您现在的位置是:首页 >其他 >十三周内容笔记网站首页其他
十三周内容笔记
十三周内容笔记
day37
01-selenium相关配置
封装到一起用的时候调用就可以了,很方便。
def self_options():
op = webdriver.ChromeOptions()
# 1. 设置selenium不自动关闭浏览器
op.add_experimental_option("detach", True)
# 2. 不加载网页图片,提升网页加载速度
op.add_argument('blink-settings=imagesEnabled=false')
# 3. 避免终端下执行代码报错
op.add_experimental_option("excludeSwitches", ['enable-automation', 'enable-logging'])
# 4. 为selenium设置请求头UA,selenium调用的浏览器自带UA,但是因为存在UA反爬,所以可以选择性是否添加
UA = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
op.add_argument(f"--user-agent={UA}")
# 5. 设置代理IP
# proxy_ip = '127.0.0.1:8000'
# op.add_argument(f'--proxy-server=http://{proxy_ip}')
# 6. 加载拓展插件
op.add_extension('./FeHelper.crx')
# 7. 加载用户缓存,可以记录使用记录和cookie,如果不指定缓存路径,会自动创建临时文件夹。
# user_dir = r'./browser_cache'
# op.add_argument(f"--user-data-dir={user_dir}")
# 8. 无头浏览器:提升网页访问速度,但是牺牲的是增加更多的反爬风险,如果涉及到与网页的交互,有些网站就不能使用无头模式。
op.add_argument('--headless')
return op
02-selenium窗口尺寸对爬虫的影响
如果窗口过小,会导致selenium无法实现下一步的操作,页面上不显示,自然就无法找到对应的位置进行交互,会返回element click intercepted
element click intercepted:有些网站有检测机制,页面元素未显示在用户视野中(网页显示区域)时,元素不允许进行交互。
browser.maximize_window():窗口最大化
03-爬虫蜜罐
蜜罐:形容抵不住诱惑,之前在学习网安的时候了解到过。爬虫蜜罐即爬虫陷阱。
一、概述
一个接入了互联网的网站,只要能和外部产生通信,就有可能被黑客攻击。所以有些网站设置了一些陷阱,来引诱攻击者从而达到自身不被攻击的目的。
二、蜜罐分类
电子邮件蜜罐:邮箱管理者会在网络中故意放出一些邮箱账号,这些账号只能被扫描器发现,正常人发现不了,所以如果这些账号接收到邮件,就可以将发件地址标记为恶意账号。
数据库蜜罐:用来监控攻击者对数据库的攻击命令或发现利用sql注入攻击,运营人员就可以将访问数据区的ip地址拉黑。
爬虫蜜罐:例如:在网页源码中注释掉一些链接,这些链接普通用户永远不会看到,但是写爬虫的人能看到,爬虫能访问到,如果有爬虫访问了这些注释掉的陷阱链接,立刻能够检测到是哪个ip地址访问了,直接将此ip拉黑。
三、蜜罐的优缺点
优点:节省资源、能够轻易捕捉到危险、准确率高。
缺点:准确率高不等于100%,有误封的缺点。
day38
scrapy爬虫框架
一、scrapy爬虫框架介绍
scrapy是基于python开发的爬虫框架,用于从网站中抓取数据。python爬虫领域中scrapy是最强悍的框架。该框架提供了非常多的爬虫相关的基础组件,建构清晰,可拓展性强。
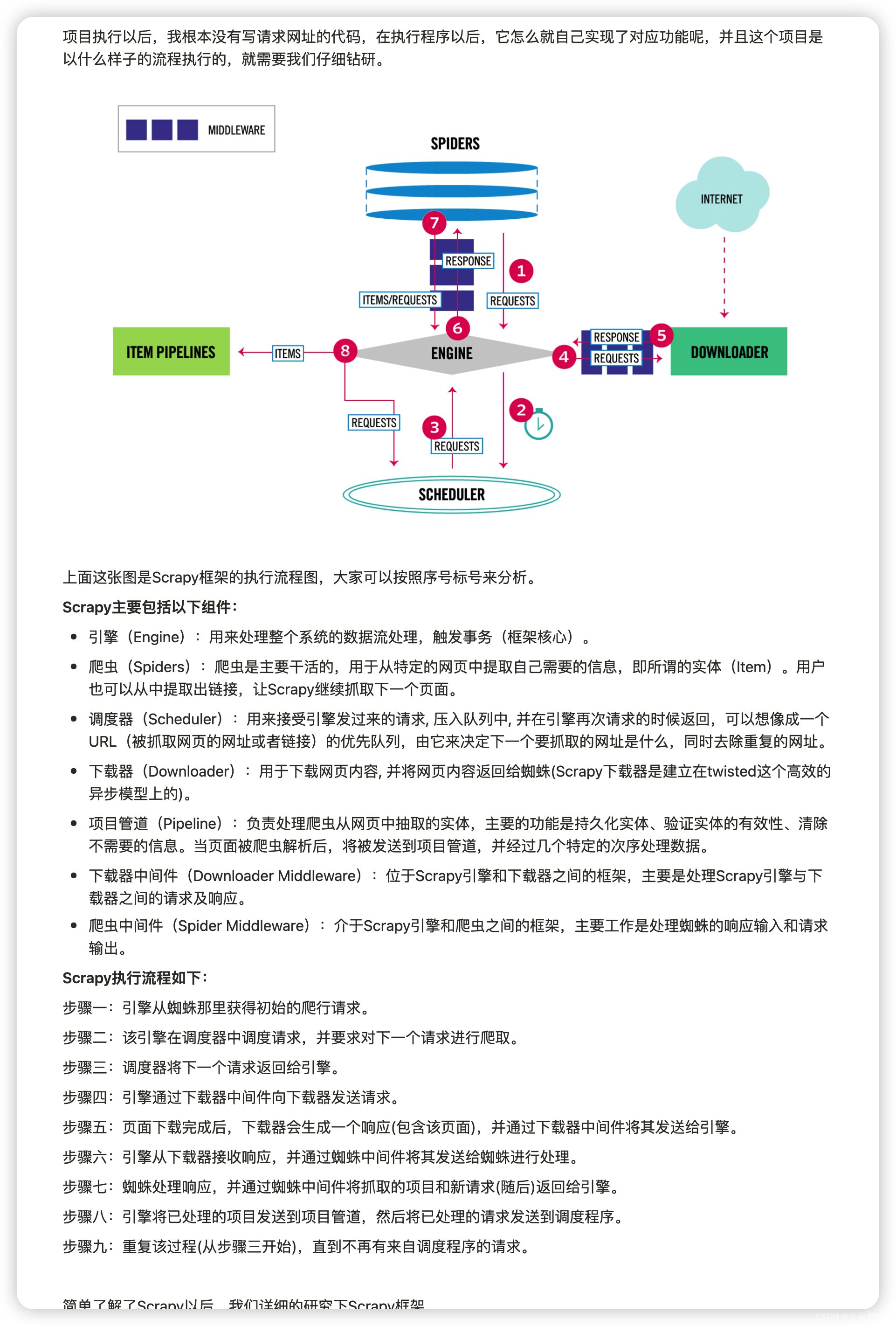
二、scrapy爬虫框架出现的条件
每次写爬虫都需要写一遍重复性的内容,scrapy作者就根据重复性的内容封装成通用的代码,通过多版本迭代,住家形成规模庞大的框架。
三、安装
pip install scrapy
四、创建scrapy爬虫项目
命令:scrapy startproject 项目名
创建中国新闻网爬虫项目:scrapy startproject ChinaNews
创建完是这样式儿的:
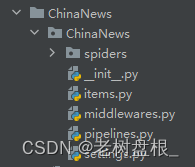
