您现在的位置是:首页 >技术交流 >【C++】数据结构的恶龙set和map来了~网站首页技术交流
【C++】数据结构的恶龙set和map来了~
下一篇AVL树难点中的难点~
前言
1.关联式容器
一、set的介绍
void test_set1()
{
set<int> st;
st.insert(1);
st.insert(2);
st.insert(3);
st.insert(1);
st.insert(3);
st.insert(4);
set<int>::iterator it = st.begin();
while (it != st.end())
{
cout << *it << " ";
++it;
}
}
int main()
{
test_set1();
return 0;
}set的使用与我们之前学的容器相差不大,大家只需要记住set的作用是排序+去重,当然set既然支持迭代器那么也肯定支持范围for了。
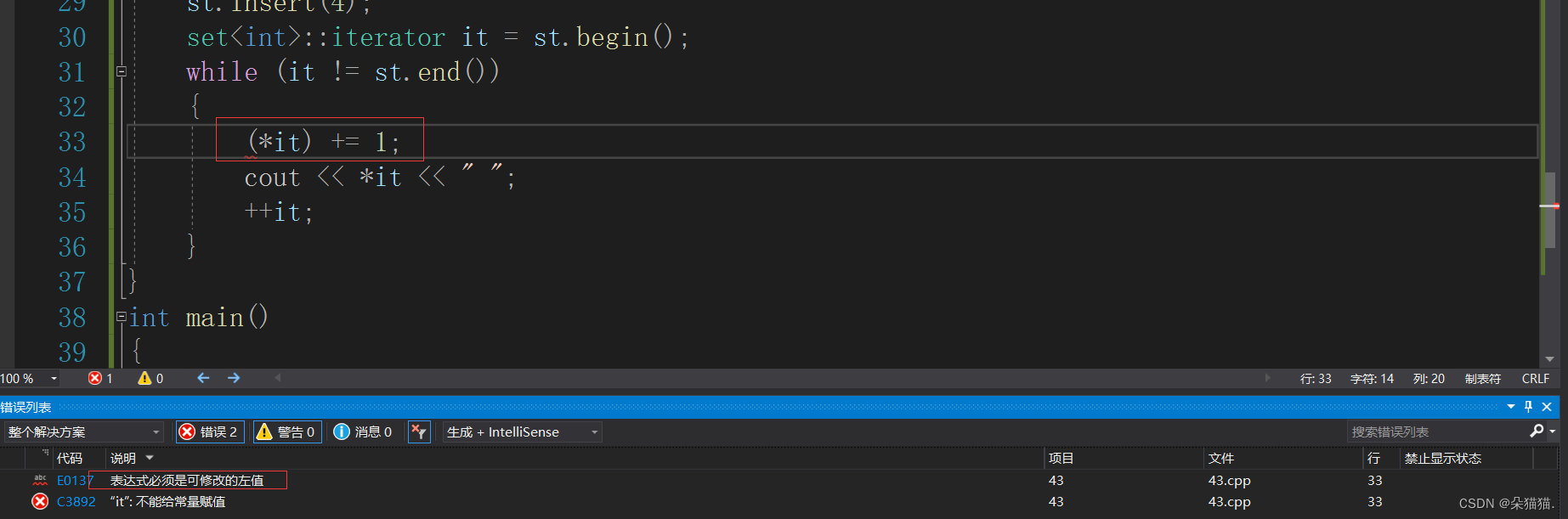
在这里我们要注意,set是不支持修改里面的值的,因为一旦修改了就不能保持搜索二叉树的特性了。下面我们演示一下set中的find和count接口:
void test_set2()
{
set<int> st;
st.insert(1);
st.insert(2);
st.insert(3);
st.insert(1);
st.insert(3);
st.insert(4);
auto it = st.find(4);
if (it != st.end())
{
cout << "要查询的值存在:" << *it << endl;
}
else
{
cout << "不存在" << endl;
}
}
int main()
{
//test_set1();
test_set2();
return 0;
}void test_set2()
{
set<int> st;
st.insert(1);
st.insert(2);
st.insert(3);
st.insert(1);
st.insert(3);
st.insert(4);
if (st.count(4))
{
