您现在的位置是:首页 >技术交流 >【论文阅读-TPAMI2021】Curriculum Learning(课程学习)综述网站首页技术交流
【论文阅读-TPAMI2021】Curriculum Learning(课程学习)综述
简介
Curriculum learning (CL,课程学习)是一种模型训练策略,通过先让模型学习简单数据后再学习困难数据的方式模拟学生进行课程学习的场景。通用的课程学习框架为Difficulty Measurer (困难程度评估)+ Training Scheduler(训练计划) 两部分,具体也可将课程学习方法分为如下几种策略:Self-paced Learning, Transfer Teacher, RL Teacher, and Other Automatic CL。
下图展示了课程学习的基本思路,先学习简单数据再学习复杂数据:
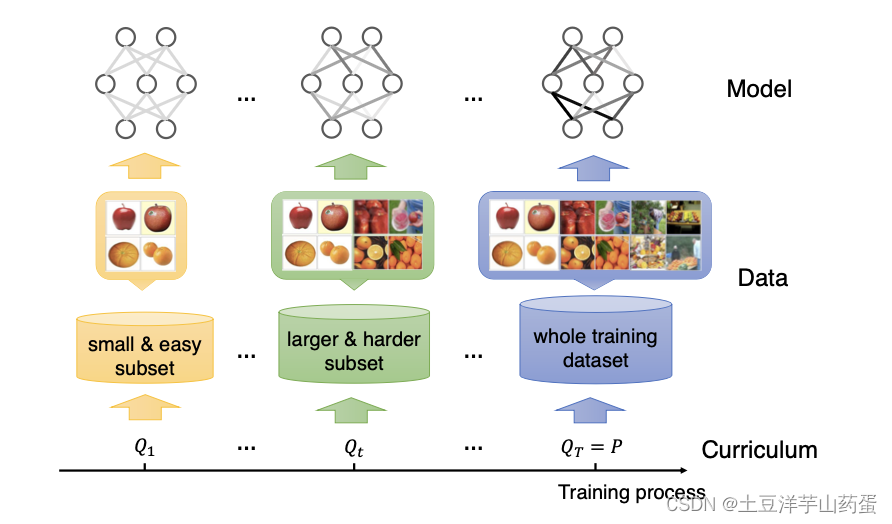
论文链接:https://arxiv.org/abs/2010.13166
CL具体思路
下图展示了CL具体方法的分类:
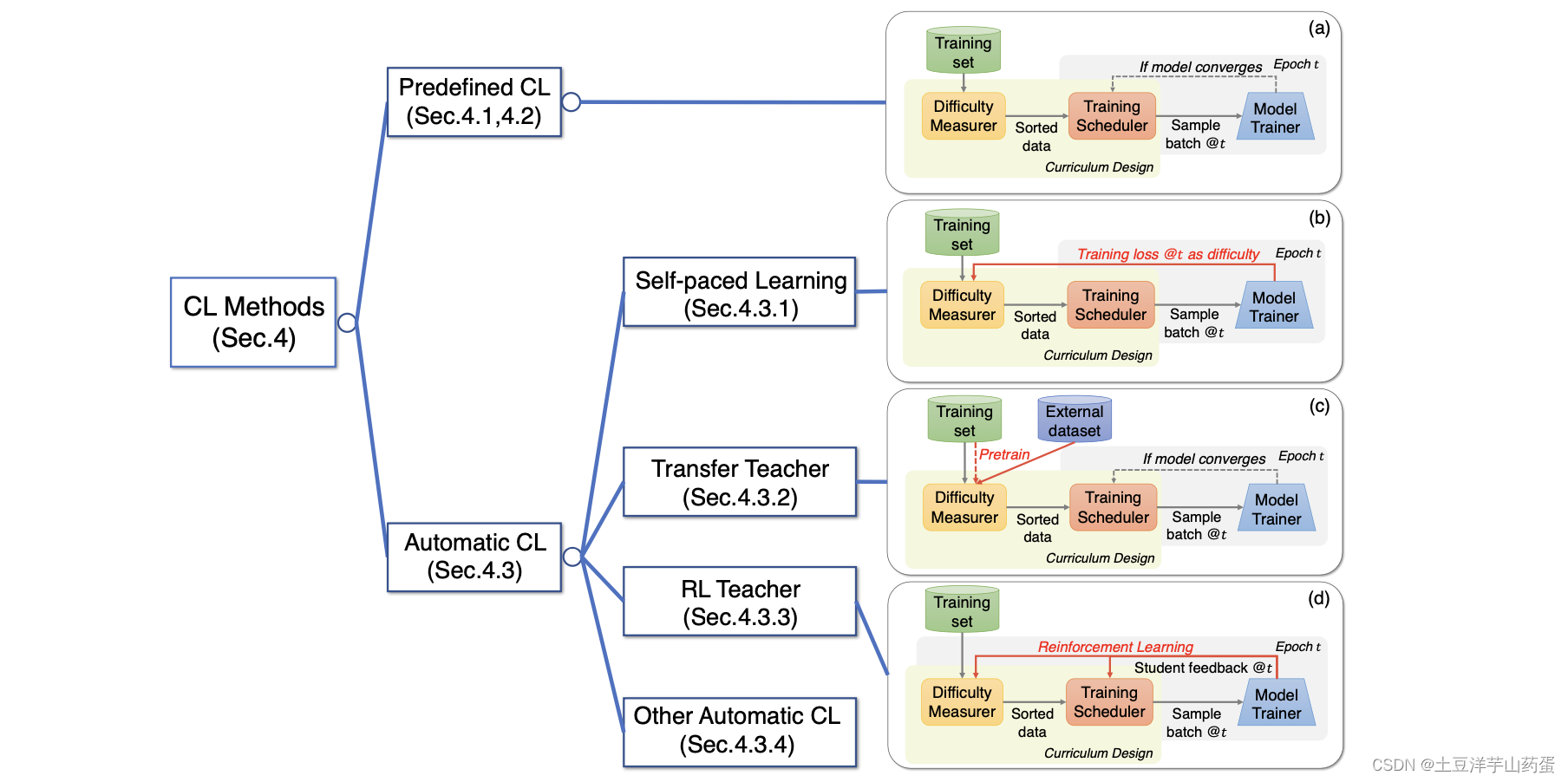
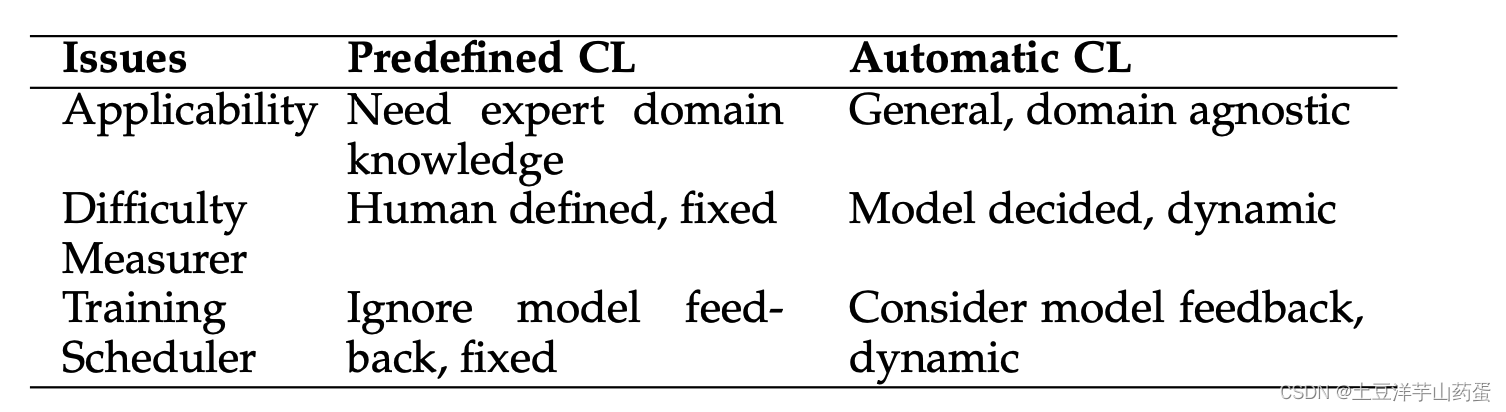
可以看出,这篇文章首先将CL的方法分为了预定义的CL和自动化的CL。在预定义的CL中,需要开发者手动评估样本学习的困难程度,然后根据困难程度将样本排序后进行训练。而自动的CL可以在模型的训练过程中动态的评估样本学习困难程度,然后调整模型训练时的输入。
预定义的CL
正如上面所说,CL的框架包含了Difficulty Measurers和Training Schedulers两部分。预定义的CL要求开发人员手动定义上述这两部分后进行训练。
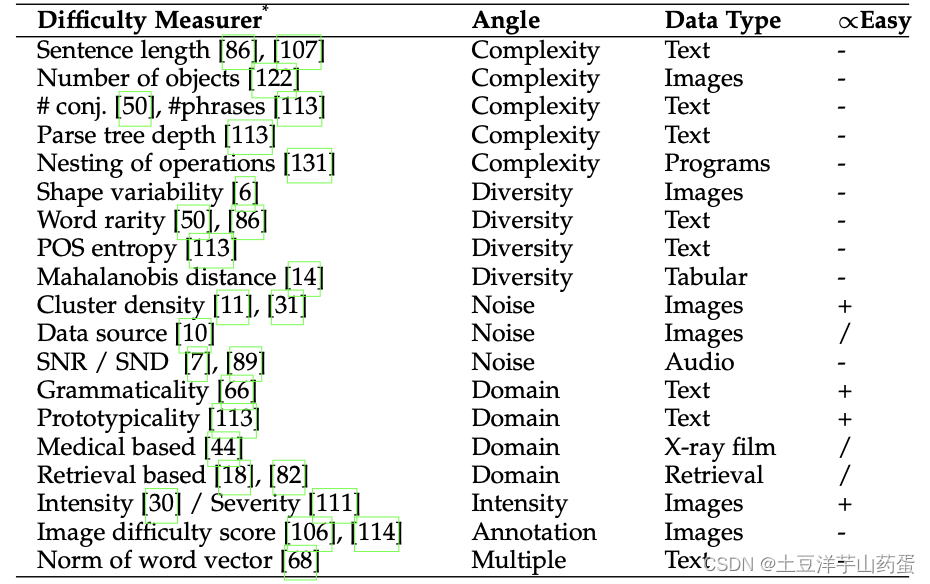
常见的预定义Difficulty Measurer
根据具体任务的特点可以定义出不同的Difficulty Measurer,下图展示了常见的Difficulty Measurer:
常见的预定义Training Scheduler
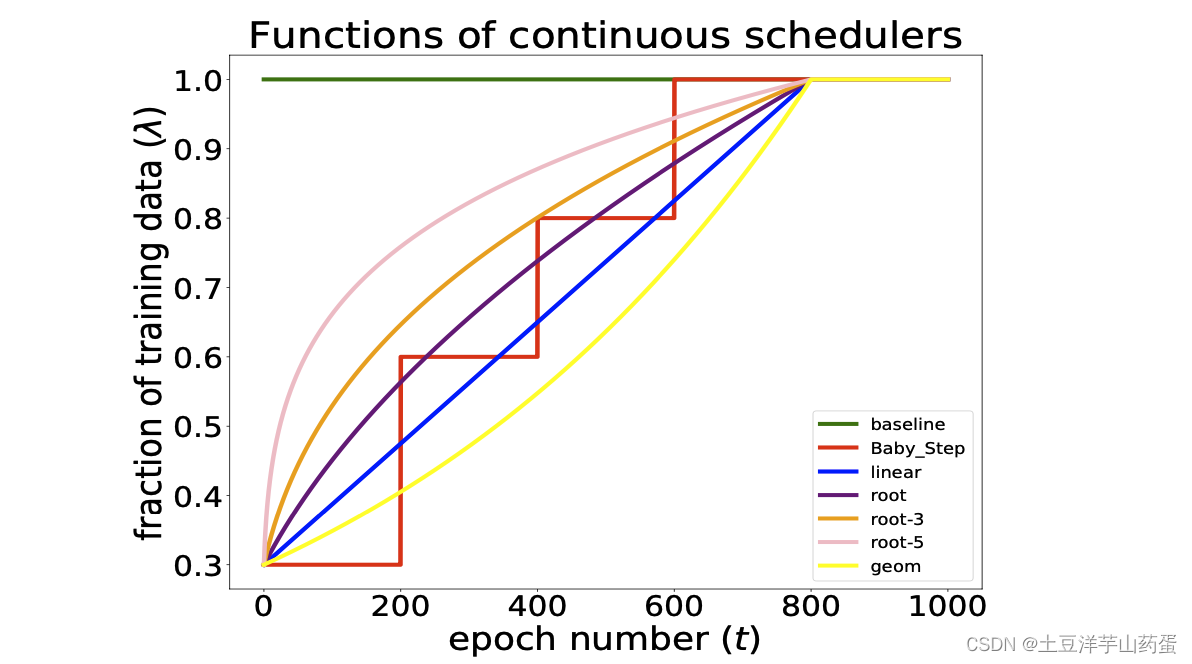