后面会对上面的文件展开操作
五、开始操作
先使用cd命令切换进项目,通过命令初始化某个网站的爬虫文件
scrapy genspider 文件名(运行scrapy项目时的名字)被爬取网站的链接
scrapy genspider NewsSpider https://www.chinanews.com.cn/
六、scrapy爬虫项目的运行
scrapy crawl 爬虫名字
scrapy crawl NewsSpider
七、settings.py(很重要)
这是scrapy的配置文件,需要修改成不遵循robots协议:ROBOTSTXT_OBEY = False

八、多线程(默认16线程):

day39
对中国新闻网即时新闻精选进行实操
一、在NewsSpider.py文件内写爬虫代码
import scrapy
from ..items import ChinanewsItem
class NewsspiderSpider(scrapy.Spider):
name = "NewsSpider"
allowed_domains = ["www.chinanews.com.cn"]
start_urls = ["https://www.chinanews.com.cn/"]
def parse(self, response):
# response:网页的响应结果
# 查看网页源代码
# print(response.text)
# css方法:scrapy提供了css方法能够使用css选择器定位到元素
# 如果要取标签属性,需要在css方法的css选择器中这样写 --> 标签::attr(属性名)
# get():获取到css选择器指定的内容
link = response.css('body > div:nth-child(9) > div.news-right > div.top-jsxw > div.jsxw-title.lmtitle > a::attr(href)').get()
# print(link)
# 将链接补全
new_link = self.start_urls[0] + link[1:]
# print(new_link)
# 构建10页链接
for page in range(1, 11):
page_link = new_link.replace('1', str(page))
# print(page_link)
# scrapy.Request():scrapy中负责请求链接的方法
# callback:回调函数,可以提前调用一个不存在的函数、变量等,然后紧接着再去创建。
yield scrapy.Request(url=page_link, callback=self.NewsInfo)
# Xpath写法
def NewsInfo(self, response):
# 实例化实体类
newsItem = ChinanewsItem()
# 此时response根节点时html
li_list = response.xpath('/html/body/div[4]/div[1]/div[2]/ul/li')
for i in li_list:
if i.xpath('./@class').get() != 'nocontent':
news_type = i.xpath('./div[1]/a/text()').get()
news_title = i.xpath('./div[2]/a/text()').get()
news_link = 'https://www.chinanews.com.cn' + i.xpath('./div[2]/a/@href').get()
news_time = i.xpath('./div[3]/text()').get()
# print(news_type, news_title, news_link, news_time)
newsItem['NewsType'] = news_type
newsItem['NewsTitle'] = news_title
newsItem['NewsLink'] = news_link
newsItem['NewsTime'] = news_time
yield newsItem
还有CSS写法,不过我不太喜欢CSS,看起来代码太臃肿。
# CSS选择器写法
def NewsInfo(self, response):
