您现在的位置是:首页 >其他 >大模型高效调参—PEFT库( Parameter-Efficient Fine-Tuning)网站首页其他
大模型高效调参—PEFT库( Parameter-Efficient Fine-Tuning)
介绍
在面对特定的下游任务时,如果进行Full FineTuning(即对预训练模型中的所有参数都进行微调),太过低效;而如果采用固定预训练模型的某些层,只微调接近下游任务的那几层参数,又难以达到较好的效果。
PEFT(Parameter-Efficient Fine-Tuning)是一个用于在不微调所有模型参数的情况下,有效地将预先训练的语言模型(PLM)适应各种下游应用的库。PEFT方法只微调少量(额外)模型参数,显著降低了计算和存储成本,因为微调大规模PLM的成本高得令人望而却步。最近最先进的PEFT技术实现了与完全微调相当的性能。
大模型训练的微调方法,包括prompt tuning、prefix tuning、LoRA、p-tuning和AdaLoRA等。
Adapter Tuning
谷歌的研究人员首次在论文《Parameter-Efficient Transfer Learning for NLP》提出针对 BERT 的 PEFT 微调方式,拉开了 PEFT 研究的序幕。下图所示的 Adapter 结构,将其嵌入 Transformer 的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的 Adapter 结构进行微调。
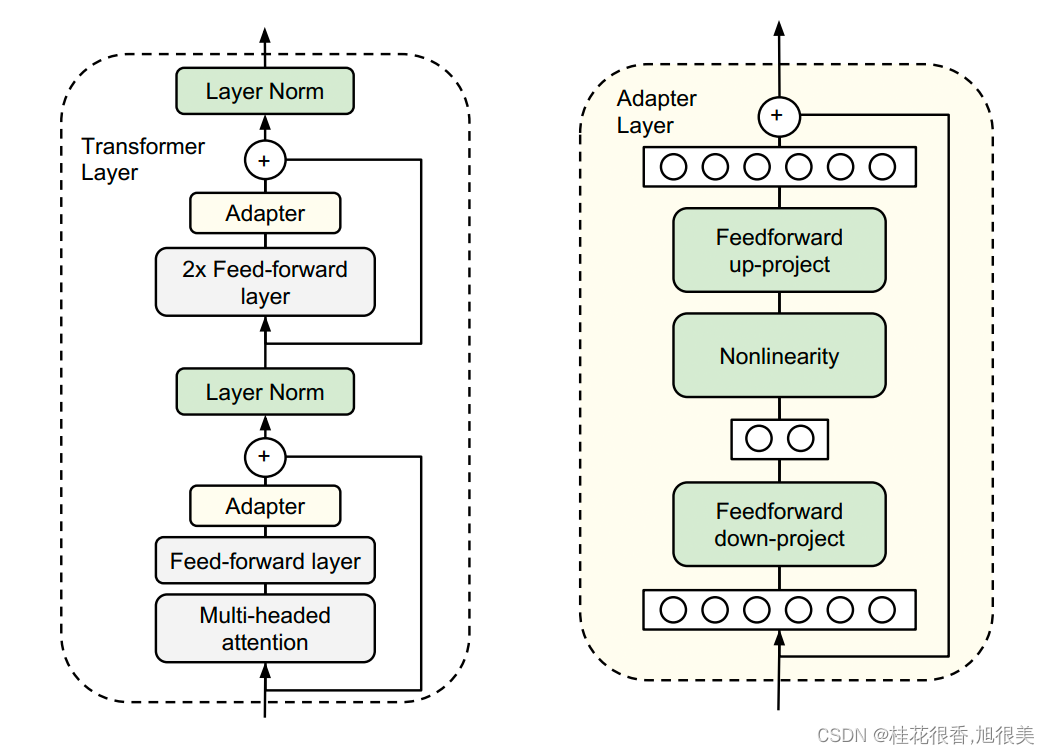
首先是一个 down-project 层将高维度特征映射到低维特征,然后过一个非线形层之后,再用一个 up-project 结构将低维特征映射回原来的高维特征;同时也设计了 skip-connection 结构,确保了在最差的情况下能够退化为 identity。
