您现在的位置是:首页 >学无止境 >2023.05.14-微调ResNet参加kaggle上猫狗大战比赛打到99%的分类准确率_convert网站首页学无止境
2023.05.14-微调ResNet参加kaggle上猫狗大战比赛打到99%的分类准确率_convert
简介2023.05.14-微调ResNet参加kaggle上猫狗大战比赛打到99%的分类准确率_convert
文章目录
1. 前言
- 一直想玩一下这个猫狗大战,但是总是没有下功夫调参。周末有时间,又租借了一个云服务器,万事俱备,只欠东风,开始搞起。
2. 下载数据集
- 想要参加kaggle官网上面的这个猫狗大战比赛,首先需要注册一个kaggle账号用来下载对应的数据集。
打开下面的网站进行下载即可
3. 比赛成绩排名
- www.kaggle.com/competitions/dogs vs cats/leaderboard
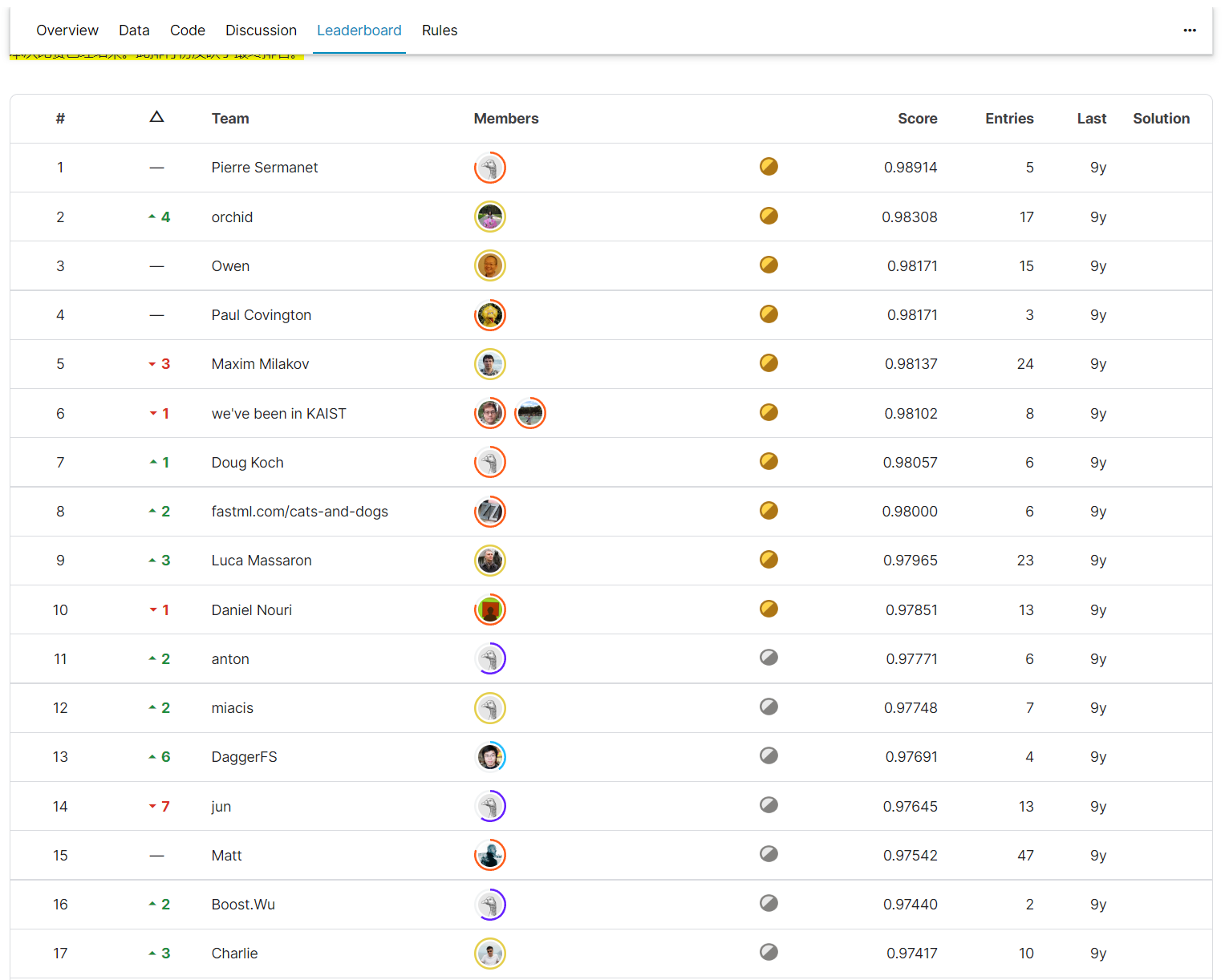
- 第一名的分数是0.98914
4. baseline
5. 尝试
- 自己搜索了网上对于猫狗大战中可以涨点的策略,自己主要做了以下尝试
5.1. 数据归一化(98.994%)
添加这个归一化代码
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
完整代码
transform = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
效果
- 不得不说,对数据进行归一化之后,可以极大的提高这个网络收敛的速度。第一个周期的验证准确率就可以达到98.39%
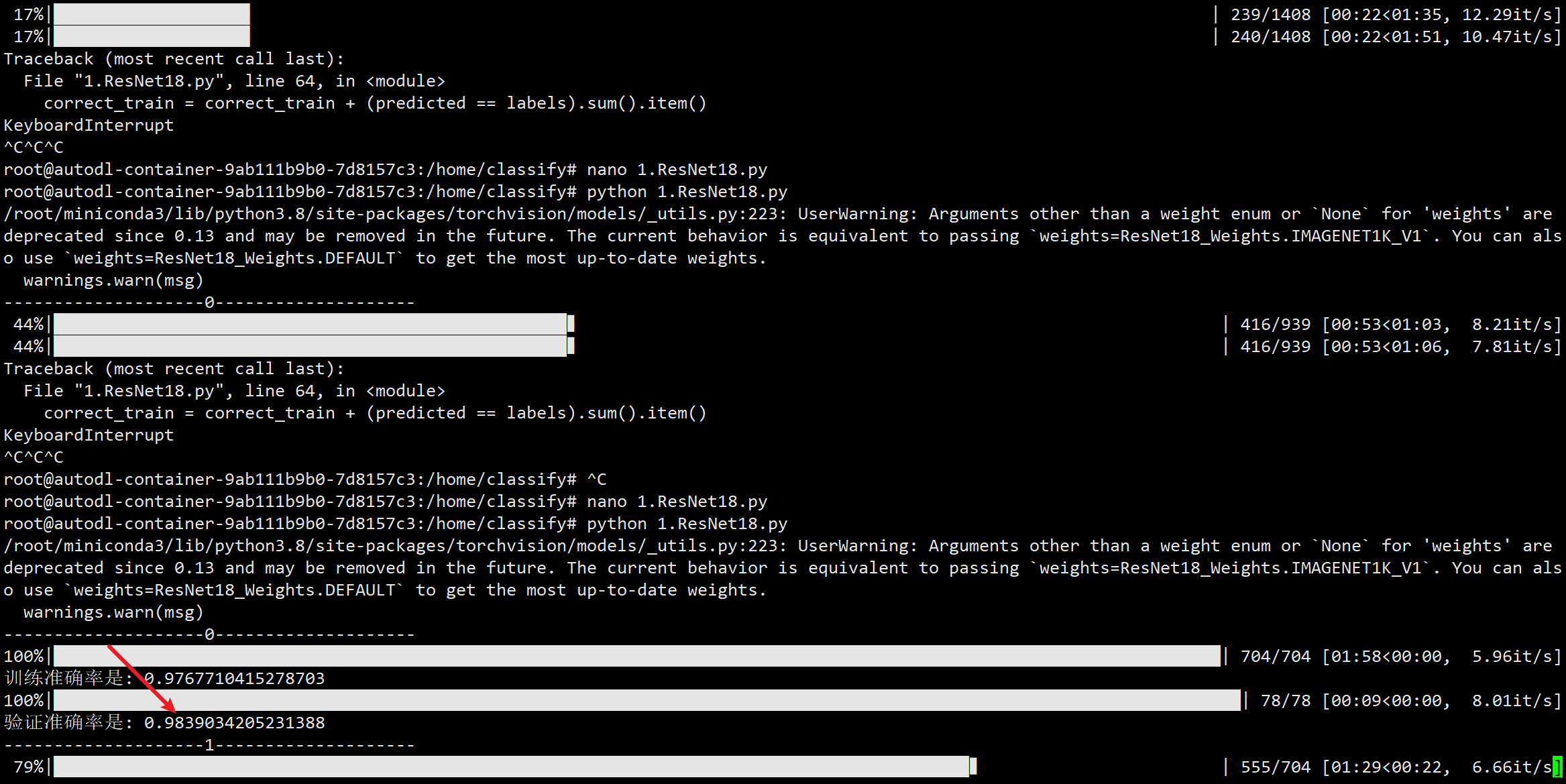
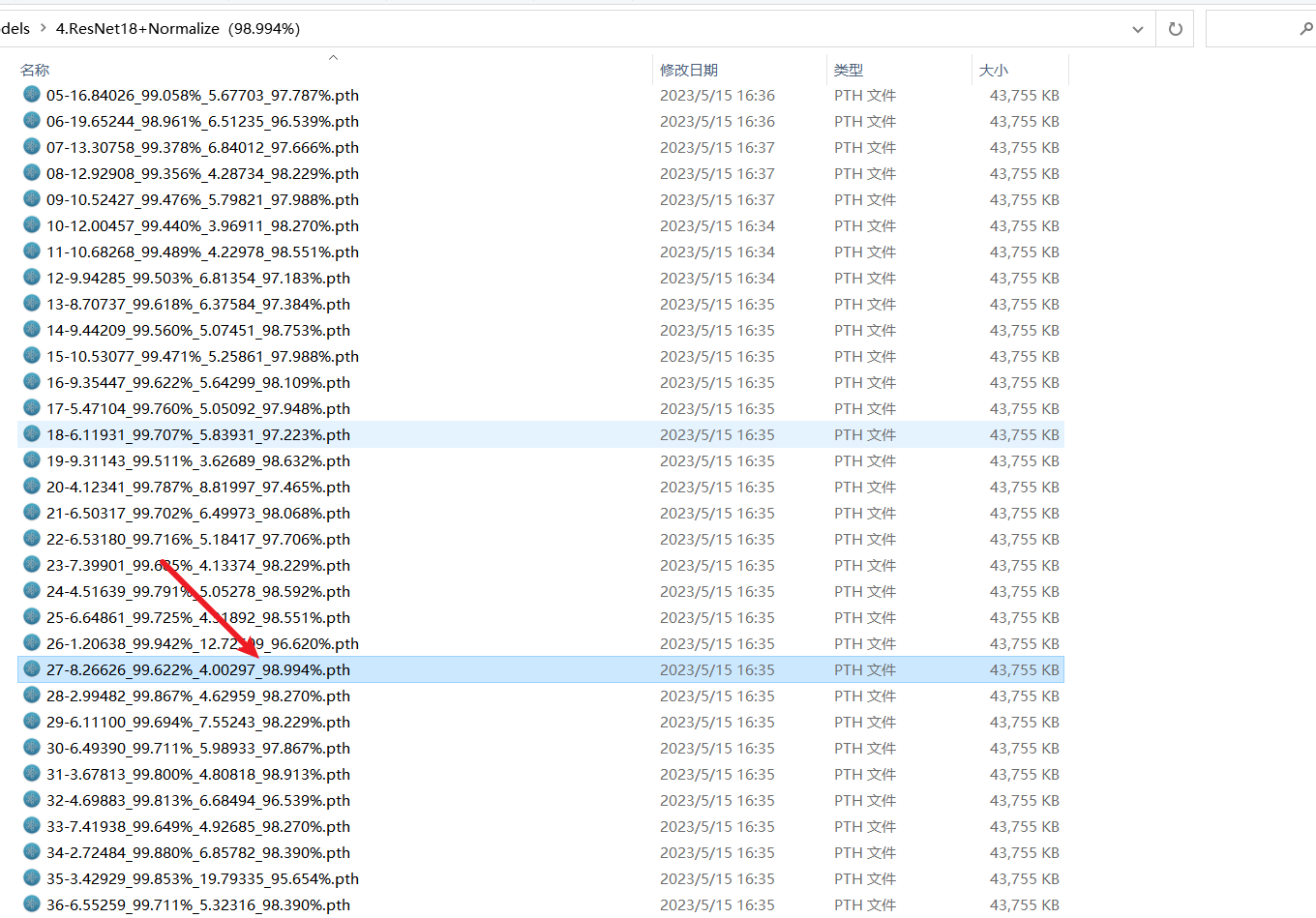
- 100个周期跑完,最好可以达到98.994%的效果
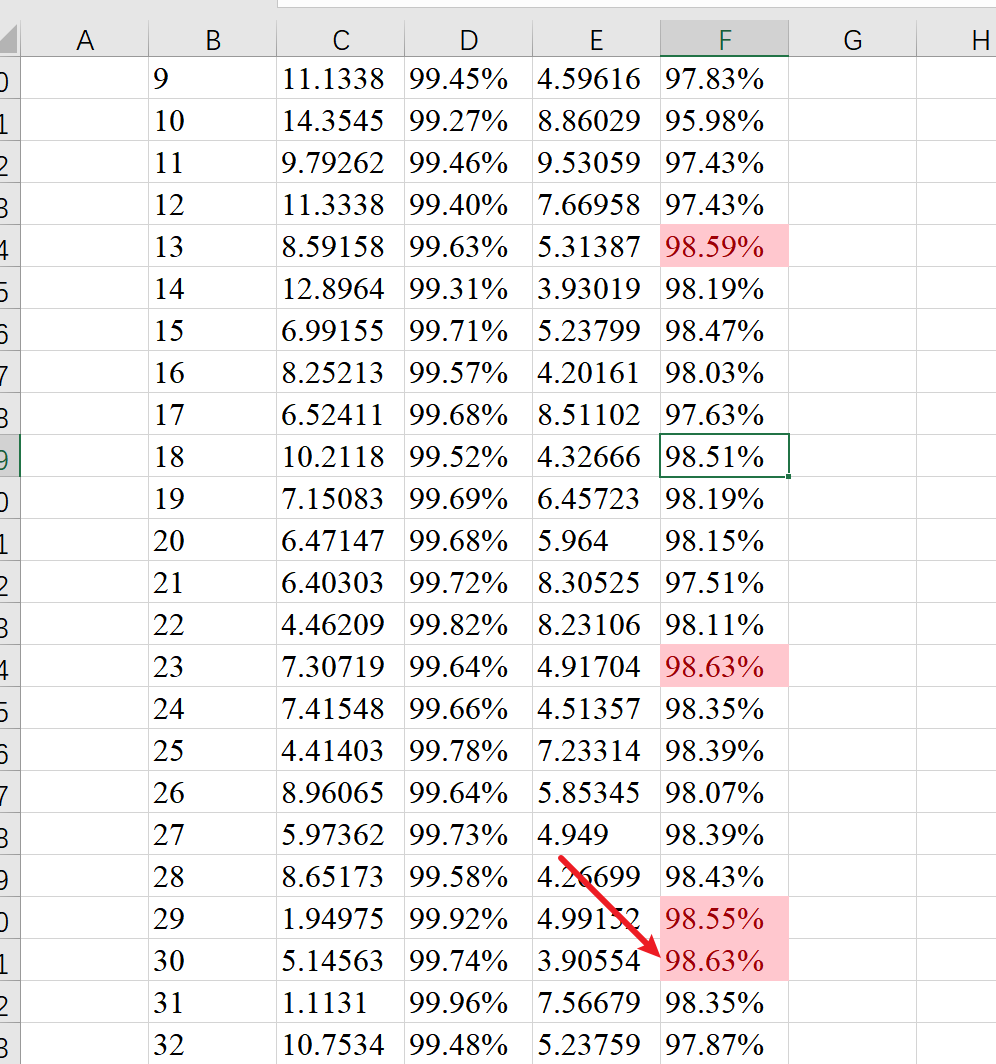
5.2. 使用AdamW优化器(98.63%)
AdamW是带有权重衰减(而不是L2正则化)的Adam,它在错误实现、训练时间都胜过Adam。
对应的数据
epoch train loss train acc val loss val acc
0 43.95111 97.75% 2.93358 98.51%
1 430.50297 64.70% 36.61037 77.67%
2 137.0172 91.71% 5.94341 96.82%
3 40.69821 97.84% 3.16171 98.71%
4 28.72242 98.44% 5.38266 97.71%
5 21.23378 98.85% 5.59306 97.02%
6 18.11441 99.04% 3.98322 98.03%
7 19.32834 99.00% 5.01681 98.07%