cout << "要查询的值存在" << endl;
}
else
{
cout << "不存在" << endl;
}
}在set中我们确认一个值用count接口会比find更方便,因为如果存在那么count一定是1,如果不存在则是0.count这个接口是为了和multiset中的count对应。
下面我们来看看multiset:
void test_set3()
{
multiset<int> st;
st.insert(1);
st.insert(2);
st.insert(3);
st.insert(1);
st.insert(3);
st.insert(4);
for (auto& e : st)
{
cout << e << " ";
}
}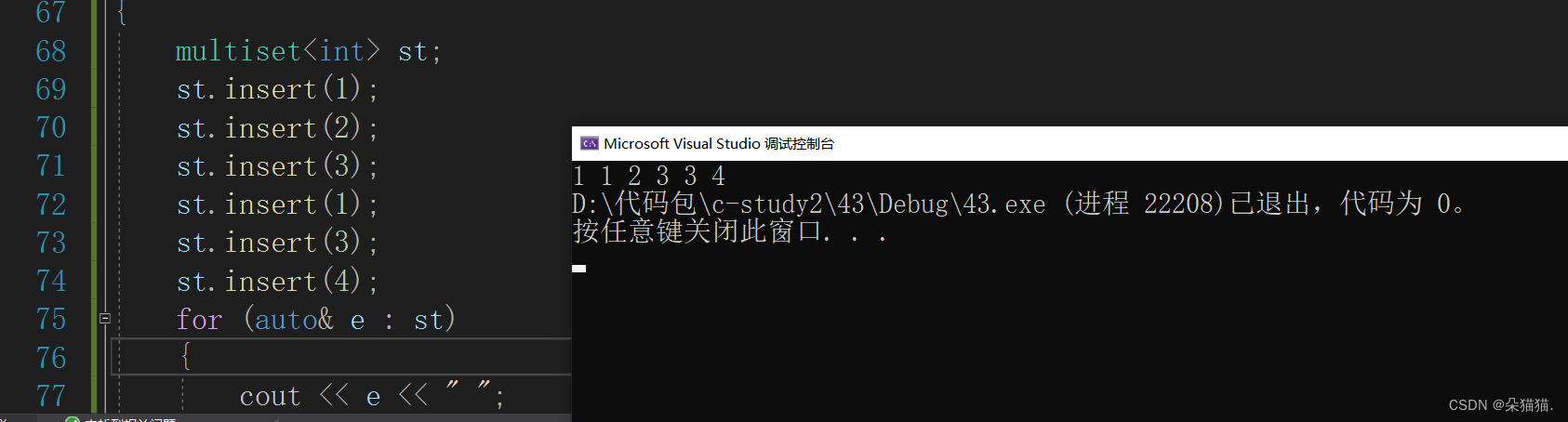
通过结果我们可以看到multiset的功能仅仅是排序,并不会去重,下面我们看看刚刚说到的multiset中的count:
void test_set3()
{
multiset<int> st;
st.insert(1);
st.insert(2);
st.insert(3);
st.insert(1);
st.insert(3);
st.insert(4);
for (auto& e : st)
{
auto it = st.find(e);
if (it != st.end())
{
cout << e << "的个数为:" << st.count(e) << endl;
}
else
{
cout << "找不到" << endl;
}
}
}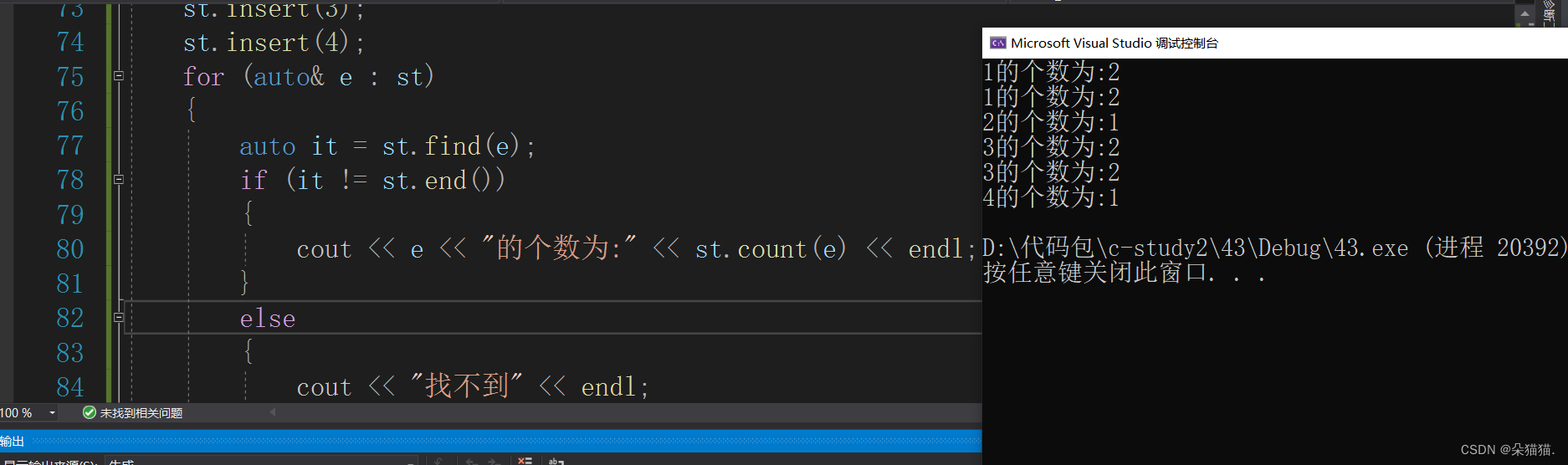
我们可以看到在multiset中count可以准确的计算元素的数量,下面我们看看find接口:
void test_set3()
{
multiset<int> st;
st.insert(1);
st.insert(1);
st.insert(1);
st.insert(1);
st.insert(1);
st.insert(1);
auto it = st.find(1);
while (it != st.end()&&*it == 1)