通常情况下,Training Schedulers可以分为离散(discrete)和连续(continuous)两种类型。离散的情况下模型会在收敛于某个数据子集或在数据子集上训练固定数量的epoch后调整训练数据子集。连续的情况下,模型会在每个epoch后调整训练数据子集。
离散的Training Scheduler经典方法-Baby Step如下:

相比较于在模型收敛后再加入新数据的离散策略,连续Training Scheduler数据增加方式更加平滑,下图展示了不同策略在不同epoch的训练数据变化情况
自动化的CL
预定义CL和自动化CL对比
不同自动化CL之间的对比

Self-paced Learning (SPL,自我学习)
学生通过自己定制课程进行迭代学习,SPL通常采用模型每个样本训练的loss作为衡量该样本学习困难程度的标准。SPL的主要优点为:SPL是一种基于loss的半自动化CL,将课程设计嵌入到原始机器学习任务的学习目标中,增加了方法的灵活性和对不同任务的适用性。
Transfer Teacher (老师教学)
引入额外的数据集,训练一个Teacher模型。迁移已经训练好的模型来评估的样本的困难程度,可以避免未充分训练的模型评估时的风险。
下面是常见的Transfer Teacher :

RL Teacher (强化学习老师)
SPL和Transfer Teacher 均使得Difficulty Measurer自动化了,但Training Scheduler还是用预定义的。在人类教学中,教学的策略会同时考虑老师和同学,学生给老师反馈,老师也要基于此调整教学策略。基于此,RL Teacher的方法中包含了学生模型和基于强化学习的老师模型,在每一个epoch的训练策略中,RL teacher会根据学生反馈动态选择训练数据。数据选择作为RL的action,学生反馈作为state和reward。
下面展示了CL常用的强化学习方法:

Other Automatic CL (其他自动化CL)
除了RL Teacher之外,还有一些全自动的CL方法。只管而言,这些设计应该要求课程的生成仅依赖于数据集、学生模型和任务目标。可以将课程视为一系列训练标准或目标,因此,从优化的角度来看,在每个训练epoch,我们希望优化以下映射以提高性能:{数据,学生模型的当前状态,任务目标}→ 训练目标。下面展示一些示例:

CL和其他数据相关ML概念的区别
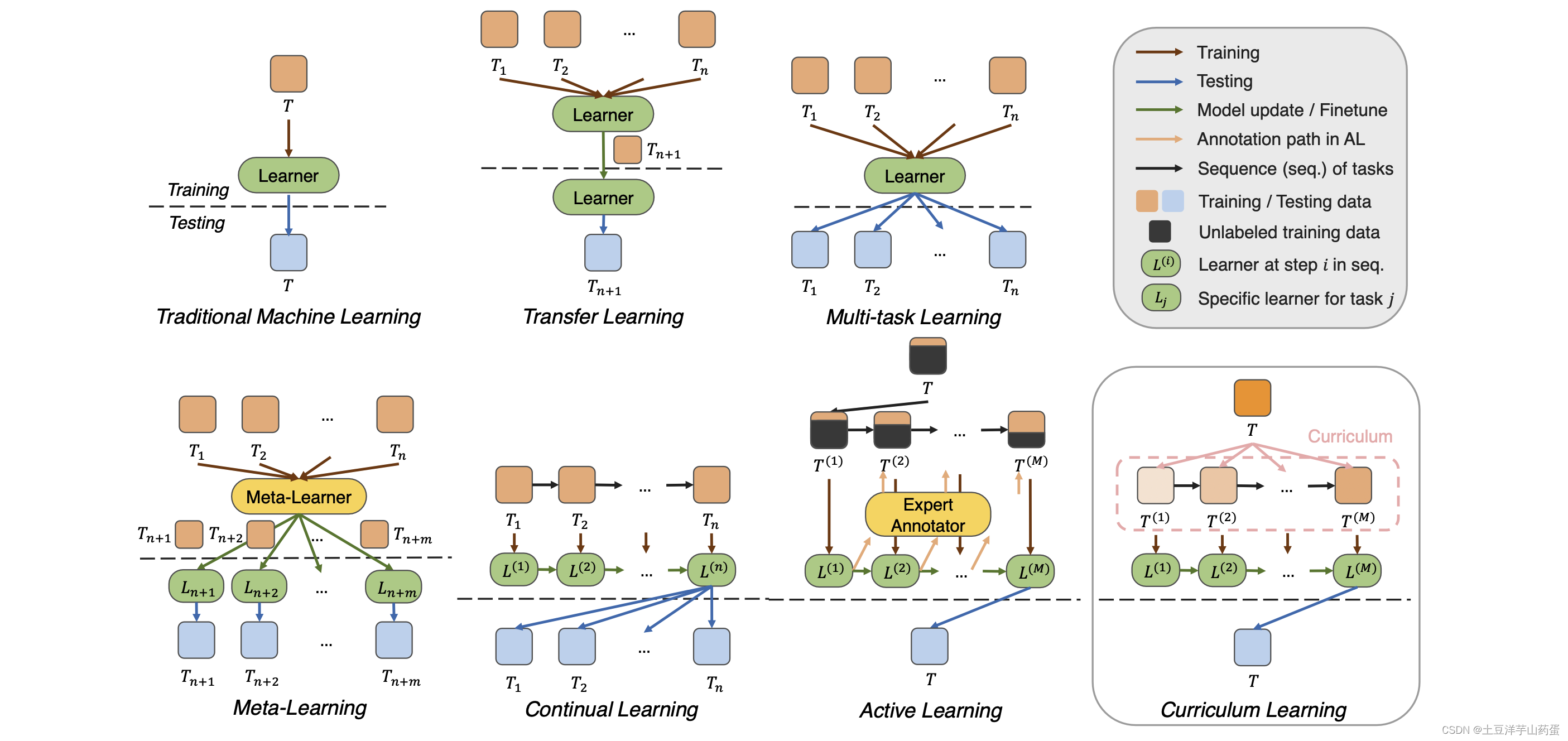
传统机器学习:利用训练集训练出模型,利用测试集测试模型性能。
迁移学习:首先在多个相关任务上训练模型,然后将模型能力迁移到
T
n
+
1
T_{n+1}
Tn+1个任务中,最后在第
T
n
+
1
T_{n+1}
Tn+1个任务上测试模型性能。
多任务学习:同时在多个任务上进行训练,然后在多个测试集的进行训练。
元学习:在多个任务中学习通用的元知识(common meta-knowledge),然后在不同目标任务上继续学习并更新模型,最后在目标任务测试集上进行测试。
持续学习:通过更新一个训练好的模型来克服遗忘,从而缓解在线任务序列之间的差异。
主动学习:主动学习者通过生成查询来要求专家对几个未标记的实例进行标注以进行进一步训练,从而在较少标记数据的情况下实现了良好的性能。
课程学习:通过一系列重新加权来消除测试分布和训练分布之间的差异,从而导致朝着目标逐步优化的过程。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结