8 11.94442 99.44% 4.81179 97.91%
9 11.1338 99.45% 4.59616 97.83%
10 14.35451 99.27% 8.86029 95.98%
11 9.79262 99.46% 9.53059 97.43%
12 11.3338 99.40% 7.66958 97.43%
13 8.59158 99.63% 5.31387 98.59%
14 12.89642 99.31% 3.93019 98.19%
15 6.99155 99.71% 5.23799 98.47%
16 8.25213 99.57% 4.20161 98.03%
17 6.52411 99.68% 8.51102 97.63%
18 10.21184 99.52% 4.32666 98.51%
19 7.15083 99.69% 6.45723 98.19%
20 6.47147 99.68% 5.964 98.15%
21 6.40303 99.72% 8.30525 97.51%
22 4.46209 99.82% 8.23106 98.11%
23 7.30719 99.64% 4.91704 98.63%
24 7.41548 99.66% 4.51357 98.35%
25 4.41403 99.78% 7.23314 98.39%
26 8.96065 99.64% 5.85345 98.07%
27 5.97362 99.73% 4.949 98.39%
28 8.65173 99.58% 4.26699 98.43%
29 1.94975 99.92% 4.99152 98.55%
30 5.14563 99.74% 3.90554 98.63%
31 1.1131 99.96% 7.56679 98.35%
32 10.75336 99.48% 5.23759 97.87%
33 0.86672 99.97% 9.2502 98.31%
34 7.93448 99.64% 4.37685 98.03%
35 2.44822 99.87% 7.21055 97.87%
36 6.85281 99.75% 5.51565 97.91%
37 3.2463 99.85% 9.12831 97.79%
38 6.26243 99.69% 5.899 97.75%
39 3.29857 99.90% 7.2071 97.87%
40 0.5045 99.99% 7.05801 98.51%
41 0.0135 100.00% 7.54731 98.43%
42 0.0027 100.00% 8.59324 98.47%
43 0.00083 100.00% 8.99156 98.43%
44 0.00045 100.00% 9.55036 98.43%
45 0.00027 100.00% 10.0697 98.43%