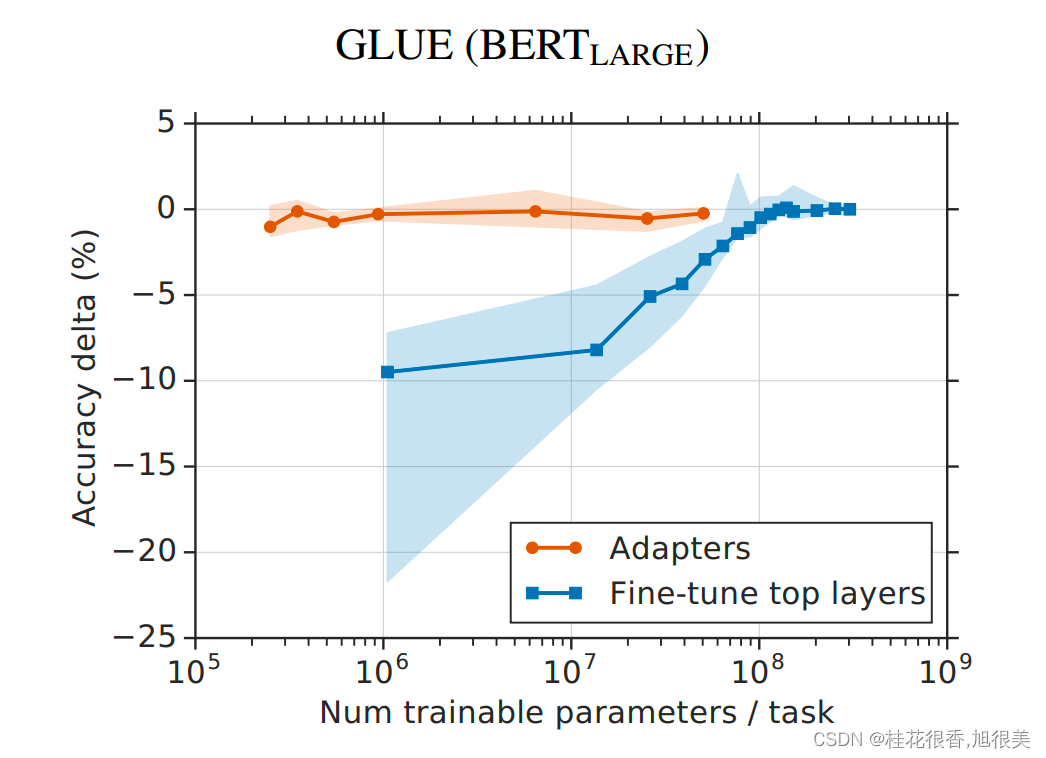
从实验结果来看,该方法能够在只额外对增加的 3.6% 参数规模(相比原来预训练模型的参数量)的情况下取得和 Full-finetuning 接近的效果(GLUE 指标在 0.4% 以内)。
Prefix Tuning
在输入 token 之前构造一段任务相关的 virtual tokens 作为 Prefix,然后训练的时候只更新 Prefix 部分的参数,而 Transformer 中的其他部分参数固定。,学习到的前缀指令文本向量可以挖掘大模型的潜力去引导模型完成特定任务。
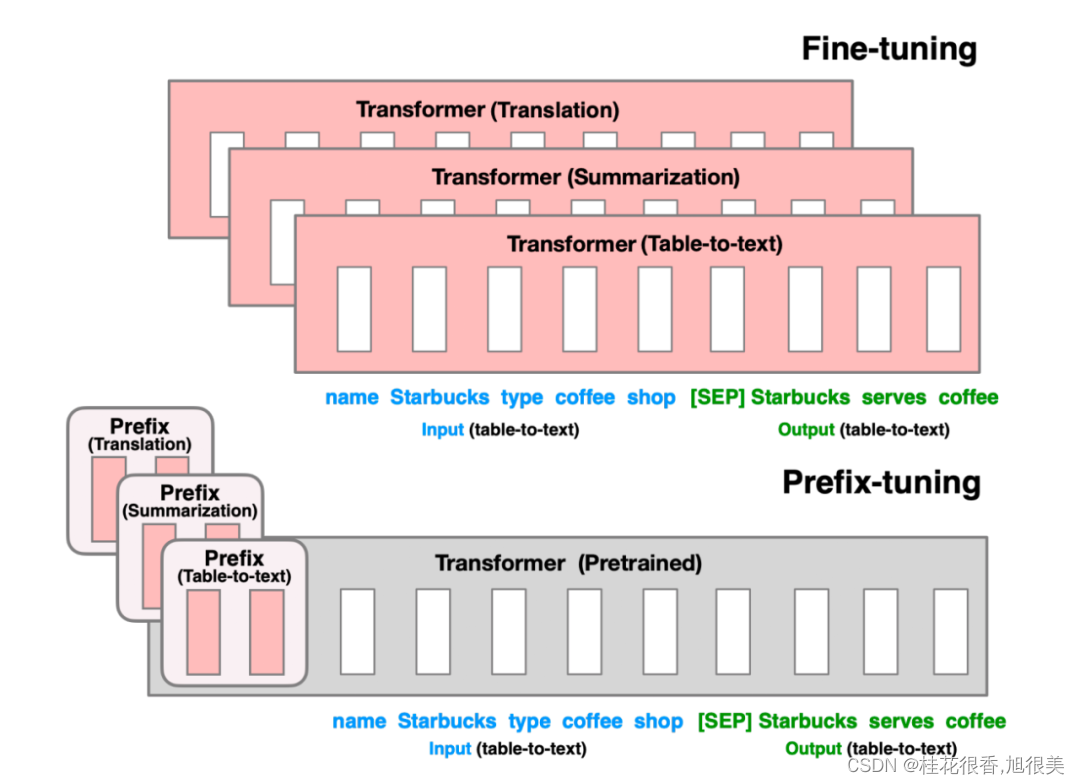
Prefix Tuning 和构造 Prompt 类似,只是 Prompt 是人为构造的“显式”的提示,并且无法更新参数,而 Prefix 则是可以学习的“隐式”的提示。
同时,为了防止直接更新 Prefix 的参数导致训练不稳定的情况,在 Prefix 层前面加了 MLP 结构(相当于将 Prefix 分解为更小维度的 Input 与 MLP 的组合后输出的结果),训练完成后,只保留 Prefix 的参数。
embedding = torch.nn.Embedding(num_virtual_tokens, token_dim)
transform = torch.nn.Sequential(
torch.nn.Linear(token_dim, encoder_hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(encoder_hidden_size, num_layers * 2 * token_dim),
)
PREFIX_TUNING 需要设置一个参数,即 指令文本的长度 num_virtual_tokens,研究表明这个数量一般设置在10-20之间。不同的任务所需要的 Prefix 的长度有差异。
```python
