您现在的位置是:首页 >其他 >助力工业物联网,工业大数据之数仓维度层DWS层构建【十二】网站首页其他
助力工业物联网,工业大数据之数仓维度层DWS层构建【十二】
简介助力工业物联网,工业大数据之数仓维度层DWS层构建【十二】
数仓维度层DWS层构建
01:项目回顾
-
ODS层与DWD层的功能与区别是什么?
- ODS:原始数据层
- 存储格式:AVRO
- 数据内容:基本与原始数据是一致的
- DWD:明细数据层
- 存储格式:Orc
- 数据内容:基于与ODS层是一致的
- ODS:原始数据层
-
ODS层的需求是什么?
-
自动化建库建表
-
建表
create table one_make_ods.表名 tableproperties(schema文件)- 表名
- 表的注释
- 表对应的HDFS地址
- Schema文件的地址
-
-
DWD层的需求是什么?
-
自动化建库建表
-
建表
create table one_make_dwd.表名( 字段信息 ) location- 表名
- 表的注释
- 表对应的HDFS地址
- 字段信息
-
-
怎么获取表的Schema信息?
- 表的注释、Schema信息
- ODS:Oracle中获取表的注释、Schema文件从Sqoop生成的
- DWD:Oracle中获取表的信息
- TableMeta:表名,表的注释,列的信息:List
- ColumnMeta:列名、列的注释、列的类型、长度、精度
-
如何使用Python构建Oracle和Hive的连接?
- Oracle:cx_Oracle
- conn(host,port,user,passwd,sid)
- Hive/SparkSQL:pyHive
- SparkSQL用法
- 编程方式:python文件 | jar包
- 流程
- step1:SparkSession
- step2:读取数据源
- step3:处理
- 注册视图
- spark.sql(“”)
- spark-submit
- 优点:灵活
- 场景:DSL
- 流程
- 提交SQL:ThriftServer
- 场景:SQL,调度开发
- 流程
- JDBC | PyHive | Beeline:代码中开发
- spark-sql -f xxxx.sql:SQL文件的运行
- Oracle:cx_Oracle
-
如果实现SQL语句的执行?
-
step1: 先构建服务端的远程连接
- 服务端地址:主机名 + 端口
- 用户名和密码
-
step2:基于这个连接构建一个游标
-
step3:通过游标来执行SQL语句:execute(String:SQL)
-
step4:释放资源
-
-
集中问题
- 连接构建不上
- 映射不对:spark.bigdata.cn:Can not Connect[46.xxx.xxxx.xx,10001]
- 修改host文件
- 修改config.txt:node1
- 服务端问题:spark.bigdata.cn:Can not Connect[192.168.88.100,10001]
- Spark的TriftServer没有启动
- 启动完成先用dg或者beeline先测试一下
- ThriftServer:依赖于MetaStore + YARN
- 检查YARN:本质就是一个Spark程序:实时程序,不停止的
- Spark的TriftServer没有启动
- Oracle:cx_Oracle + 本地客户端:D:instantclient_12_2
- 映射不对:spark.bigdata.cn:Can not Connect[46.xxx.xxxx.xx,10001]
- 安装
- Python版本:Python 3.7.4
- 命令sasl
- 连接构建不上
02:项目目标
- 回顾维度建模
- 建模流程:划分主题域和主题
- 维度设计:构建维度矩阵
- 维度模型:雪花模型、星型模式
- 项目中的建模流程和维度设计
- 划分了哪些主题域,每个主题域有哪些主题?
- 每个主题基于哪些维度进行分析?
