以及bboxes、将PIL图像转为Tensor)
4.3 预训练权重下载地址
(下载后放入当前文件夹中)
-
Resnet50 预训练权重 https://download.pytorch.org/models/resnet50-0676ba61.pth (注意,下载预训练权重后要重命名, 比如在train.py中读取的是
resnet50.pth文件,不是resnet50-0676ba61.pth) -
Mask R-CNN(Resnet50+FPN) 预训练权重 https://download.pytorch.org/models/maskrcnn_resnet50_fpn_coco-bf2d0c1e.pth (注意, 载预训练权重后要重命名,比如在train.py中读取的是
maskrcnn_resnet50_fpn_coco.pth文件,不是maskrcnn_resnet50_fpn_coco-bf2d0c1e.pth)
4.4 数据集
本例程使用的有COCO2017数据集和Pascal VOC2012数据集。
COCO2017数据集
-
COCO官网地址:COCO - Common Objects in Context
-
对数据集不了解的可以看我们课程之前讲的COCO数据集介绍
-
这里以下载coco2017数据集为例,主要下载三个文件:
-
2017 Train images [118K/18GB]:训练过程中使用到的所有图像文件 -
2017 Val images [5K/1GB]:验证过程中使用到的所有图像文件 -
2017 Train/Val annotations [241MB]:对应训练集和验证集的标注json文件
-
-
都解压到
coco2017文件夹下,可得到如下文件夹结构:
├── coco2017: 数据集根目录
├── train2017: 所有训练图像文件夹(118287张)
├── val2017: 所有验证图像文件夹(5000张)