model_name_or_path = "./unsup-simcse-roberta-base"
peft_type = PeftType.PREFIX_TUNING
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
lr = 1e-2
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
Prompt Tuning
论文《The Power of Scale for Parameter-Efficient Prompt Tuning》
只要模型规模够大,简单加入 Prompt tokens 进行微调,就能取得很好的效果。
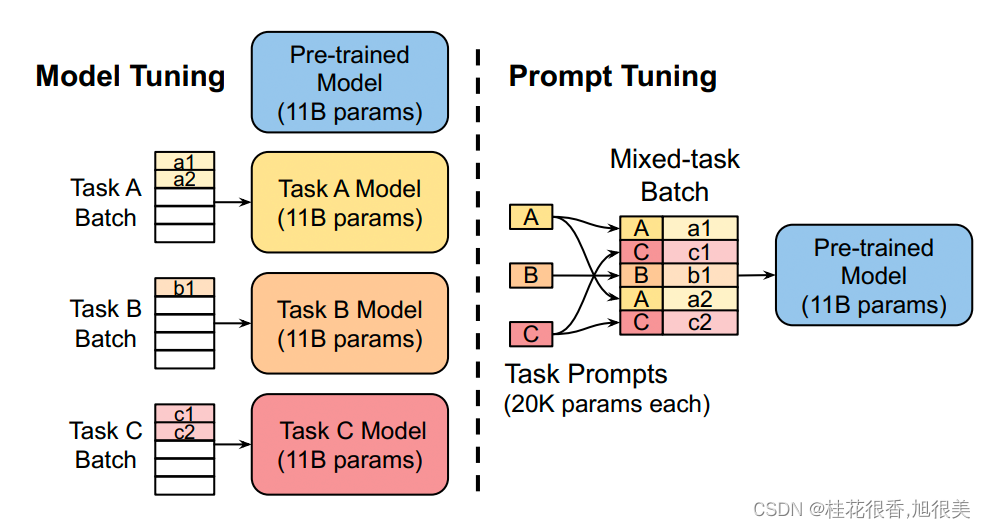
固定预训练参数,为每一个任务额外添加一个或多个embedding,之后拼接query正常输入LLM,并只训练这些embedding。左图为单任务全参数微调,右图为prompt tuning。
实验

- (a) Prompt 长度影响:模型参数达到一定量级时,Prompt 长度为 1 也能达到不错的效果,Prompt 长度为 20 就能达到极好效果。
- (b) Prompt 初始化方式影响:Random Uniform 方式明显弱于其他两种,但是当模型参数达到一定量级,这种差异也不复存在。
- © 预训练的方式:LM Adaptation 的方式效果好,但是当模型达到一定规模,差异又几乎没有了。
- (d) 微调步数影响:模型参数较小时,步数越多,效果越好。同样随着模型参数达到一定规模,zero shot 也能取得不错效果。
文章表明随着模型越大,PROMPT_TUNING 的效果几乎能和模型整个微调的效果一样。形成了只是学习一个指令然后去模型中检索某种能力的范式。
from peft import PromptTuningConfig, get_peft_model