46 0.00017 100.00% 10.39488 98.43%
47 0.0001 100.00% 10.98709 98.43%
48 0.00008 100.00% 11.46222 98.43%
49 0.00005 100.00% 11.51941 98.35%
50 0.00004 100.00% 11.73555 98.39%
51 0.00002 100.00% 12.03522 98.35%
52 0.00002 100.00% 12.54926 98.35%
53 0.00001 100.00% 12.42227 98.35%
54 0.00001 100.00% 13.2006 98.31%
55 0.00001 100.00% 13.64486 98.31%
56 0 100.00% 12.90368 98.35%
57 0 100.00% 13.13818 98.35%
58 0 100.00% 13.7345 98.31%
59 0 100.00% 13.65401 98.27%
60 0 100.00% 13.74176 98.31%
61 0 100.00% 13.78569 98.31%
62 0 100.00% 14.64054 98.27%
63 0 100.00% 14.17896 98.27%
64 0 100.00% 13.99432 98.31%
65 0 100.00% 14.73406 98.31%
66 0 100.00% 14.69667 98.31%
67 0 100.00% 14.58825 98.27%
68 0 100.00% 14.88915 98.31%
69 0 100.00% 14.95989 98.27%
70 0 100.00% 15.37874 98.27%
71 0 100.00% 15.86721 98.27%
72 0 100.00% 16.20822 98.23%
73 0 100.00% 16.20378 98.31%
74 0 100.00% 17.1774 98.31%
75 25.10347 98.93% 5.52769 97.91%
76 9.66224 99.53% 4.98326 98.11%
77 2.80008 99.88% 6.26822 98.43%
78 5.21812 99.79% 4.73304 98.31%
79 3.3407 99.85% 8.41819 98.11%
80 0.46344 99.98% 7.39496 98.47%
81 0.01035 100.00% 7.52614 98.51%
82 0.00332 100.00% 8.00924 98.51%
83 0.00135 100.00% 8.59734 98.47%
84 0.00056 100.00% 9.3975 98.55%
85 0.00024 100.00% 9.93917 98.43%