└── annotations: 对应标注文件夹
├── instances_train2017.json: 对应目标检测、分割任务的训练集标注文件
├── instances_val2017.json: 对应目标检测、分割任务的验证集标注文件
├── captions_train2017.json: 对应图像描述的训练集标注文件
├── captions_val2017.json: 对应图像描述的验证集标注文件
├── person_keypoints_train2017.json: 对应人体关键点检测的训练集标注文件
└── person_keypoints_val2017.json: 对应人体关键点检测的验证集标注文件夹
Pascal VOC2012数据集
-
数据集下载地址: The PASCAL Visual Object Classes Challenge 2012 (VOC2012)
-
对数据集不了解的可以看我们课程之前讲的Pascal VOC2012数据集介绍.
-
解压后得到的文件夹结构如下:
VOCdevkit
└── VOC2012
├── Annotations 所有的图像标注信息(XML文件)
├── ImageSets
│ ├── Action 人的行为动作图像信息
│ ├── Layout 人的各个部位图像信息
│ │
│ ├── Main 目标检测分类图像信息
│ │ ├── train.txt 训练集(5717)
│ │ ├── val.txt 验证集(5823)
│ │ └── trainval.txt 训练集+验证集(11540)
│ │
│ └── Segmentation 目标分割图像信息
│ ├── train.txt 训练集(1464)
│ ├── val.txt 验证集(1449)
│ └── trainval.txt 训练集+验证集(2913)
│
├── JPEGImages 所有图像文件