{
cout << *it << " ";
++it;
}
}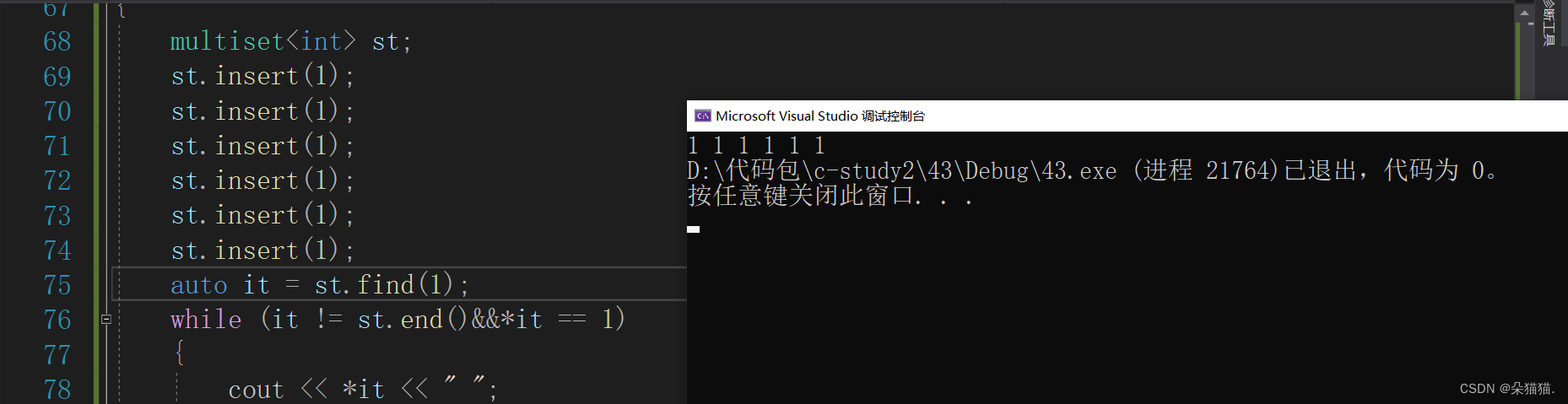
对于find接口来讲,查找到的元素一定是中序遍历的第一个元素,如果不是这样的原则我们上面的打印是不会将所有1打印出来的。
set的其他接口我们就不再演示了,因为与其他STL容易相差并不大,只需要记住几个有差异的接口就可以了。
二、map的介绍

我们前面已经说过了,map里面存的是键值对,下面我们演示一下map的使用:
void test_map1()
{
map<string, string> mp;
mp.insert(make_pair("string", "字符串"));
mp.insert(make_pair("left", "左边"));
mp.insert(make_pair("right", "右边"));
mp.insert(make_pair("erase", "删除"));
mp.insert(make_pair("string", "字符串2"));
auto it = mp.begin();
while (it != mp.end())
{
cout << (*it).first << ":" << (*it).second << endl;
++it;
}
}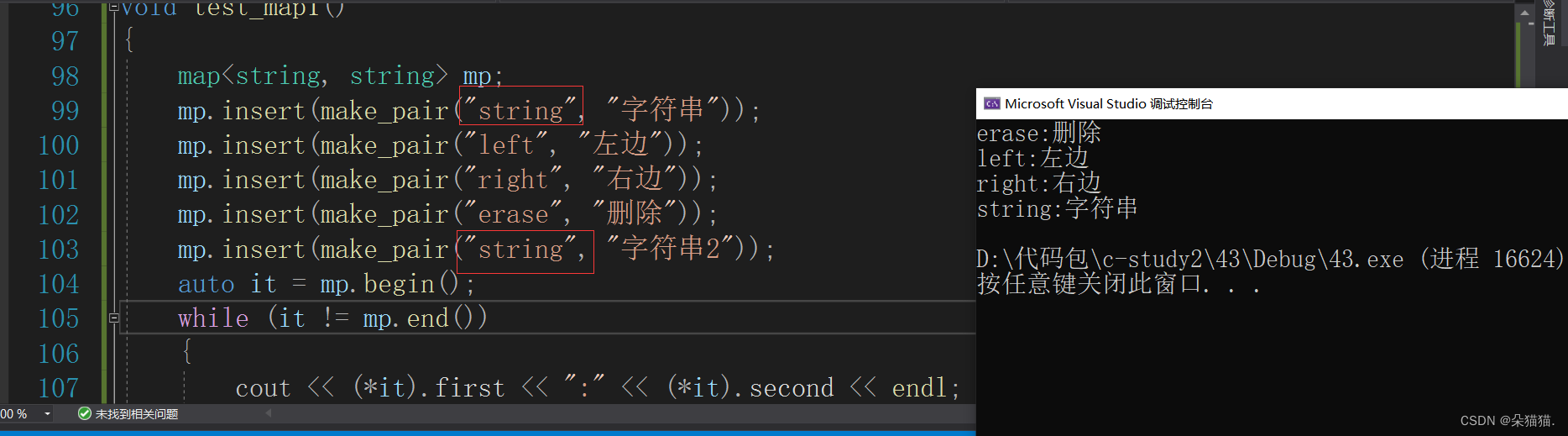
我们可以看到map同样是排序+去重,当然如果看不懂make_pair是什么那么我们写的再原始一点:
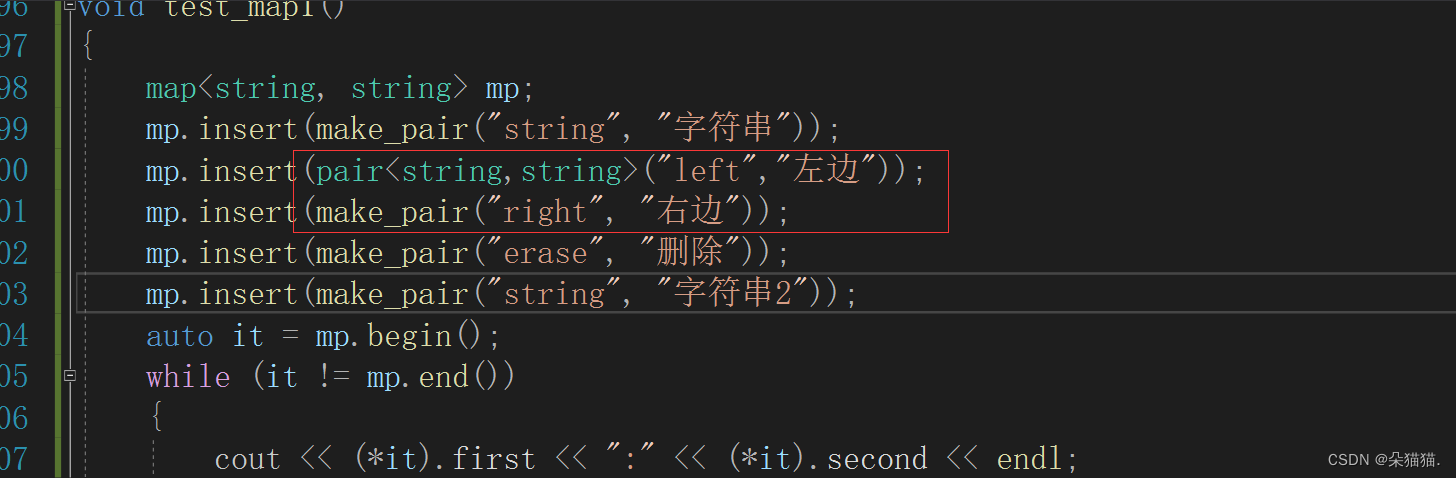
如上图所示绿色的是原始的pair插入,对于打印为什么是first和second呢?因为pair这个结构里存的就是K,V键值对,并且first代表key,second代表value.当然还记得我们在写反向迭代器的时候重载的那个->符号吗,在这里也有哦:
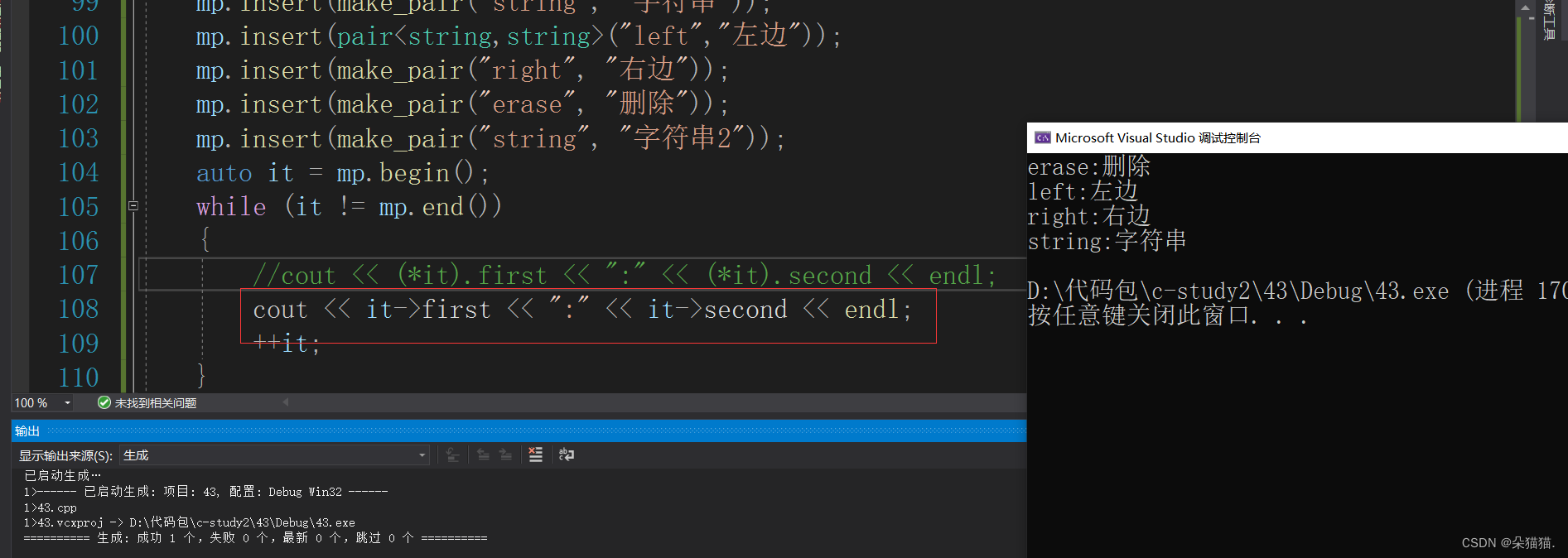
在这里->本来要用两次,因为首先访问到结构体,其次再访问到结构体里的first或者second,但是现在一个->就搞定了因为重载了->符号。下面我们讲一下在map中最重要的[]符号:
void test_map2()
{
map<string, int> mp;
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉",
"苹果", "香蕉" };
for (auto& e : arr)
{
auto it = mp.find(e);
if (it == mp.end())
{
mp.insert(make_pair(e, 1));
}
else
{
it->second++;
}
}
for (auto& m : mp)
{
cout << m.first << ":" << m.second << endl;
}
}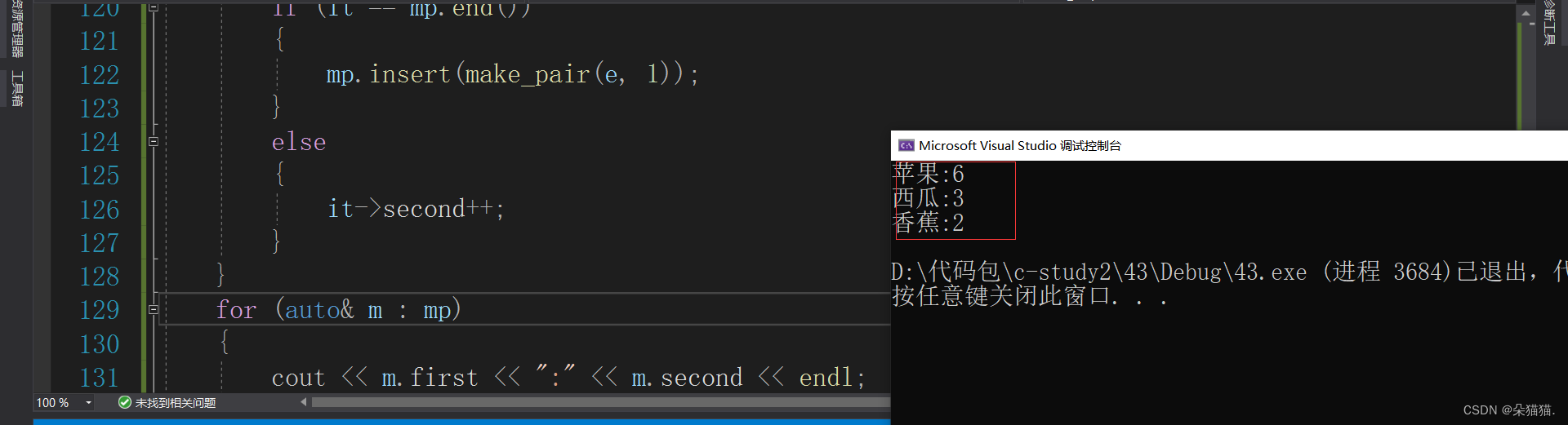
还记得我们学二叉搜索树的时候用的水果的例子吗?当我们树中已经存在这个水果了我们就让水果的count++,如果不存在这个水果我们就让插入并且count值为1,如今有了方括号我们1行代码就能搞定:
void test_map2()
{
map<string, int> mp;
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉",
"苹果", "香蕉" };
for (auto& e : arr)
{
mp[e]++;
}
for (auto& m : mp)
{
cout << m.first << ":" << m.second << endl;
}
}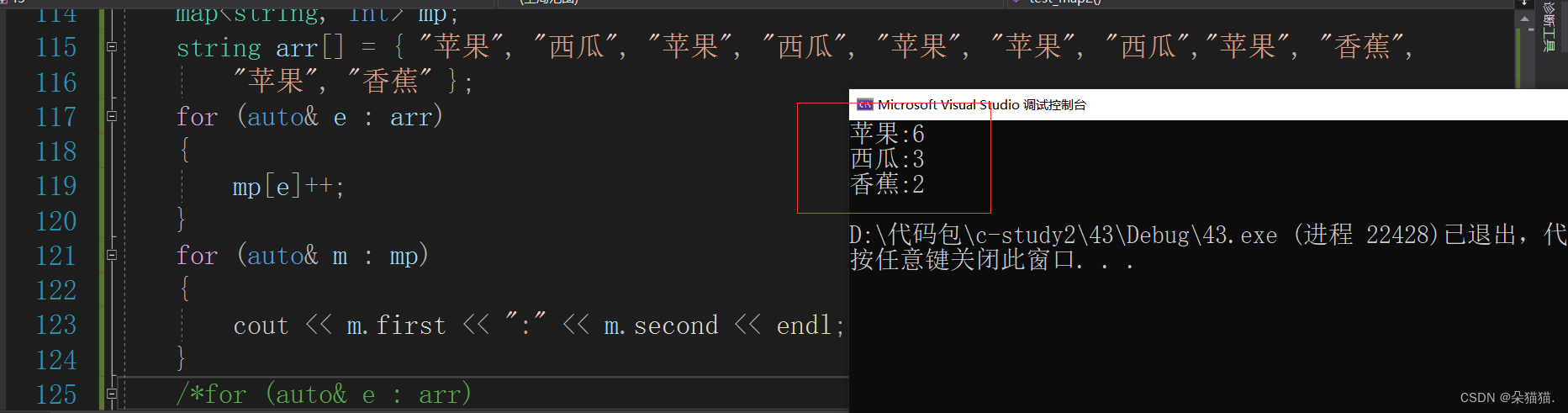
是不是很神奇呢?下面我们来重点介绍一个[]运算符:
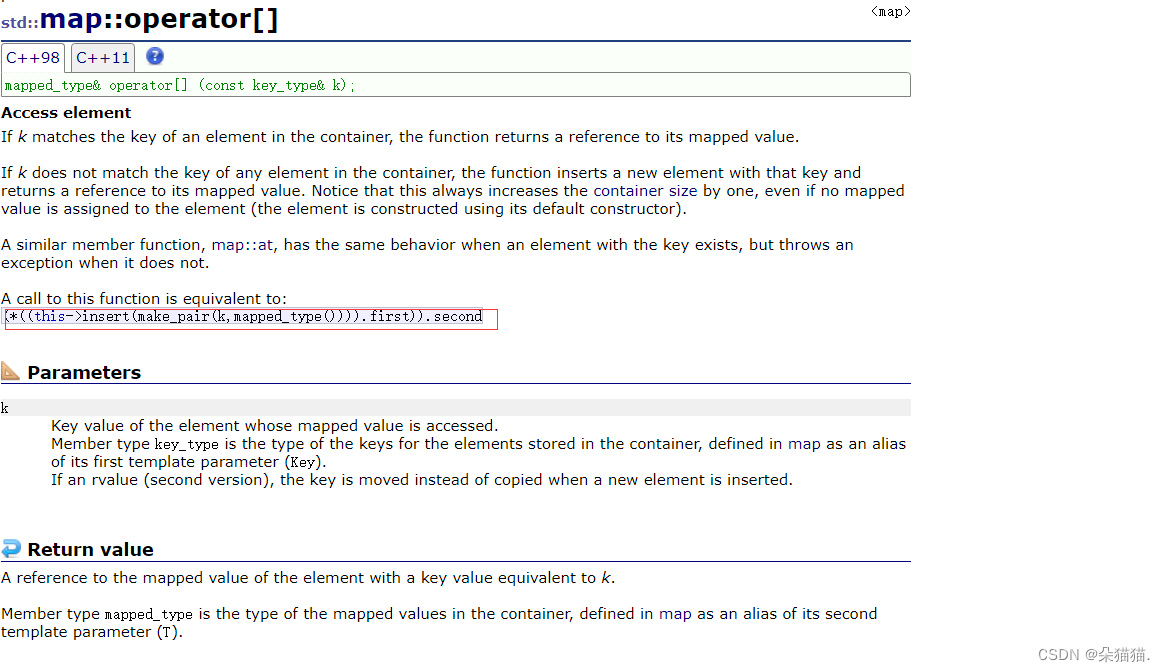
从文档中我们可以知道[]有多个作用,首先我们要看懂[]的返回值,如果要插入的值在当前树中不存在我们就插入,如果存在(如何判断是否存在是因为插入有一个bool值)就返回second的值(准确来说是引用),这也就解释了我们刚刚那个代码,因为当要插入的水果不存在的时候就直接帮我们插入了,并且插入后返回了此种水果的次数,然后我们后置++让这个水果变成了1次,后面如果发现这种水果已经被插入了就不在插入了但是返回值返回的是水果的次数的引用所以我们会再次++让次数变成2,然后重复。也就是说[]有四个作用:1.插入 2.修改 3.插入+修改 4.查找
