您现在的位置是:首页 >技术教程 >使用 Conv1D-LSTM 进行时间序列预测:预测多个未来时间步【优化】网站首页技术教程
使用 Conv1D-LSTM 进行时间序列预测:预测多个未来时间步【优化】
未优化之前的版本见下,作者当时主要是为Mark这个项目,未进行深入分析。
使用 Conv1D-LSTM 进行时间序列预测:预测多个未来时间步
Introduction
通常有许多时间序列预测方法,例如 ARIMA、SARIMA 和 Holtz-winters,但是随着深度学习的出现,许多人开始使用 LSTM 进行时间序列预测。**那么为什么我们需要使用 Conv1D-LSTM/RNN 进行时间序列预测呢?**下面是我能想到的一些原因:
- Conv1D 层平滑了输入时间序列,因此我们不必将滚动平均或滚动标准差值添加到输入特征中。
- LSTM 可以模拟具有多个输入变量的问题。我们需要将 3D 输入向量作为 LSTM 的输入形状。
- 这为时间序列预测增加了很大的优势,传统的线性方法在适应多元或多输入预测问题时可能很难。 (对于多元预测问题,需要注意的是,当我们使用多元数据进行预测时,我们还需要“未来的多元”输入数据来预测未来结果!……为了缓解这种情况,我们有下面讨论的两种方法。)
- 灵活性使用多种 seq2seq LSTM 模型组合来预测时间序列 - 多对一模型(在我们想要给出所有先前输入的情况下预测当前时间步长时很有用),多对多模型(在我们希望一次预测多个未来时间步长时很有用)以及这些变体的其他几种组合。
seq2seq LSTM 指的是序列到序列(sequence-to-sequence) LSTM 模型,也称为编码器-解码器(encoder-decoder) LSTM 模型
在本篇文章中,将重点介绍 many-to-many 模型。在这种情况下,我们可以用两种不同的方法来解决问题。
迭代预测或自回归方法: 创建一个包含前几个时间步的滑动窗口,来预测当前时间步的值,然后进行预测。现在,将当前预测值添加回窗口中,以便在下一个时间步进行预测,以此类推。这种方法相对较简单,但会在每个时间步骤上累积误差,而且预测结果不太准确。
直接预测或单次预测: 创建一个包含前几个时间步的滑动窗口,来预测未来的值。在这里,我们使用“K”步预测方法。也就是说,“K”的值,即我们想要预测多少时间步骤的数据,需要提前给出。

本文的核心思想和数学方程式来自于一篇研究论文。我尝试使用这个直接预测的技术来预测未来 30 天的 the Global active power。
Time Series Forecasting Using LSTM Networks: A Symbolic Approach
Okay, lets do some coding!
读取数据
这里的数据需要私信给作者获取。
# Read the data
df = pd.read_csv('./data/household_power_consumption.txt',
parse_dates={'dt' : ['Date', 'Time']},
sep=";", infer_datetime_format=True,
low_memory=False, na_values=['nan','?'], index_col='dt')
# The first five lines of df is shown below
df.head()