├── SegmentationClass 语义分割png图(基于类别)
└── SegmentationObject 实例分割png图(基于目标)
4.5 训练方法
- 确保提前准备好数据集
- 确保提前下载好对应预训练模型权重
- 确保设置好
--num-classes和--data-path - 若要使用单GPU训练直接使用 train.py 训练脚本
- 若要使用多GPU训练,使用
torchrun --nproc_per_node=8 train_multi_GPU.py指令,nproc_per_node参数为使用GPU数量 - 如果想指定使用哪些GPU设备可在指令前加上
CUDA_VISIBLE_DEVICES=0,3(例如我只要使用设备中的第1块和第4块GPU设备) CUDA_VISIBLE_DEVICES=0,3 torchrun --nproc_per_node=2 train_multi_GPU.py
4.6 注意事项
-
在使用训练脚本时,注意要将
--data-path设置为自己存放数据集的根目录:
# 假设要使用COCO数据集,启用自定义数据集读取CocoDetection并将数据集解压到成/data/coco2017目录下
python train.py --data-path /data/coco2017
# 假设要使用Pascal VOC数据集,启用自定义数据集读取VOCInstances并数据集解压到成/data/VOCdevkit目录下
python train.py --data-path /data/VOCdevkit-
如果倍增
batch_size,建议 学习率也跟着倍增。假设将batch_size从4设置成8,那么学习率lr从0.004设置成0.008 -
如果使用 Batch Normalization 模块时,
batch_size不能小于4,否则效果会变差。如果显存不够,batch_size必须小于4时,建议在创建resnet50_fpn_backbone时, 将norm_layer设置成FrozenBatchNorm2d或将trainable_layers设置成0(即冻结整个backbone) -