model_name_or_path = "./unsup-simcse-roberta-base"
peft_type = PeftType.PROMPT_TUNING
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
lr = 1e-3
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
https://huggingface.co/docs/peft/conceptual_guides/prompting
P-Tuning V1
P-Tuning 方法的提出主要是为了解决这样一个问题:大模型的 Prompt 构造方式严重影响下游任务的效果。

P-Tuning 提出将 Prompt 转换为可以学习的 Embedding 层,只是考虑到直接对 Embedding 参数进行优化会存在这样两个挑战:
- Discretenes:对输入正常语料的 Embedding 层已经经过预训练,而如果直接对输入的 prompt embedding 进行随机初始化训练,容易陷入局部最优
- Association:没法捕捉到 prompt embedding 之间的相关关系。

手动尝试最优的提示无异于大海捞针,于是便有了自动离散提示搜索的方法(左图),但提示是离散的,神经网络是连续的,所以寻找的最优提示可能是次优的。p-tuning依然是固定LLM参数,利用多层感知机和LSTM对prompt进行编码,编码之后与其他向量进行拼接之后正常输入LLM。注意,训练之后只保留prompt编码之后的向量即可,无需保留编码器。
作者在这里提出用 MLP+LSTM 的方式来对 prompt embedding 进行一层处理
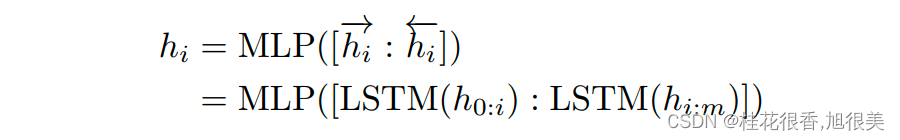
需要提醒的是这里的指令文本是伪文本,可能就是 unused1, unused2…等,目前源代码里面就是随机初始化的一个embeding.