86 0.00008 100.00% 11.35343 98.43%
87 0.00003 100.00% 11.89728 98.43%
88 0.00002 100.00% 12.30812 98.43%
89 0.00001 100.00% 12.8423 98.47%
90 0.00001 100.00% 13.57241 98.35%
91 0 100.00% 13.41991 98.51%
92 0 100.00% 13.87756 98.43%
93 0 100.00% 14.49194 98.31%
94 0 100.00% 14.60349 98.47%
95 0 100.00% 15.24883 98.39%
96 0 100.00% 15.04266 98.43%
97 0 100.00% 16.21219 98.39%
98 0 100.00% 15.58381 98.51%
99 0 100.00% 16.35482 98.35%
效果
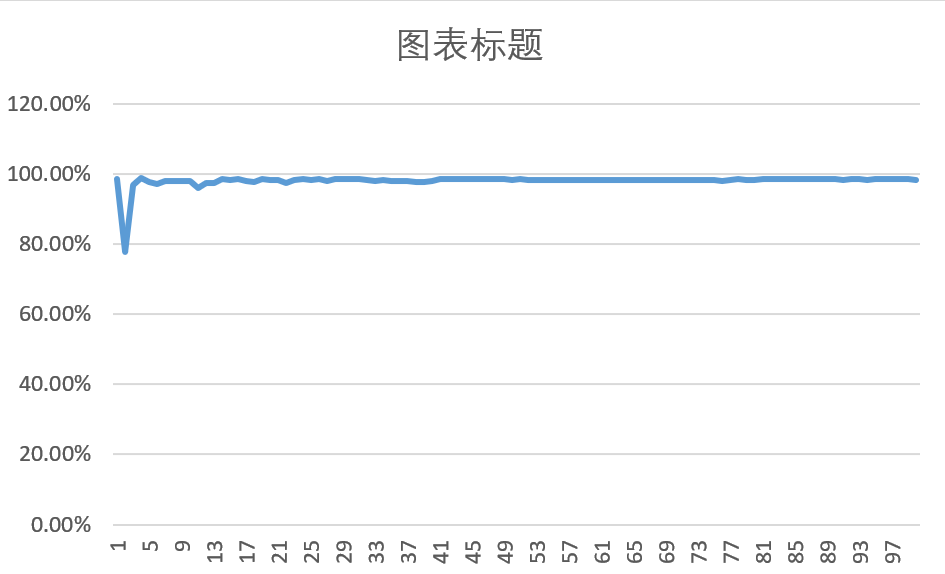
最高可以达到98.63%
98.51%
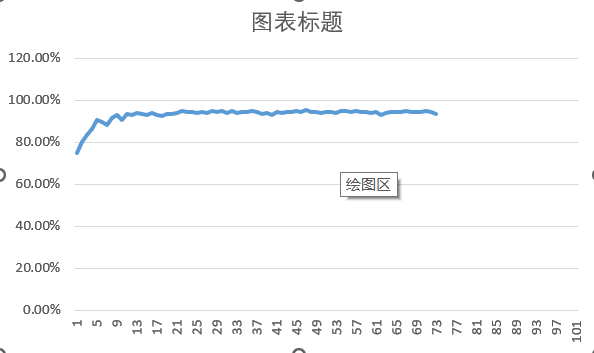
5.3. 使用AdamW优化器+SegNet模块(95.05%)
我是想在之前的基础上添加一个注意力机制模块,但是不知道为什么训练级的准确率很高,但是验证集上的效果却要差很多,可能是因为自己添加的这个注意力机制模块使得网络的泛化性变差了吧
对应的数据
00 841.16123 66.698% 80.34021 74.849%
01 782.98219 70.309% 66.07160 80.322%
02 593.89293 80.817% 55.39222 83.702%
03 485.13791 84.672% 49.78145 86.398%
04 386.34337 88.332% 34.40874 90.744%
05 324.79488 90.300% 37.25761 89.537%
06 273.36514 92.112% 41.78502 88.531%
07 245.33996 92.756% 30.65071 91.549%
08 209.99650 93.893% 24.99330 93.280%
09 174.44573 94.946% 40.70310 90.865%
10 152.54020 95.590% 24.66959 93.642%
11 126.36934 96.429% 26.63028 92.958%
12 107.61617 96.962% 24.49496 93.843%
13 94.44031 97.433% 27.07281 93.320%
14 77.85434 97.926% 33.65216 92.998%