训练过程中保存的
det_results.txt(目标检测任务)以及seg_results.txt(实例分割任务)是每个epoch在验证集上的COCO指标,前12个值是COCO指标,后面两个值是训练平均损失以及学习率 -
在使用预测脚本时,要将
weights_path设置为你自己生成的权重路径。 -
使用 validation 文件时,注意确保你的验证集或者测试集中必须包含每个类别的目标,并且使用时需要修改
--num-classes、--data-path、--weights-path以及--label-json-path(该参数是根据训练的数据集设置的)。其他代码尽量不要改动
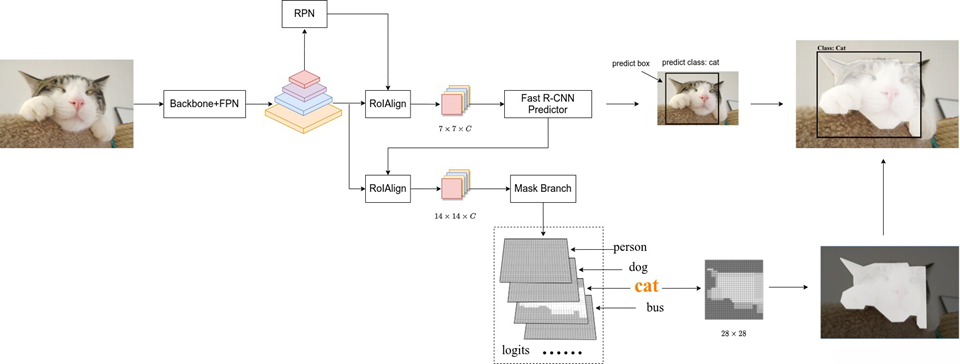
4.7 Mask R-CNN 图解




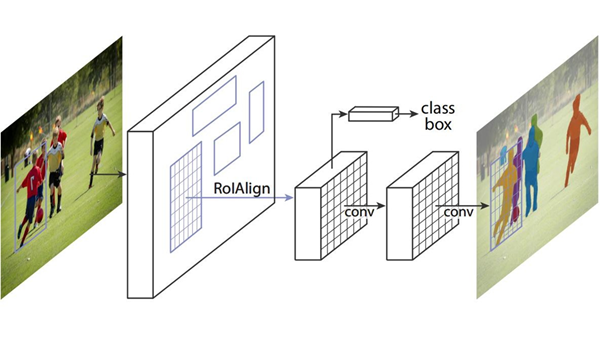
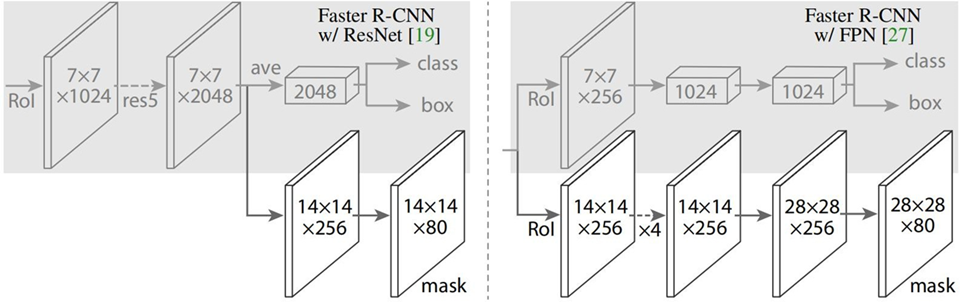
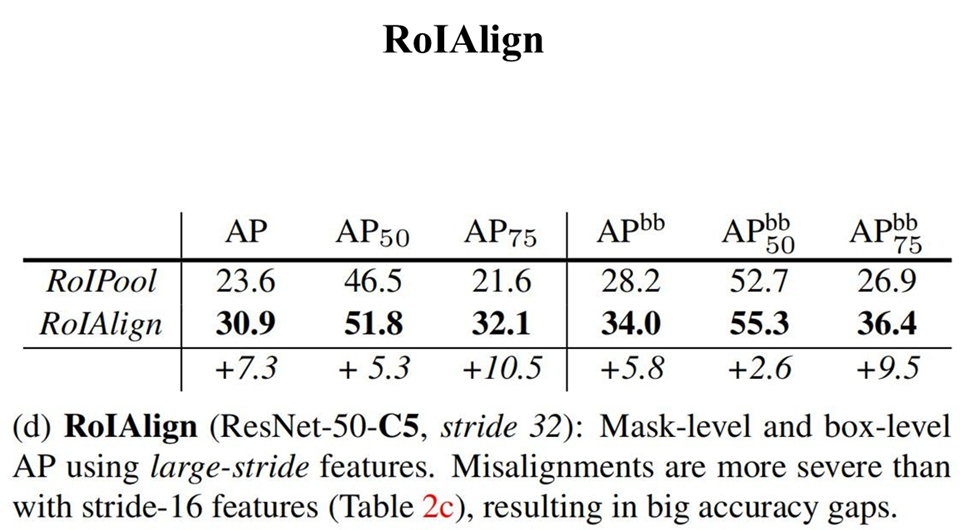
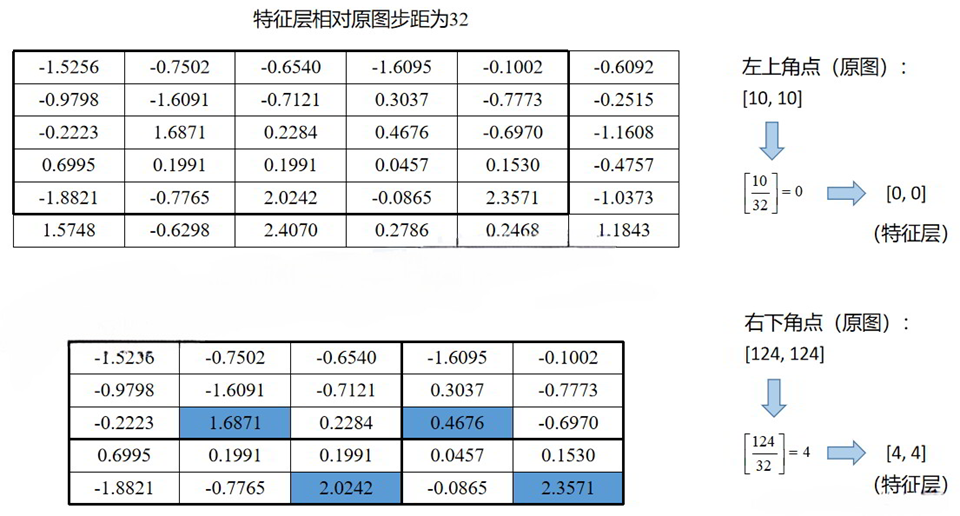
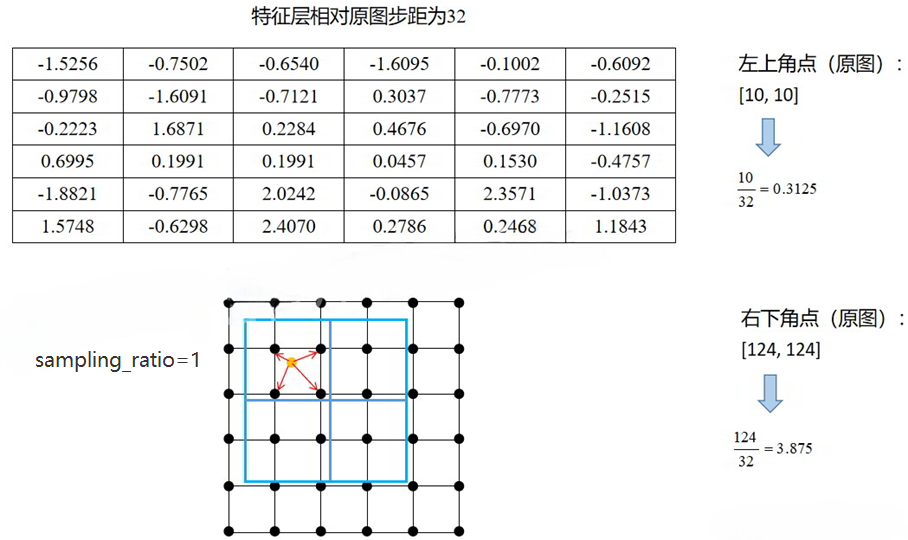
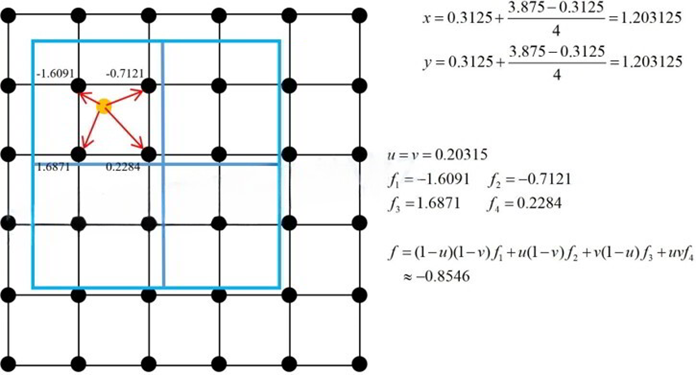
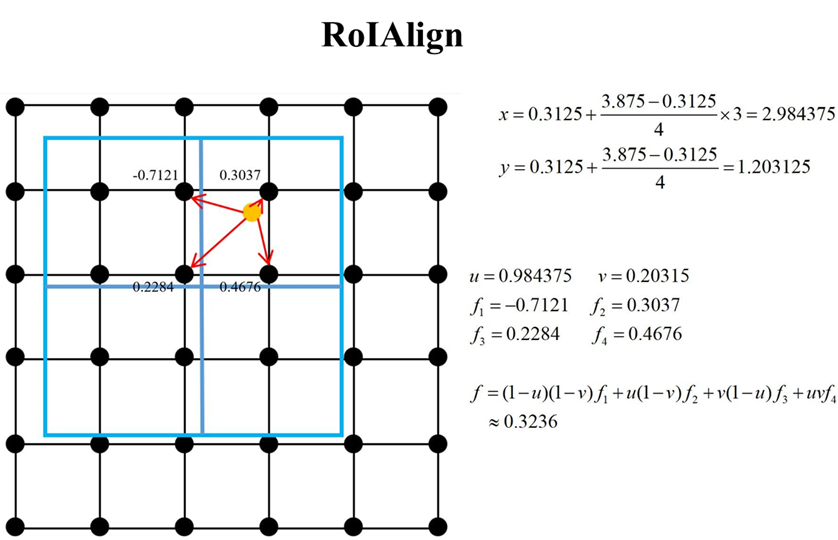
4.8 MASK 分支


4.9 Mask R-CNN 损失

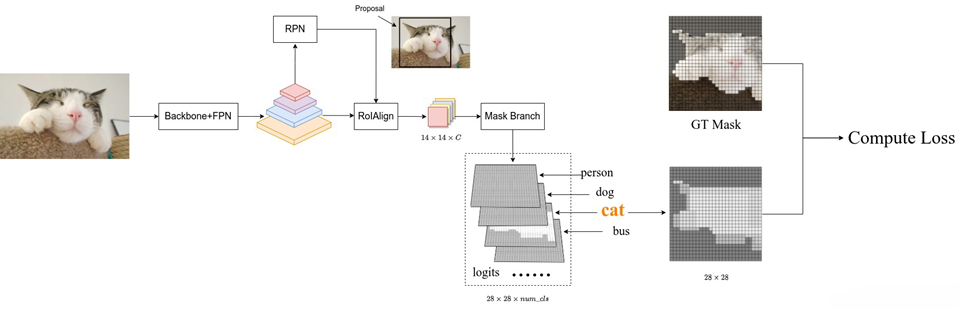






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结