self.lstm_head = torch.nn.LSTM(
input_size=self.input_size,
hidden_size=self.hidden_size,
num_layers=num_layers,
dropout=lstm_dropout,
bidirectional=True,
batch_first=True,
)
self.mlp_head = torch.nn.Sequential(
torch.nn.Linear(self.hidden_size * 2, self.hidden_size * 2),
torch.nn.ReLU(),
torch.nn.Linear(self.hidden_size * 2, self.output_size),
)
self.mlp_head(self.lstm_head(input_embeds)[0])
以上代码可清晰展示出prompt encoder的结构。
P-Tuning V1 与 Prefix-Tuning 的区别:
- Prefix Tuning 是将额外的 embedding 加在开头,看起来更像是模仿 Instruction 指令;而 P-Tuning 的位置则不固定。
- Prefix Tuning 通过在每个 Attention 层都加入 Prefix Embedding 来增加额外的参数,通过 MLP 来初始化;而 P-Tuning 只是在输入的时候加入 Embedding,并通过 LSTM+MLP 来初始化。
from peft import PromptTuningConfig, get_peft_model
model_name_or_path = "./unsup-simcse-roberta-base"
peft_type = PeftType.P_TUNING
lr = 1e-3
peft_config = PromptEncoderConfig(task_type="CAUSAL_LM", num_virtual_tokens=20, encoder_hidden_size=128)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
P-Tuning V2
论文《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》
P-Tuning v2 的目标就是要让 Prompt Tuning 能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌 Fine-tuning 的结果。
Prompt Tuning 方法可能在这两个方面都存在局限性:
- 不同模型规模:Prompt Tuning 和 P-tuning 这两种方法都是在预训练模型参数规模够足够大时,才能达到和 Fine-tuning 类似的效果,而参数规模较小时效果则很差。
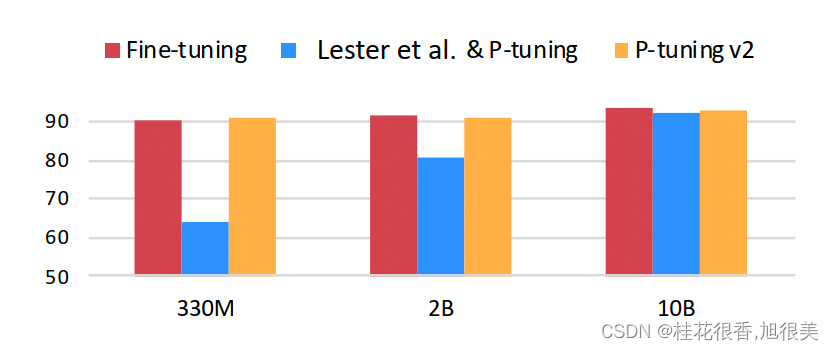
- 不同任务类型:Prompt Tuning 和 P-tuning 这两种方法在 sequence tagging 任务上表现都很差。
主要结构
相比 Prompt Tuning 和 P-tuning 的方法,P-tuning v2 方法在多层加入了 Prompts tokens 作为输入,带来两个方面的好处:
-
带来更多可学习的参数(从 P-tuning 和 Prompt Tuning 的 0.1% 增加到0.1%-3%),同时也足够 parameter-efficient。