- 维度层构建
- 时间维度
- 地区维度
- 油站维度
- 服务网点维度
- 组织机构维度
- 仓库维度
- 物流维度
03:维度建模回顾:建模流程
-
目标:掌握维度建模的建模流程
-
实施
-
step1-需求调研:业务调研和数据调研
- 了解整个业务实现的过程
- 收集所有数据使用人员对于数据的需求
- 整理所有数据来源
-
step2-划分主题域:面向业务将业务划分主题域及主题
- 用户域、店铺域
- 商品域、交易域、
- 客服域、信用风控域、采购分销域
-
step3-构建维度总线矩阵:明确每个业务主题对应的维度关系

-
step4-明确指标统计:明确所有原生指标与衍生指标
-
原生指标:基于某一业务事件行为下的度量,是业务定义中不可再拆分的指标,如支付总金额
-
衍生指标:基于原子指标添加了维度:近7天的支付总金额等
-
-
step5-定义事实与维度规范
- 命名规范、类型规范、设计规范等
-
step6-代码开发
-
实现具体的代码开发
-
只要知道指标的计算方式,基于维度分组计算指标
-
-
-
小结
- 掌握维度建模的建模流程
04:维度建模回顾:维度设计
-
目标:掌握维度建模中维度的设计
-
实施
- 功能:基于组合维度来更加细化我们的指标,来更加精确的发现问题
- 指标如果不基于组合维度进行分析得到,指标的结果是没有意义的
- 实现:开发中维度就是指标聚合时的分组字段
- 特点
- 数据量小
- 很少发生变化
- 采集方式:全量
- 常见维度
- 时间维度:年、季度、月、周、天、小时
- 地区维度:国家、省份、城市
- 平台维度:网站、APP、小程序、H5
- 操作系统维度:Windows、Mac OS、Android、Linux、IOS
- ……
- 功能:基于组合维度来更加细化我们的指标,来更加精确的发现问题
-
小结
- 掌握维度建模中维度的设计
05:维度建模回顾:维度模型
-
目标:掌握维度设计的常用模型
-
路径
- step1:雪花模型
- step2:星型模型
- step3:星座模型
-
实施
-
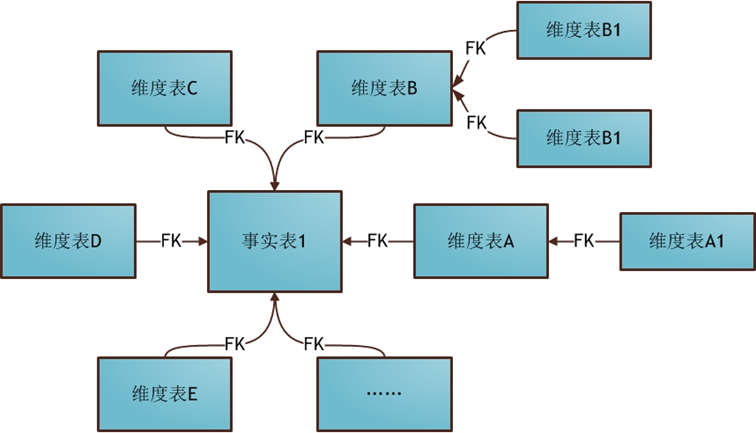
雪花模型
- 设计:部分维度通过其他维度间接关联事实表
- 优点:避免数据的冗余
- 缺点:关联层次比较多,数据大的情况下,底层层层Join,查询数据性能降低
-
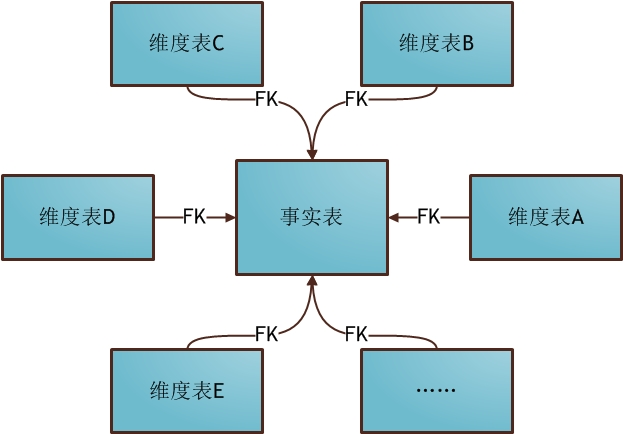
星型模型
- 设计:所有维度表直接关联事实表
- 优点:每次查询时候,直接获取对应的数据结果,不用关联其他的维度子表,可以提高性能
- 缺点:数据冗余度相比雪花模型较高
-
星座模型
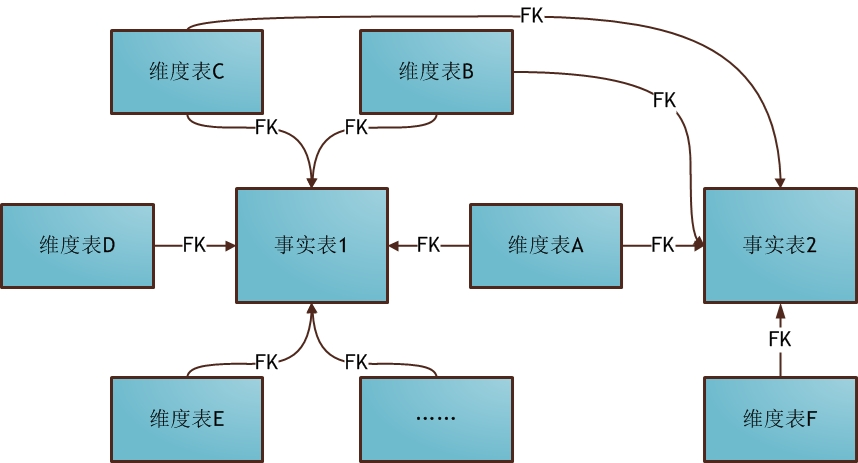
-
星座模型:基于星型模型的演变,多个事实共同使用一个维度表
-
-
-
小结
- 掌握维度设计的常用模型
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结