15 71.30835 98.055% 27.37954 94.044%
16 56.10977 98.534% 37.30386 93.119%
17 51.94865 98.583% 45.16884 92.596%
18 45.82673 98.863% 33.09134 93.682%
19 46.00949 98.748% 30.61986 93.763%
20 39.88356 98.965% 32.49509 94.245%
21 35.98075 99.076% 30.70699 94.728%
22 36.77068 99.072% 26.50579 94.487%
23 29.62899 99.272% 29.40019 94.487%
24 30.70629 99.232% 37.46327 93.843%
25 38.08304 99.054% 28.52988 94.366%
26 25.40524 99.400% 37.30047 94.044%
27 33.73834 99.174% 30.09059 94.889%
28 24.33486 99.449% 34.55807 94.447%
29 29.78610 99.325% 31.62320 94.809%
30 23.03223 99.427% 46.01729 94.205%
31 26.88877 99.312% 42.09933 94.809%
32 25.12524 99.409% 36.05506 94.044%
33 22.30487 99.436% 33.46056 94.326%
34 23.79032 99.365% 33.57563 94.406%
35 18.53882 99.569% 31.54106 95.050%
36 20.52793 99.511% 37.89401 94.487%
37 21.22465 99.467% 43.78654 93.763%
38 19.86762 99.467% 47.26076 94.165%
39 17.43618 99.591% 52.05411 93.078%
40 19.54660 99.498% 32.24883 94.567%
41 15.23968 99.645% 42.51051 94.205%
42 20.26523 99.529% 37.01770 94.366%
43 13.82244 99.614% 39.53712 94.648%
44 18.52900 99.507% 36.48620 94.728%
45 13.13430 99.671% 46.33306 94.527%
46 20.10074 99.525% 38.52874 95.493%
47 17.74225 99.574% 30.75011 94.648%
48 11.84078 99.698% 41.63479 94.567%