void test_map1()
{
map<string, string> mp;
mp.insert(make_pair("string", "字符串"));
mp.insert(make_pair("right", "右边"));
mp.insert(make_pair("erase", "删除"));
mp["left"]; //仅仅插入
mp["second"] = "第二"; //插入加修改 因为返回值是second,我们将默认的second修改为"第二"
mp["string"] = "字符串2"; //修改
cout << mp["string"] << endl; //查找
auto it = mp.begin();
while (it != mp.end())
{
cout << it->first << ":" << it->second << endl;
++it;
}
}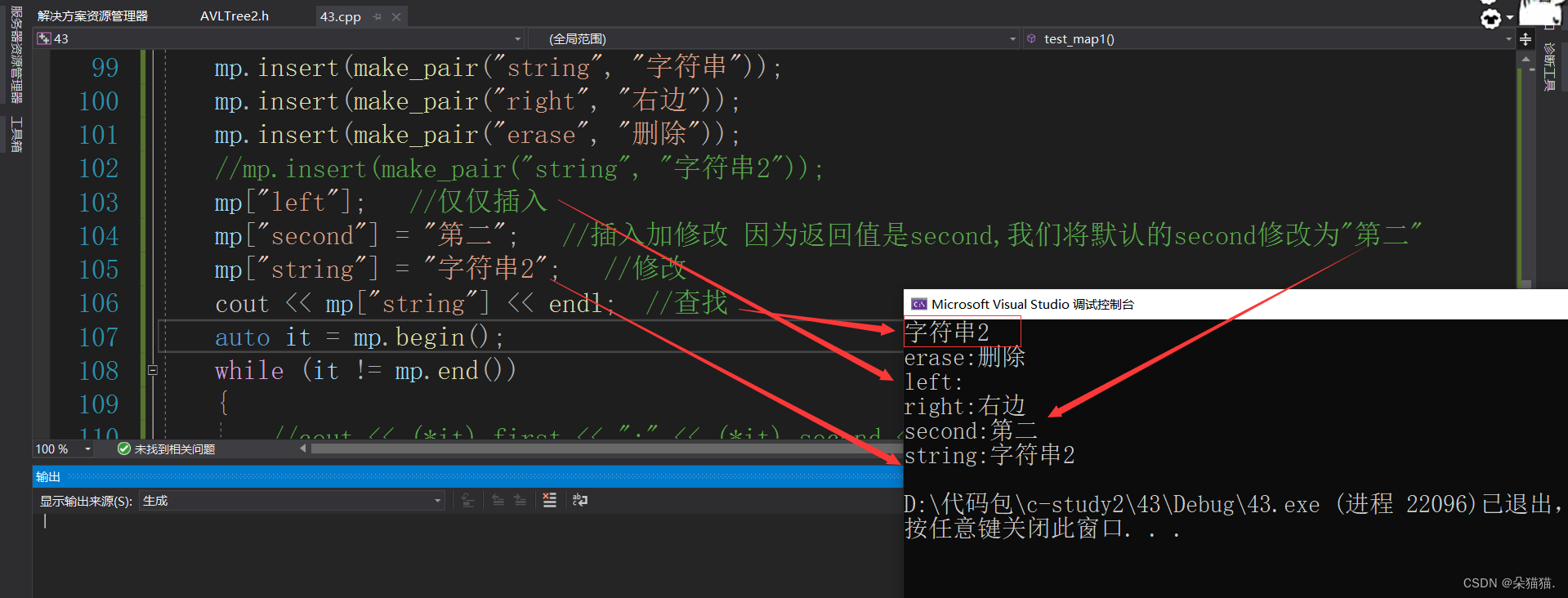
如果我们仅仅想要用[]插入,这个时候插入的是key模型,value会使用缺省值,比如我们方面的插入left,最后打印发现left的value值为空,这就可以验证当value的类型为字符串时缺省值为空字符串,当我们想要插入加修改时,因为[]的返回值为value的引用,所以相当于我们把缺省值修改为自己想要的value值,如果仅仅要对某个key的value值修改我们可以借助[]的返回值进行修改,以上就是map的一些知识,下面我们讲解multimap的知识:
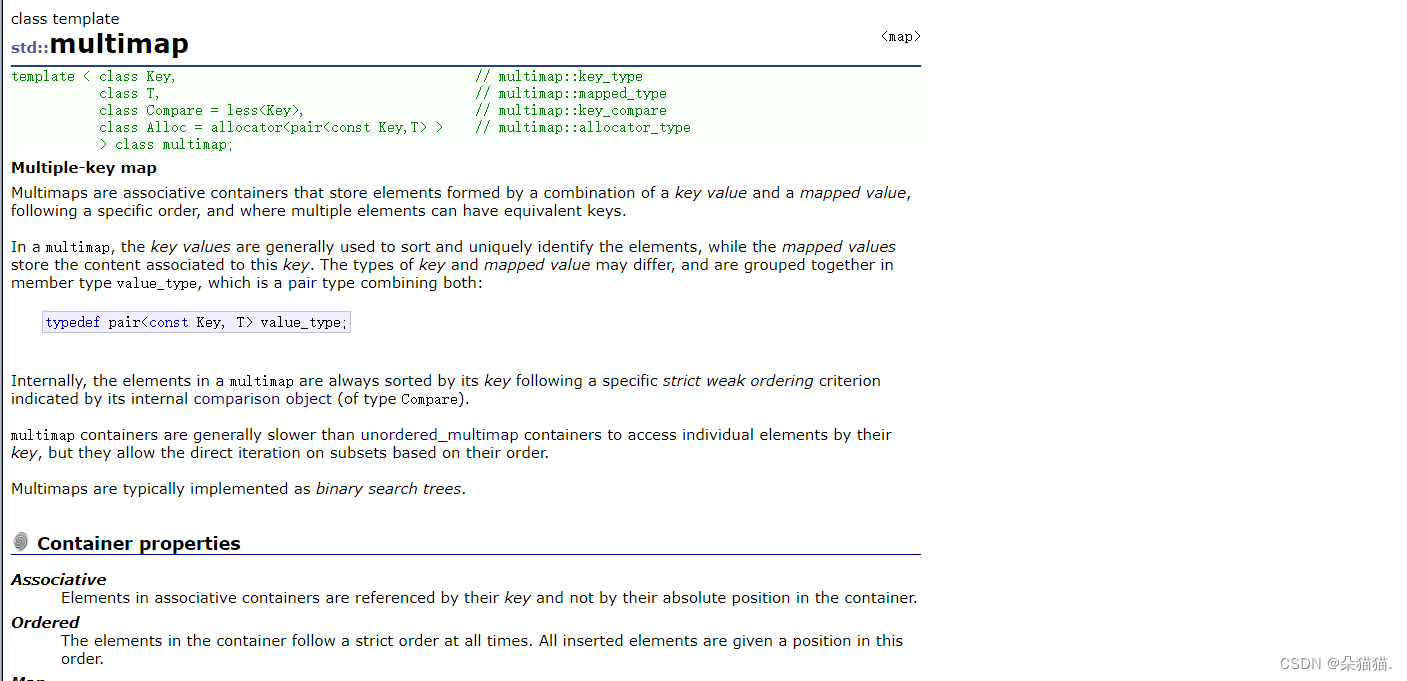
multimap与multiset一样,都是支持键值冗余,也可以理解为仅仅排序不去重,与map不同的是,由于multimap的键值不再是一一对应的关系了,所以multimap没有了[]运算符重载。下面我们演示一下:
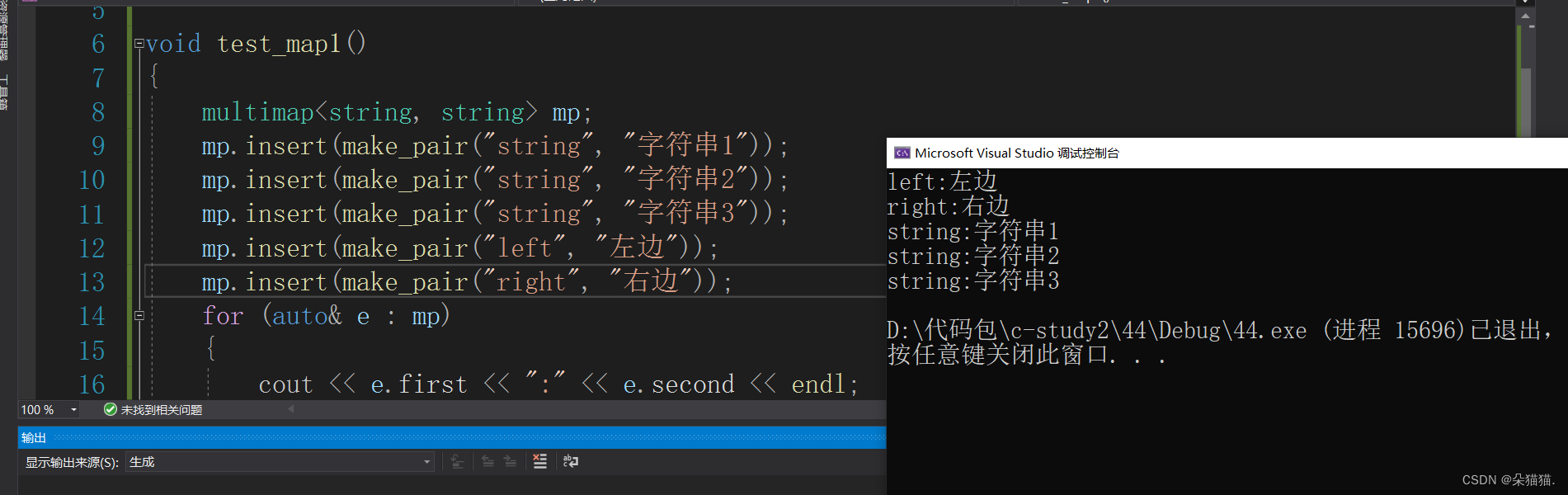
