您现在的位置是:首页 >技术交流 >大模型中的temperature参数+随机采样策略网站首页技术交流
大模型中的temperature参数+随机采样策略
简介大模型中的temperature参数+随机采样策略
一、问题来源:
使用GPT-3.5的时候发现相同的输入会得不一样的结果
二、根因定位:
核心就在于采样策略,一图胜千言:
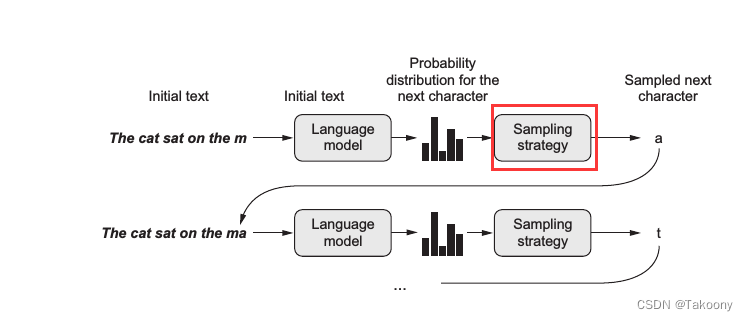
上图中语言模型 (language model) 的预测输出其实是字典中所有词的概率分布,而通常会选择生成其中概率最大的那个词。不过图中出现了一个采样策略 (sampling strategy),这意味着有时候我们可能并不想总是生成概率最大的那个词。设想一个人的行为如果总是严格遵守规律缺乏变化,容易让人觉得乏味;同样一个语言模型若总是按概率最大的生成词,那么就容易变成 XX讲话稿了
解码策略
- greedy decoding
- beam search decoding
- Sampling-based decoding
- Softmax temperature
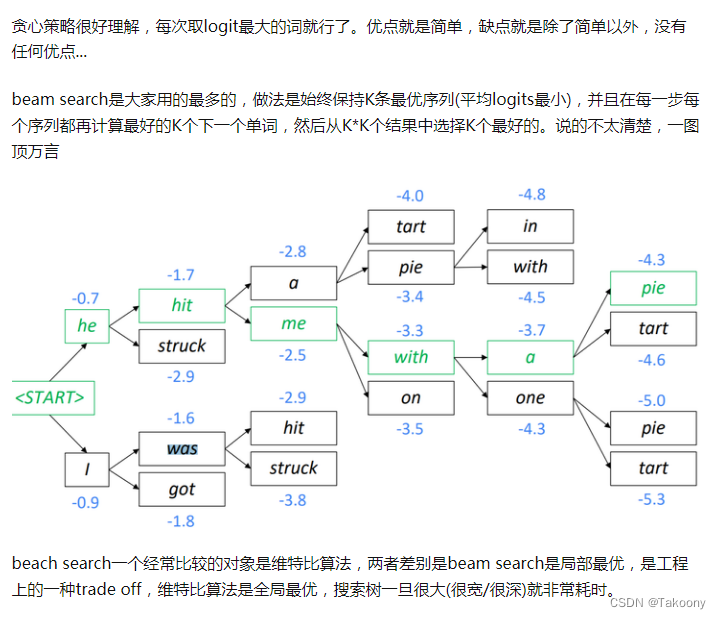

temperature参数
因此在生成词的过程中引入了采样策略,在最后从概率分布中选择词的过程中引入一定的随机性,这样一些本来不大可能组合在一起的词可能也会被生成,进而生成的文本有时候会变得有趣甚至富有创造性。采样的关键是引入一个temperature参数,用于控制随机性。假设 p(x)为模型输出的原始分布,则加入 temperature 后的新分布为:
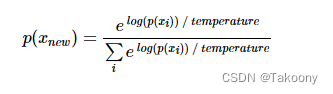
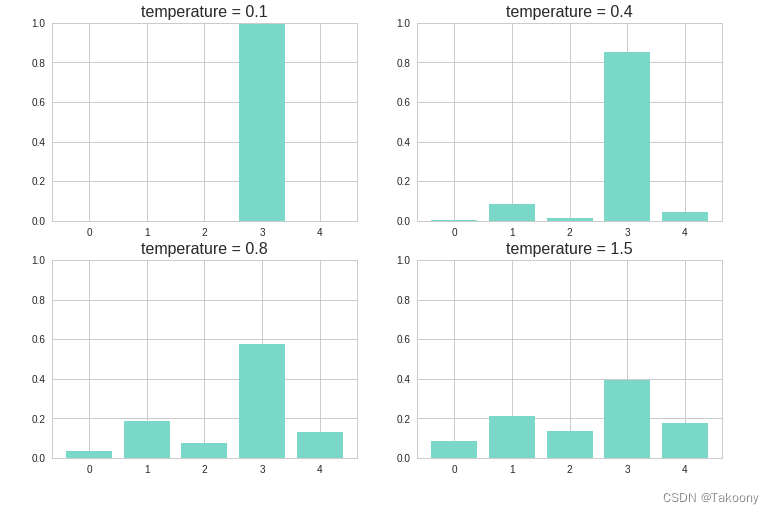
下图展示了不同的 temperature 分别得到的概率分布。temperature 越大,则新的概率分布越均匀,随机性也就越大,越容易生成一些意想不到的词。
def sample(p, temperature=1.0): # 定义采样策略
distribution = np.log(p) / temperature
distribution = np.exp(distribution)
return distribution / np.sum(distribution)
p = [0.05, 0.2, 0.1, 0.5, 0.15]
for i, t in zip(range(4), [0.1, 0.4, 0.8, 1.5]):
plt.subplot(2, 2, i+1)
plt.bar(np.arange(5), sample(p, t))
plt.title("temperature = %s" %t, size=16)
plt.ylim(0,1)
top-k参数

top-p参数
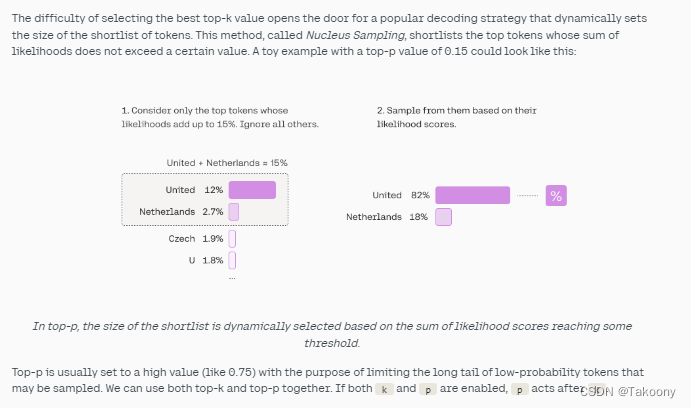
https://www.cnblogs.com/massquantity/p/9511694.html
https://zhuanlan.zhihu.com/p/560847355
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结