-
加入到更深层结构中的 Prompt 能给模型预测带来更直接的影响。
 v1到v2的可视化:蓝色部分为参数冻结,橙色部分为可训练部分
v1到v2的可视化:蓝色部分为参数冻结,橙色部分为可训练部分
几个关键设计因素
- Reparameterization:Prefix Tuning 和 P-tuning 中都有 MLP 来构造可训练的 embedding。本文发现在自然语言理解领域,面对不同的任务以及不同的数据集,这种方法可能带来完全相反的结论。
- Prompt Length:不同的任务对应的最合适的 Prompt Length 不一样,比如简单分类任务下 length=20 最好,而复杂的任务需要更长的 Prompt Length。
- Multi-task Learning 多任务对于 P-Tuning v2 是可选的,但可以利用它提供更好的初始化来进一步提高性能。
- Classification Head 使用 LM head 来预测动词是 Prompt Tuning 的核心,但在完整的数据设置中没有必要这样做,并且这样做与序列标记不兼容。P-tuning v2 采用和 BERT 一样的方式,在第一个 token 处应用随机初始化的分类头。
实验结果
- 不同预训练模型大小下的表现,在小模型下取得与Full-finetuning相近的结果,并远远优于P-Tuning。
- 不同任务下的 P-Tuning v2 效果都很好,而 P-Tuning 和 Prompt Learning 效果不好;同时,采用多任务学习的方式能在多数任务上取得最好的结果。
- Verbalizer with LM head v.s. [CLS] label with linear head,两种方式没有太明显的区别
- Prompt depth,在加入相同层数的 Prompts 前提下,往更深层网络加效果大部分优于往更浅层网络。
from peft import PromptTuningConfig, get_peft_model
model_name_or_path = "./unsup-simcse-roberta-base"
peft_type = PeftType.P_TUNING
lr = 1e-3
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
LoRA
现有的一些 PEFT 的方法还存在这样一些问题:
- 由于增加了模型的深度从而额外增加了模型推理的延时,如 Adapter 方法
- Prompt 较难训练,同时减少了模型的可用序列长度,如 Prompt Tuning、Prefix Tuning、P-Tuning 方法
- 往往效率和质量不可兼得,效果差于 full-finetuning
Low-Rank Adaption(LoRA),设计了如下所示的结构,在涉及到矩阵相乘的模块,引入 A、B 这样两个低秩矩阵模块去模拟 Full-finetune 的过程,相当于只对语言模型中起关键作用的低秩本质维度进行更新。
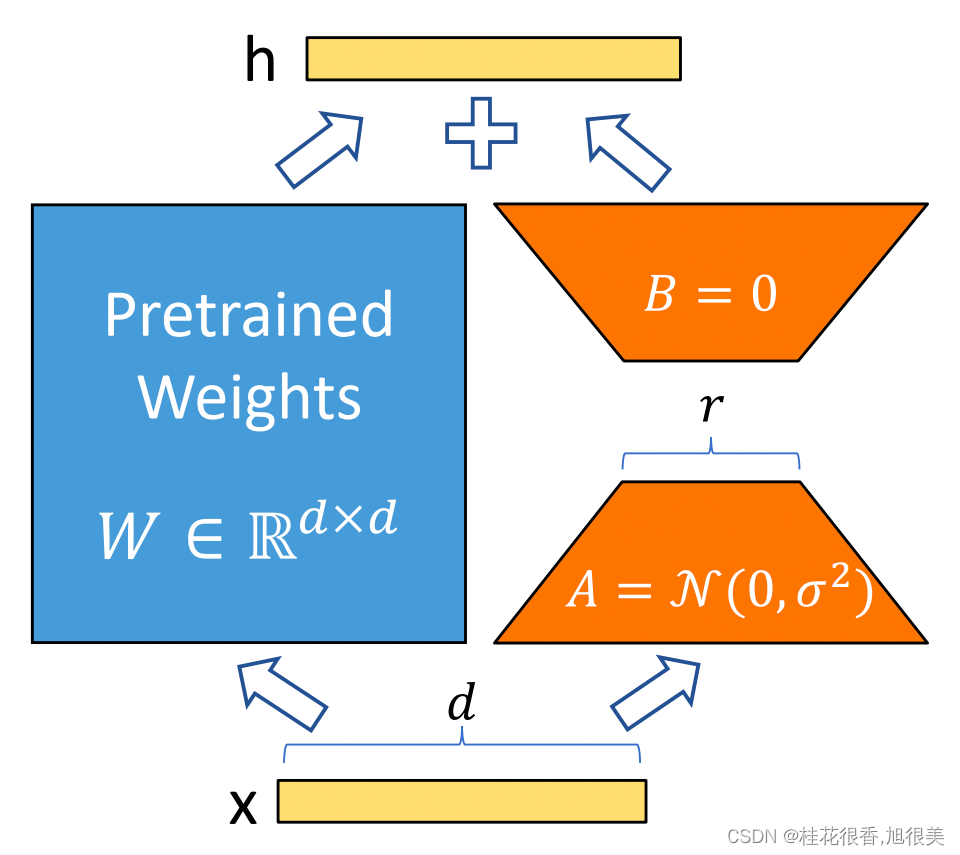
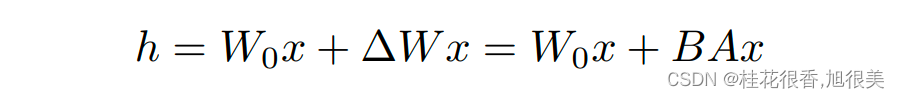 这么做就能完美解决以上存在的 3 个问题:
这么做就能完美解决以上存在的 3 个问题:
- 相比于原始的 Adapter 方法“额外”增加网络深度,必然会带来推理过程额外的延迟,该方法可以在推理阶段直接用训练好的 A、B 矩阵参数与原预训练模型的参数相加去替换原有预训练模型的参数,这样的话推理过程就相当于和 Full-finetune 一样,没有额外的计算量,从而不会带来性能的损失。