49 18.99130 99.520% 35.11506 94.245%
50 13.96501 99.654% 36.95696 94.326%
51 10.47367 99.747% 42.35815 94.567%
52 17.46265 99.614% 49.29176 94.245%
53 13.03071 99.658% 45.44298 94.849%
54 12.27281 99.658% 45.32041 95.010%
55 15.32756 99.685% 40.12351 94.447%
56 14.36285 99.671% 39.26911 94.809%
57 10.85270 99.729% 41.98047 94.366%
58 13.66196 99.667% 45.47937 94.648%
59 13.33846 99.689% 44.08331 93.964%
60 12.87245 99.680% 43.91811 94.286%
61 11.93796 99.738% 36.15065 93.239%
62 12.06105 99.760% 33.67126 94.085%
63 13.68432 99.725% 45.61084 94.406%
64 14.13714 99.694% 36.90194 94.648%
65 8.25917 99.800% 49.74482 94.406%
66 12.15086 99.707% 42.50143 94.930%
67 10.02019 99.751% 40.13083 94.567%
68 9.81753 99.813% 57.15547 94.648%
69 13.14721 99.676% 41.48277 94.608%
70 10.72047 99.725% 43.08352 94.849%
71 10.62724 99.698% 39.06533 94.406%
72 8.58425 99.791% 45.32018 93.763%
6. 结语
- 可以说目前这个精度可以达到99%,我觉得应该是比较高的一个精度了,测试集上没有必要达到100%,这是很难的,也是不可能的,毕竟有些猫和狗的图片长得实在是太像了,人眼都很难分出来到底谁是猫谁是狗,所以这个猫狗大战分类的调试尝试到这里应该就差不多了。
7. 感慨
- 当年猫狗大战的时候,能上到98%都已经算出top 1了。但是现在我们采用预训练模型加微调的方法,可以轻轻搞上99%。不仅感慨现在深度学习越来越卷了,
- 不过也不得不说,ResNet毕竟是2015年imaginet图像分类比赛中的冠军,效果真的是一级棒。
8. 代码
8.1. ResNet+Normalize+AdamW完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from tqdm import tqdm