# we use "dataset_train_actual" for plotting in the end.
dataset_train_actual = df.copy()
# create "dataset_train for further processing
dataset_train = df.copy()
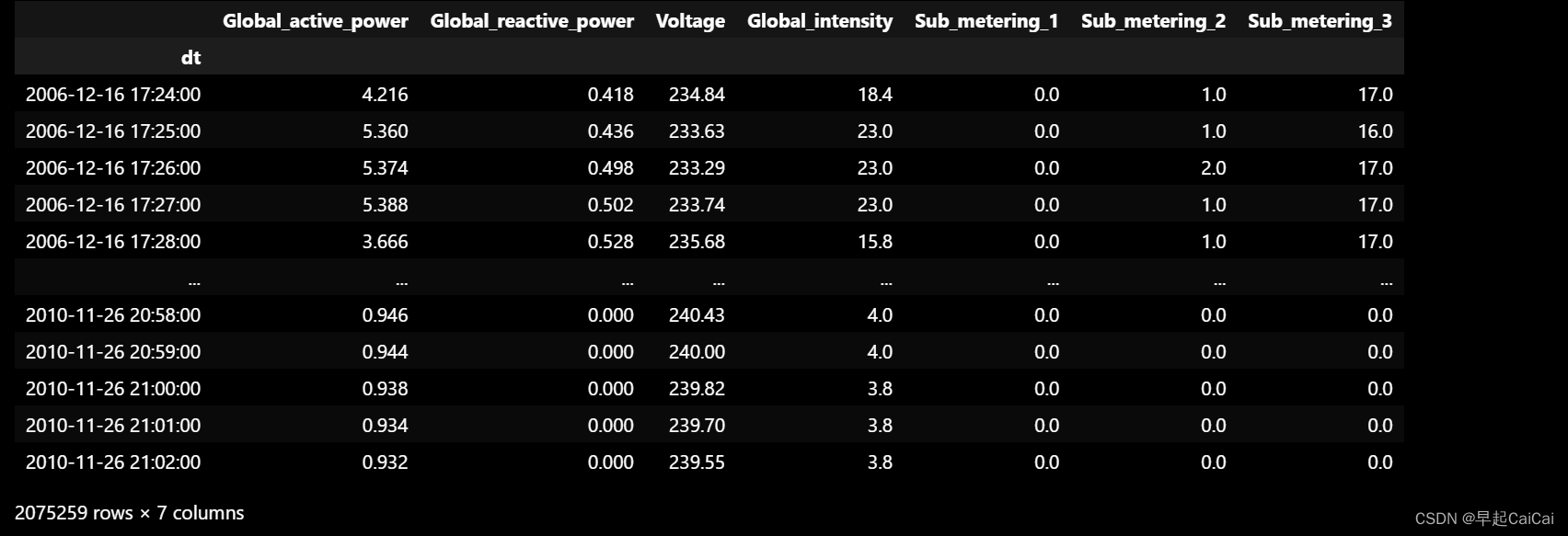
这段代码用于读取一个家庭用电量数据集,并将其转化为 Pandas 数据框(DataFrame)格式。
首先,使用 import pandas as pd 导入 Pandas 库。接着,使用 pd.read_csv 函数读取名为 “household_power_consumption.txt” 的 CSV 文件,并将其转化为 Pandas 数据框对象 df。在读取 CSV 文件时,使用 parse_dates 参数将 “Date” 列和 “Time” 列合并为一个名为 “dt” 的日期时间列,并使用 sep=";" 参数指定列分隔符为分号。infer_datetime_format=True 参数告诉 Pandas 尝试自动解析日期时间格式,low_memory=False 参数表示一次性读取所有数据,na_values=['nan','?'] 参数表示将数据中的 “nan” 和 “?” 字符识别为缺失值。最后,使用 index_col='dt' 参数将 “dt” 列设置为数据框的索引。
然后,使用 df.head() 函数打印数据框的前五行,以便查看数据结构和内容。接着,使用 dataset_train_actual = df.copy() 将数据框复制一份,用于后续的可视化。最后,使用 dataset_train = df.copy() 将数据框再次复制一份,用于进一步的数据预处理。
数据处理
现在创建 training_set,它是一个二维的 NumPy 数组。
# Select features (columns) to be involved intro training and predictions
dataset_train = dataset_train.reset_index()
cols = list(dataset_train)[1:8]
# Extract dates (will be used in visualization)
datelist_train = list(dataset_train['dt'])
datelist_train = [date for date in datelist_train]
training_set = dataset_train.values
这段代码用于从数据集中选择用于训练和预测的特征(列),并创建一个二维的 NumPy 数组 training_set,其中包含了选定特征的所有数据。
首先,使用 dataset_train.reset_index() 将数据集的索引重置,以便使用时间步长作为索引。接着,使用 list(dataset_train)[1:8] 选择第 1 到第 7 列的特征(排除了索引和最后一列的标签),并将其作为列表 cols 存储。然后,使用 list(dataset_train['dt']) 提取日期列表,该列表将用于可视化。最后,将日期转换为 Python 的 date 类型,并将其存储在 datelist_train 列表中。
接下来,使用 dataset_train.values 将 Pandas 数据框对象转换为 NumPy 数组,并将其存储在 training_set 中。training_set 数组包含了所有选定特征的数据,每一行代表一个时间步长的数据,每一列代表一种特征。