- 由于没有使用 Prompt 方式,自然不会存在 Prompt 方法带来的一系列问题。
- 该方法由于实际上相当于是用 LoRA 去模拟 Full-finetune 的过程,几乎不会带来任何训练效果的损失,后续的实验结果也证明了这一点。
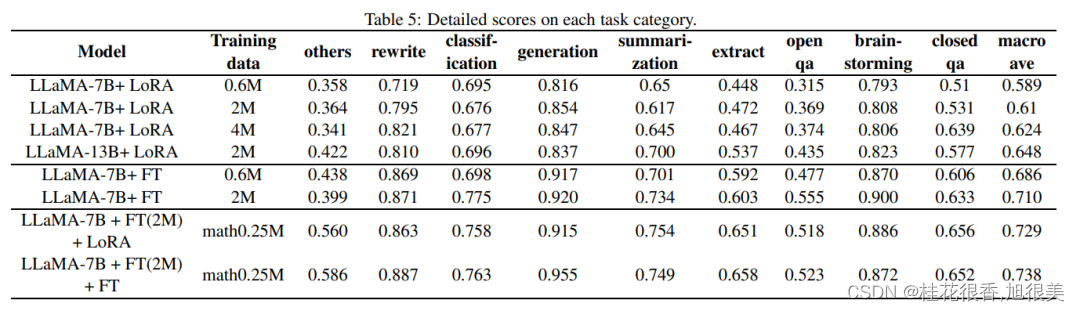
```python
from peft import PromptTuningConfig, get_peft_model
model_name_or_path = "./unsup-simcse-roberta-base"
peft_type = peft_type = PeftType.LORA
lr = 3e-4
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
https://huggingface.co/docs/peft/conceptual_guides/lora
PETL 大统一
通用形式
 通过对 Prefix Tuning 的推导,得出了和 Adapter Tuning 以及 LoRA 形式一致的形式。
通过对 Prefix Tuning 的推导,得出了和 Adapter Tuning 以及 LoRA 形式一致的形式。
更近一步地,可以将这些 Tuning 的方法统一在同一套框架下,
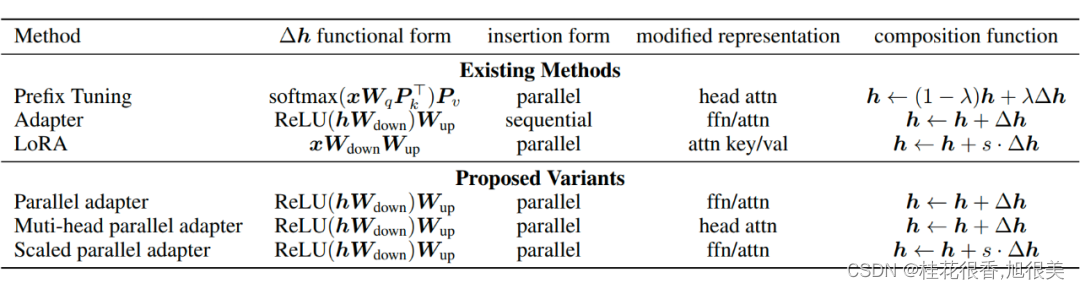
包括这几大要素:

典型应用:
- ChatGLM-Tuning :一种平价的chatgpt实现方案,基于清华的 ChatGLM-6B + LoRA 进行finetune。
- Alpaca-Lora:使用低秩自适应(LoRA)复现斯坦福羊驼的结果。Stanford Alpaca 是在 LLaMA 整个模型上微调,而 Alpaca-Lora 则是利用 Lora 技术,在冻结原模型 LLaMA 参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅微调的成本显著下降,还能获得和全模型微调类似的效果。
- BLOOM-LORA:由于LLaMA的限制,我们尝试使用Alpaca-Lora重新实现BLOOM-LoRA。
参考
- LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- Prefix Tuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation, P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- P-Tuning: GPT Understands, Too
- Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
- AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
- huggingface/doc/peft
- github.com/huggingface/peft
- 【LLMs学习】关于大模型实践的一些总结
- ChatGPT等大模型高效调参大法——PEFT库的算法简介
- 让天下没有难Tuning的大模型:PEFT技术简介





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结