void test_map1()
{
multimap<string, string> mp;
mp.insert(make_pair("string", "字符串1"));
mp.insert(make_pair("string", "字符串2"));
mp.insert(make_pair("string", "字符串3"));
mp.insert(make_pair("left", "左边"));
mp.insert(make_pair("right", "右边"));
for (auto& e : mp)
{
cout << e.first << ":" << e.second << endl;
}
}
当然multimap虽然没有了[]运算符,但是count还是比较有用的:
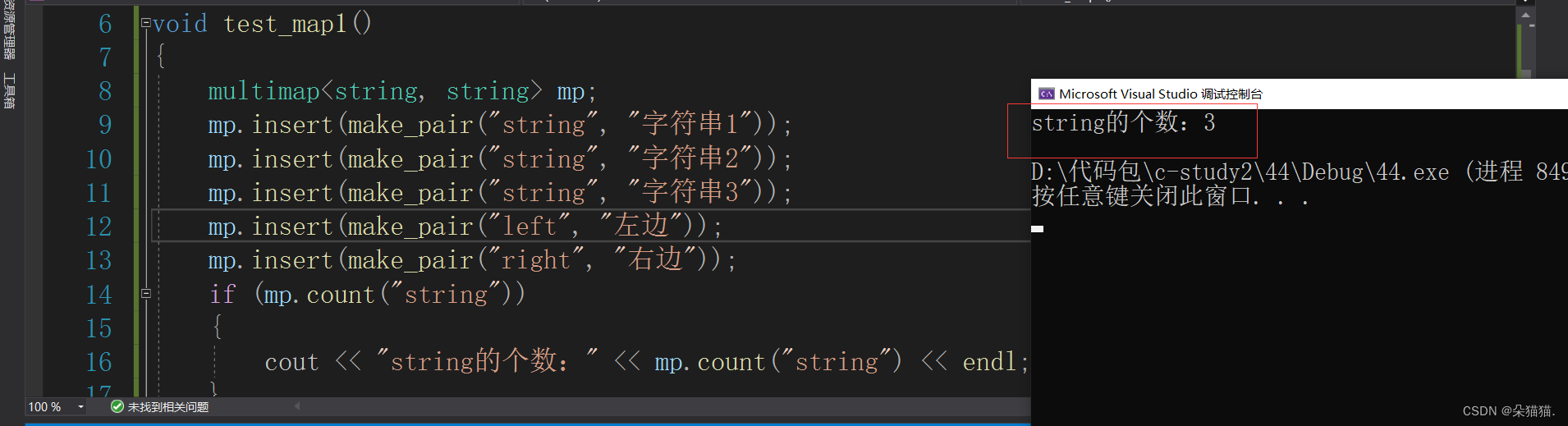
void test_map1()
{
multimap<string, string> mp;
mp.insert(make_pair("string", "字符串1"));
mp.insert(make_pair("string", "字符串2"));
mp.insert(make_pair("string", "字符串3"));
mp.insert(make_pair("left", "左边"));
mp.insert(make_pair("right", "右边"));
if (mp.count("string"))
{
cout << "string的个数:" << mp.count("string") << endl;
}
}
在multimap和multiset中count都可以计算出某个key的个数,以上就是map和set的基本用法以及一些重要功能的讲解,下面我们讲一道题练习一下map和set。
三.题目练习
力扣:前K个高频单词
力扣链接:力扣
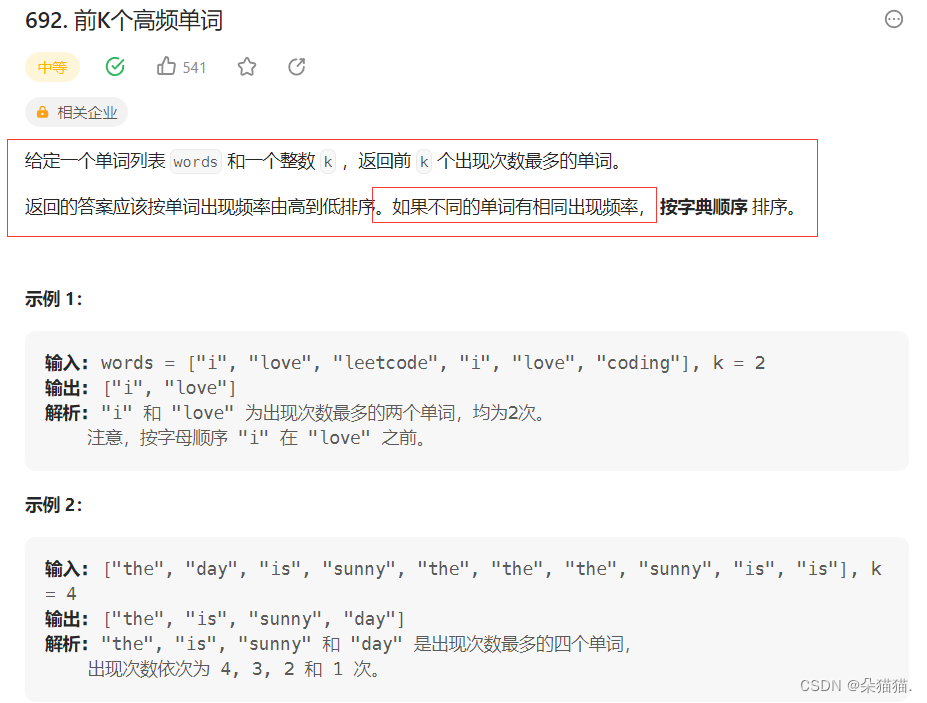
看到这道题大家应该首先想到的就是map了吧,毕竟题目已经很明显的说了KV键值对,下面我们说一下思路:首先我们用mp的[]功能统计出每个单词出现的次数以及对应的每个单词,然后我们将前K个这样的单词放入向量中,然后打印即可:
class Solution {
public:
struct compare
{
bool operator()(const pair<string,int>& k1,const pair<string,int>& k2)
{
return k1.second>k2.second;
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> mp;
for (auto& e:words)
{
mp[e]++;
}
vector<pair<string,int>> v(mp.begin(),mp.end());
sort(v.begin(),v.end(),compare());
vector<string> result;
for (int i = 0;i<k;i++)
{
result.push_back(v[i].first);
}
return result;
}
};首先我们用一个map来计算单词以及单词的次数,然后用一个vector来保存这些键值对(vector的类型一定是pair),然后我们用sort函数排序vector,由于pair默认的排序方式是以K值进行排序的,所以我们必须写一个仿函数来用键值对中的value值比较,比较完成后我们用另一个vector来接收前K个字符串,最后我们只需要返回string即可所以是v[i].first。但是如果我们发现没有通过,如下图:
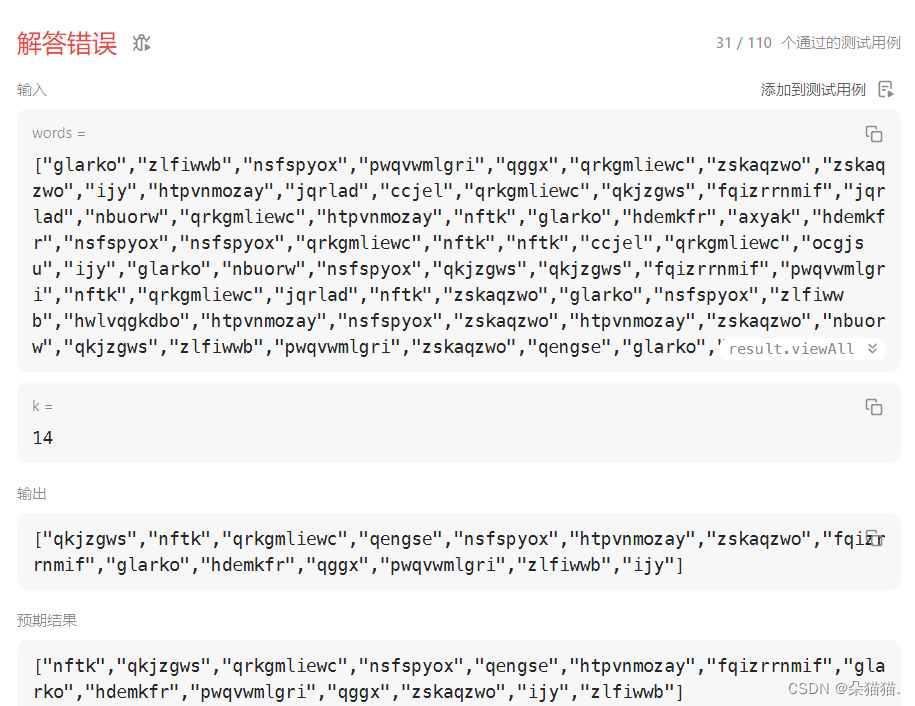
发现错误的原因是单词的顺序不对,当出现相同次数的单词需要用字典序来排序,所以这个时候我们就想到了排序的稳定性,如果一个排序稳定的话相同的值的相对顺序是不变的,本题给的测试列表本来也是按照字典序排好的,所以我们直接换一个稳定排序就解决了,在算法中有一个稳定排序:
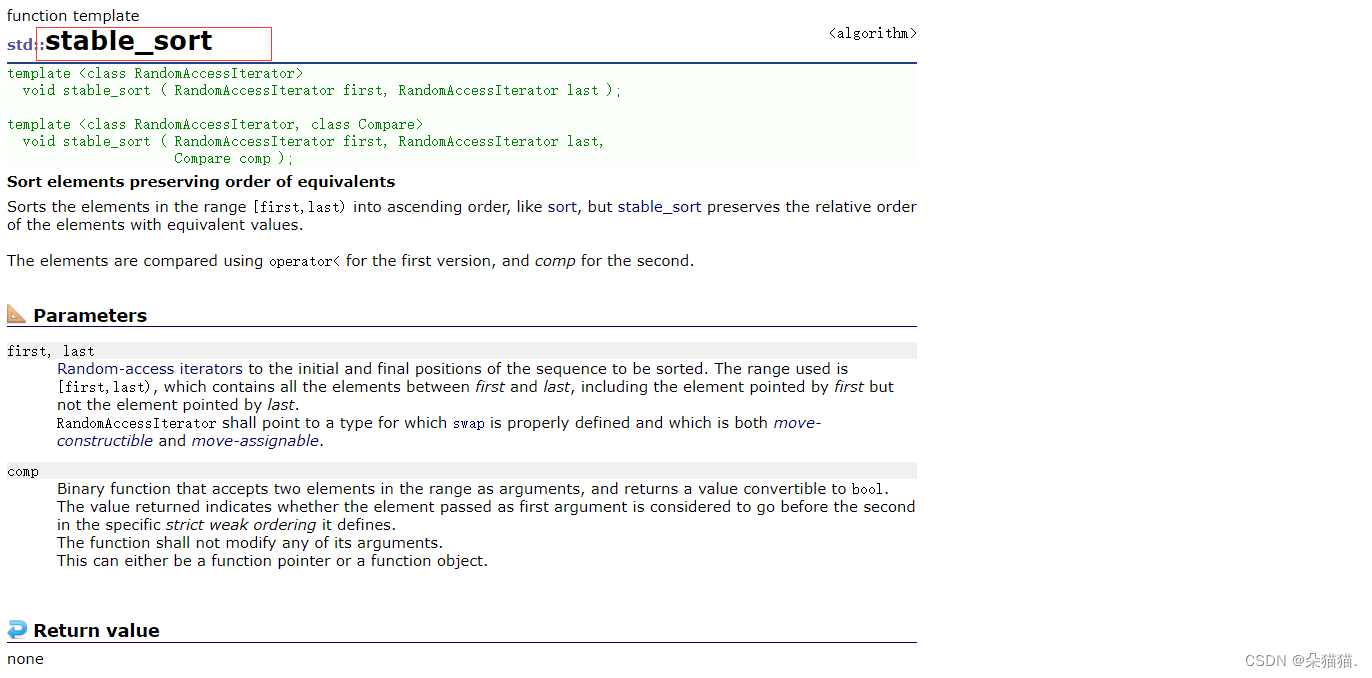
下面我们就换上这个稳定排序:
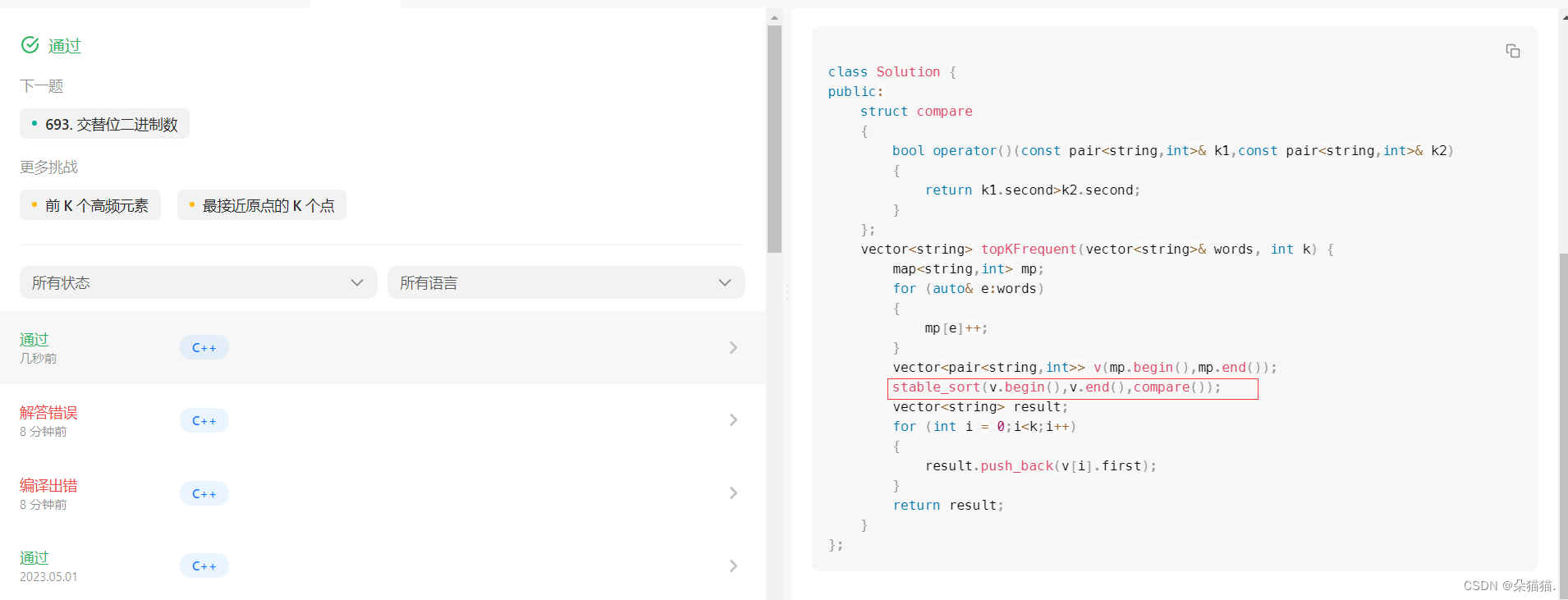