from torchvision import transforms
import torchvision
from torch.utils.data import DataLoader
transform = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
def make_dir(path):
import os
dir = os.path.exists(path)
if not dir:
os.makedirs(path)
make_dir('models')
batch_size = 8
train_set = torchvision.datasets.ImageFolder(root='data/cat_vs_dog/train', transform=transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True,
num_workers=0) # Batch Size定义:一次训练所选取的样本数。 Batch Size的大小影响模型的优化程度和速度。
val_dataset = torchvision.datasets.ImageFolder(root='data/cat_vs_dog/val', transform=transform)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True,
num_workers=0) # Batch Size定义:一次训练所选取的样本数。 Batch Size的大小影响模型的优化程度和速度。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
net = torchvision.models.resnet18(weights=True)
num_ftrs = net.fc.in_features
net.fc = nn.Linear(num_ftrs, 2) # 将输出维度修改为2
criterion = nn.CrossEntropyLoss()
net = net.to(device)
optimizer = torch.optim.AdamW(lr=0.0001, params=net.parameters())
eposhs = 100
for epoch in range(eposhs):
print(f'--------------------{epoch}--------------------')
correct_train = 0
sum_loss_train = 0
total_correct_train = 0
for inputs, labels in tqdm(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
output = net(inputs)
loss = criterion(output, labels)
sum_loss_train = sum_loss_train + loss.item()
total_correct_train = total_correct_train + labels.size(0)
optimizer.zero_grad()
_, predicted = torch.max(output.data, 1)
loss.backward()
optimizer.step()
correct_train = correct_train + (predicted == labels).sum().item()
acc_train = correct_train / total_correct_train
print('训练准确率是{:.3f}%:'.format(acc_train*100) )
net.eval()
correct_val = 0
sum_loss_val = 0
total_correct_val = 0
for inputs, labels in tqdm(val_loader):
inputs = inputs.to(device)
labels = labels.to(device)
output = net(inputs)
loss = criterion(output, labels)
sum_loss_val = sum_loss_val + loss.item()
output = net(inputs)
total_correct_val = total_correct_val + labels.size(0)
optimizer.zero_grad()
_, predicted = torch.max(output.data, 1)
correct_val = correct_val + (predicted == labels).sum().item()
acc_val = correct_val / total_correct_val
print('验证准确率是{:.3f}%:'.format(acc_val*100) )
torch.save(net,'models/{}-{:.5f}_{:.3f}%_{:.5f}_{:.3f}%.pth'.format(epoch,sum_loss_train,acc_train *100,sum_loss_val,acc_val*100))
8.1.1. 仓库
- 然后我把所有的代码和权重全部上传到了Huggin Face上面,如果有兴趣的小伙伴可以在我代码的基础上做进一步的尝试
- NewBreaker/classify-cat_vs_dog · Hugging Face
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结