特征缩放
创建两个缩放器,一个用于输入特征,另一个用于目标值的缩放。需要注意的是,“Global active power”列也包含在输入特征中。
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
training_set_scaled = sc.fit_transform(training_set)
sc_predict = StandardScaler()
sc_predict.fit_transform(training_set[:, 0:1])
PASS:这里包含一个问题,时间的属性是有问题的。
创建网络训练数据结构
创建训练数据的数据结构:
# Creating a data structure with 72 timestamps and 1 output
X_train = []
y_train = []
n_future = 30 # Number of days we want to predict into the future.
n_past = 72 # Number of past days we want to use to predict future.
for i in range(n_past, len(training_set_scaled) - n_future +1):
X_train.append(training_set_scaled[i - n_past:i,
0:dataset_train.shape[1]])
y_train.append(training_set_scaled[i+n_future-1:i+n_future, 0])
X_train, y_train = np.array(X_train), np.array(y_train)
print('X_train shape == {}.'.format(X_train.shape))
print('y_train shape == {}.'.format(y_train.shape))
这段代码用于创建训练数据的数据结构,其中历史时间步长的长度为 72,预测期的长度为 30。这段代码将历史时间步长的数据和对应的目标数据组合在一起,并将它们添加到 X_train 和 y_train 中。
具体来说,对于每个时间步长,代码将使用前 72 个时间步长的数据作为输入特征,以及下一个时间步长的标签作为目标值。然后将所有的输入特征和目标值添加到 X_train 和 y_train 数组中,以便用于模型的训练。
最后,将 X_train 和 y_train 转换为 NumPy 数组,并打印它们的形状。其中,X_train 的形状为 (num_samples, n_past, num_features),y_train 的形状为 (num_samples, 1)。
需要注意的是,这段代码中的 training_set_scaled 数组是经过缩放的数据集,其形状为 (num_samples, num_features)。在这里,我们将其转换为一个包含历史时间步长和目标值的二维数组,以便用于模型的训练。
如果我们使用 [0:72] 行和所有输入列的输入特征值,则学习到的目标值是数据中 [72+30–1:72+30] 行和一个目标列。因为我们直接预测未来的 30 个值,所以我们的模型是这样学习的:对于每个输入特征块(我们的回溯值为 72),目标值是前 30 个时间步长。
模型训练
以下是用于创建训练模型的代码,其中使用了卷积神经网络、双向 LSTM 和全连接层:
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Conv1D(filters=32, kernel_size=3,
strides=1, padding="causal",
activation="relu",
input_shape=[None, 7]),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, return_sequences=False)),
tf.keras.layers.Dense(1),
tf.keras.layers.Lambda(lambda x: x * 200)])
# lr_schedule = tf.keras.callbacks.LearningRateScheduler(
# lambda epoch: 1e-8 * 10**(epoch / 20))
optimizer = tf.keras.optimizers.SGD(lr=1e-5, momentum=0.9)
model.compile(loss=tf.keras.losses.Huber(),
optimizer=optimizer,
metrics=["mse"])
在上面的代码中,首先创建了一个序列模型(Sequential),然后将卷积层(Conv1D)、双向 LSTM 层(Bidirectional)、全连接层(Dense)和 Lambda 层(Lambda)依次添加到模型中。
其中,卷积层用于提取时间序列数据的特征,双向 LSTM 层用于处理时序数据,全连接层用于将 LSTM 层的输出映射到预测值,Lambda 层用于对输出进行缩放。
模型的优化器使用 SGD,并将学习率设置为 1e-5,动量设置为 0.9。损失函数使用 Huber 损失函数,评估指标使用均方误差(mse)。
动量(Momentum)是一个改进SGD的方法。
使用动量的原理是,在梯度下降的过程中,当前的更新不仅仅考虑当前的梯度,还考虑过去几个步骤的梯度。
这有两个好处:
1.可以加速收敛
2.可以避免局部极小值
结果展示
PASS: 由于这里有个Bug未解决(上文中也提到),时间戳在特征放缩时不能处理,后期的结果均未实践的,为博客自身的处理结果。(这个实际教程数据处理与博客不一致)
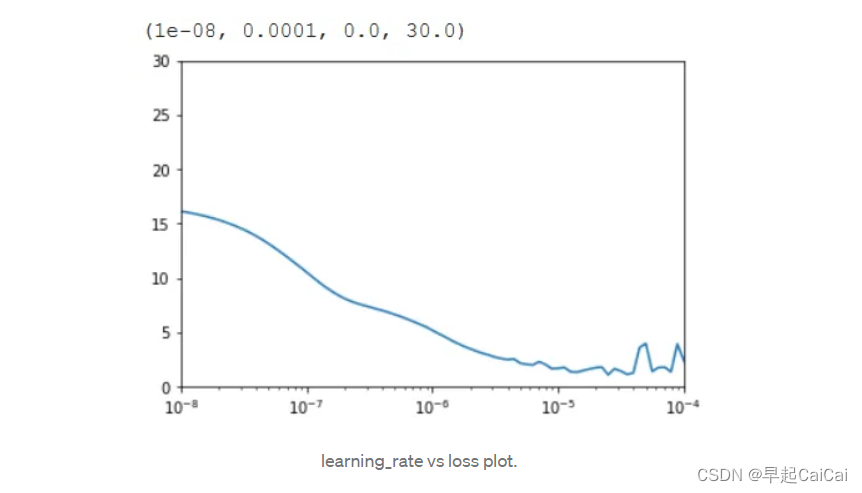
我使用学习率为1e-5,在使用上述使用 lr_schedule(学习率衰减策略)的模型进行训练后,并绘图(学习率对损失的图样),如下图所示。
import matplotlib.pyplot as plt
plt.semilogx(history.history["lr"], history.history["loss"])
plt.axis([1e-8, 1e-4, 0, 30])
计算和预测未来
Calculating the predictions into future.
# Perform predictions
predictions_future = model.predict(X_train[-n_future:])
# getting predictions for training data for plotting purpose
predictions_train = model.predict(X_train[n_past:])
y_pred_future = sc_predict.inverse_transform(predictions_future)
y_pred_train = sc_predict.inverse_transform(predictions_train)