这样我们就通过了,那么如果我们还有其他办法解决刚刚的顺序问题吗?答案是当然有,要知道我们写仿函数的目的就是为了控制比较方式:
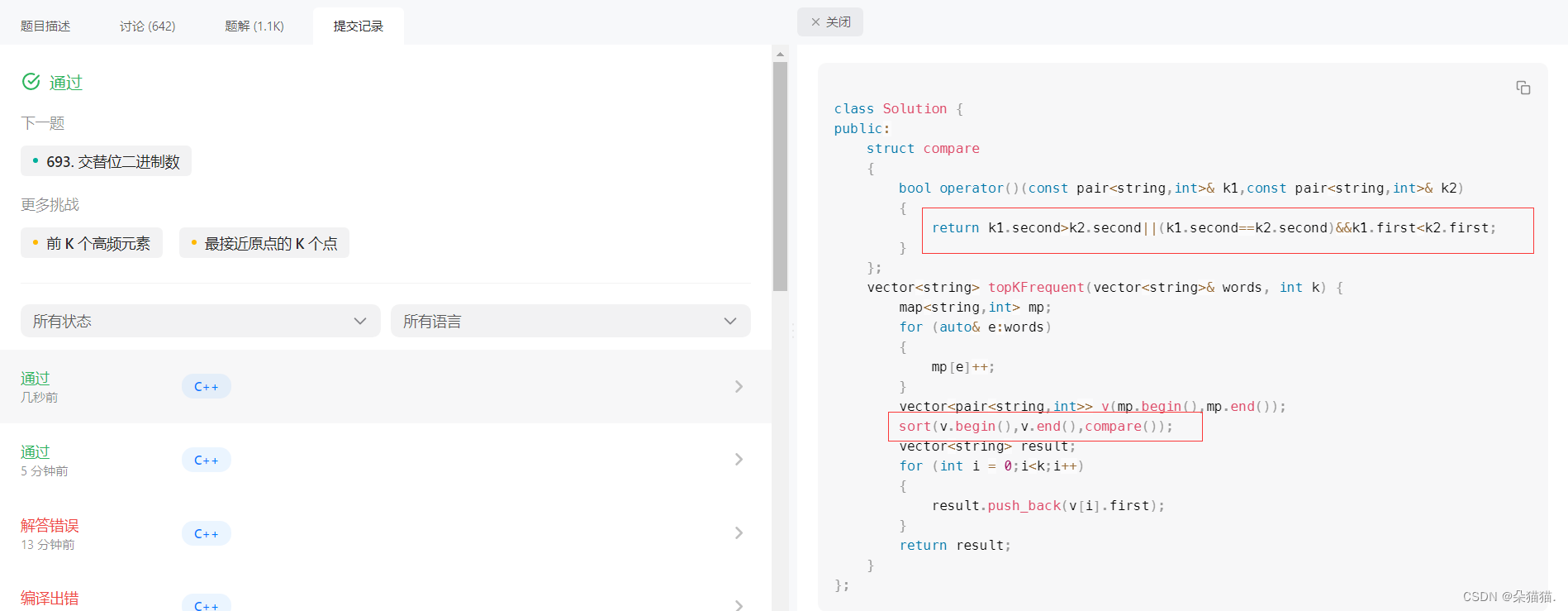
当然我们也可以用我们刚刚学的的set来进行比较,因为我们的set和map也是支持控制比较方式的:
class Solution {
public:
struct compare
{
bool operator()(const pair<string,int>& k1,const pair<string,int>& k2) const
{
return k1.second>k2.second||(k1.second==k2.second)&&k1.first<k2.first;
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> mp;
for (auto& e:words)
{
mp[e]++;
}
set<pair<string,int>,compare> st(mp.begin(),mp.end());
vector<string> v;
auto it = st.begin();
while (k--)
{
v.push_back(it->first);
++it;
}
return v;
}
};在这里大家要注意:
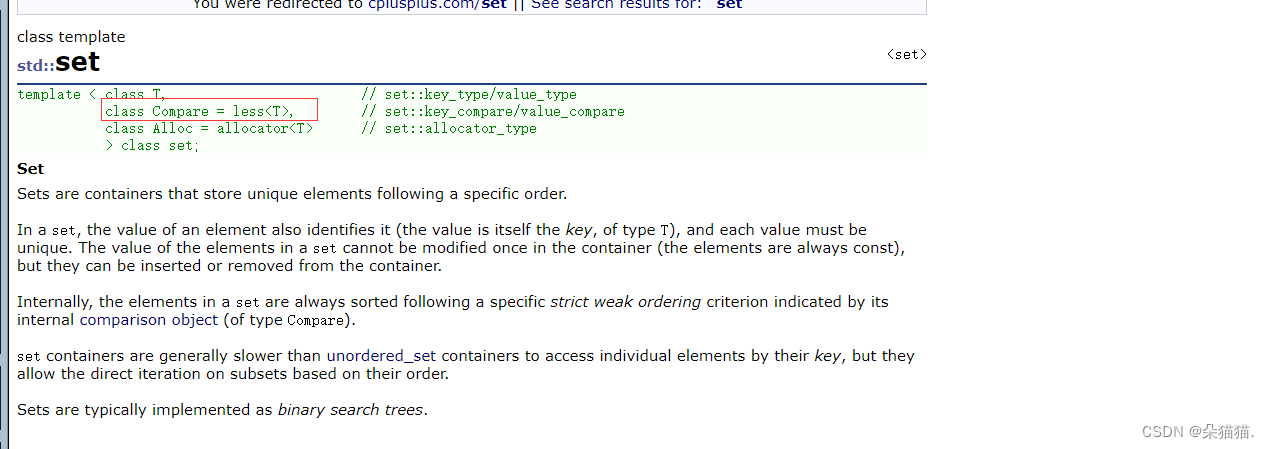
set中对于仿函数用的是模板,模板我们必须传类型所以我们写set的时候写的compare,像sort就不一样了:

我们可以看到sort中传的是仿函数对象,所以我们使用的时候用了匿名对象compare().当然上面的代码中我们写仿函数一定要在后面加上const,因为有些测试用例会有const对象,如果没写const会编译报错。
总结
学数据结构就如同我们打怪升级一般,从一开始的单链表到二叉树,每一次的难度都是层层递进的,到了map这边下一篇我们要讲的AVL树难度要比二叉树搜索树难了不止一点,但是只要大家有着面对困难打败困难的心就一定可以成为屠龙勇士~






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结