# Construct two different dataframes for plotting.
PREDICTIONS_FUTURE = pd.DataFrame(y_pred_future, columns=['Global_active_power']).set_index(pd.Series(datelist_future))
PREDICTION_TRAIN = pd.DataFrame(y_pred_train, columns=['Global_active_power']).set_index(pd.Series(datelist_train[2 * n_past + n_future -1:]))
这段代码主要做两件事:
- 预测未来n_future个时间点的数据
- 为可视化目的,预测训练数据中的一部分
主要步骤是:
- 使用model.predict()方法,分别预测未来n_future个数据点和训练数据的一部分
predictions_future = model.predict(X_train[-n_future:])
predictions_train = model.predict(X_train[n_past:])
- 将预测值通过之前 fitted 的 scaler 反转变换
y_pred_future = sc_predict.inverse_transform(predictions_future)
y_pred_train = sc_predict.inverse_transform(predictions_train)
- 将预测值构造成两个DataFrame,可以用于绘图
PREDICTIONS_FUTURE = pd.DataFrame(y_pred_future, columns=['Global_active_power']).set_index(datelist_future)
PREDICTION_TRAIN = pd.DataFrame(y_pred_train,columns=['Global_active_power']).set_index(datelist_train[2 * n_past + n_future -1:])
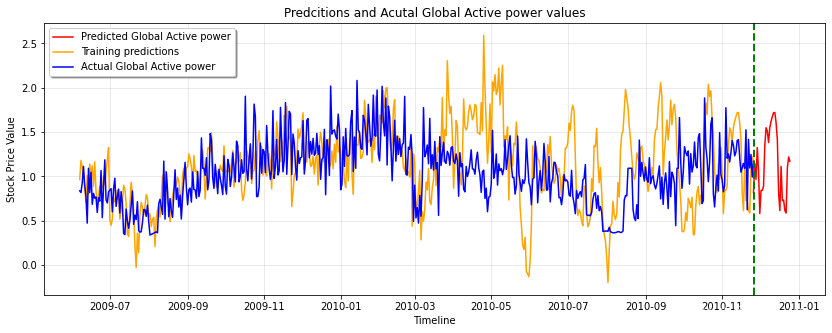
可视化预测结果
# Set plot size
plt.rcParams['figure.figsize'] = 14, 5
# Plot parameters
START_DATE_FOR_PLOTTING = '2009-06-07'
# plot the target column in PREDICTIONS_FUTURE dataframe
plt.plot(PREDICTIONS_FUTURE.index, PREDICTIONS_FUTURE['Global_active_power'], color='r', label='Predicted Global Active power')
# plot the target column in PREDICTIONS_TRAIN dataframe
plt.plot(PREDICTION_TRAIN.loc[START_DATE_FOR_PLOTTING:].index, PREDICTION_TRAIN.loc[START_DATE_FOR_PLOTTING['Global_active_power'], color='orange', label='Training predictions')
# plot the target column in input dataframe
plt.plot(dataset_train_actual.loc[START_DATE_FOR_PLOTTING:].index, dataset_train_actual.loc[START_DATE_FOR_PLOTTING:]['Global_active_power'], color='b', label='Actual Global Active power')
plt.axvline(x = min(PREDICTIONS_FUTURE.index), color='green', linewidth=2, linestyle='--')
plt.grid(which='major', color='#cccccc', alpha=0.5)
plt.legend(shadow=True)
plt.title('Predcitions and Acutal Global Active power values', family='Arial', fontsize=12)
plt.xlabel('Timeline', family='Arial', fontsize=10)
plt.ylabel('Stock Price Value', family='Arial', fontsize=10)
上面的代码主要涉及以下变量:
- dataset_train_actual: 包含实际训练数据(需要预测的目标变量)
- PREDICTIONS_FUTURE:包含未来 predicting 数据(模型产生的预测值)
- PREDICTION_TRAIN:包含训练 predicting 数据(模型在训练数据上的预测值)
主要做了以下事情:
- 设置绘图大小
- 定义一些绘图参数,例如起始日期
- 绘制PREDICTIONS_FUTURE中"Global_active_power"列(对应未来预测值)的图形
- 绘制 PREDICTION_TRAIN[START_DATE_FOR_PLOTTING:] 中"Global_active_power"列(对应训练数据上的预测值)的图形
- 绘制 dataset_train_actual[START_DATE_FOR_PLOTTING:] 中"Global_active_power "列(实际训练数据)的图形
- 添加网格线,图例,标题等图形元素
通过绘制这三条线图,可以很直观地比较模型在未来预测和训练期间的表现。
Reference
使用 Conv1D-LSTM 进行时间序列预测:预测多个未来时间步
Time-series Forecasting using Conv1D-LSTM : Multiple timesteps into future
Individual household electric power consumption Data Set





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结