# 从响应结果中查看访问的是哪个链接
# print(response.url)
# 获取当前页面的所有新闻的li标签
li_list = response.css('body > div.w1280.mt20 > div.content-left > div.content_list > ul > li')
# print(li_list)
for i in li_list:
# 如果要取标签内容,需要在css方法的css选择器中这样写 --> 标签::text
news_type = i.css('li > div.dd_lm > a::text').get()
# 如果li的class属性为nocontent,即值为空,则去掉此li标签
if news_type != None:
news_title = i.css('li > div.dd_bt > a::text').get()
news_link = 'https://www.chinanews.com.cn' + i.css('li > div.dd_bt > a::attr(href)').get()
news_time = i.css('li > div.dd_time::text').get()
print(news_type, news_title, news_link, news_time)
newsItem['NewsType'] = news_type
newsItem['NewsTitle'] = news_title
newsItem['NewsLink'] = news_link
newsItem['NewsTime'] = news_time
yield newsItem
二、在items.py文件内实体化
import scrapy
class ChinanewsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 此处写什么代码取决于你提取了哪些信息
NewsType = scrapy.Field()
NewsTitle = scrapy.Field()
NewsLink = scrapy.Field()
NewsTime = scrapy.Field()
# Field()是获取scrapy提供的Item类(实体类)中的信息
# 爬虫主要目标就是从非结构化数据源中提取出结构化的数据
# 结构化数据一般是一个字段对应一个或一类数据,这种情况下字典是最好用的
# 但是字典很容易将键的名字写错,此时scrapy的Item类起作用了,Item类本身就是处理结构化数据的
# 将字段名化为变量名使用,就不会出错了。
三、数据存储,在piplines.py内操作
import csv
# scrapy 的数据存储有两种形式
# 方式一:直接使用命令存储文件
# scrapy crawl 爬虫名字 -o 文件名.拓展名
# 或者 scrapy crawl 爬虫名字 --output 文件名.拓展名
# 使用命令的形式存储数据,拓展名支持8种类型的文件
# json、jsonlines、jsonl、jl、csv、xml、marshal、pickel(python 高性能文件)
# scrapy crawl NewsSpider -o data.csv
# 方式二:手写代码实现数据的存储
# 注意:管道中的代码想要执行,必须告知scrapy,我添加了什么代码
class ChinanewsPipeline:
def process_item(self, item, spider):
return item
class ChinanewsToCsvPipline:
def open_spider(self, spider):
"""当爬虫开始执行时,open_spider被执行"""
self.file = open('数据.csv', 'w', encoding='utf-8', newline='')
csv.writer(self.file).writerow(['新闻类型', '新闻标题', '新闻链接', '发布时间'])
def process_item(self, item, spider):
"""爬虫执行过程中执行的代码"""
data = [item['NewsType'], item['NewsTitle'], item['NewsLink'], item['NewsTime']]
csv.writer(self.file).writerow(data)
return item
def close_spider(self, spider):
"""当爬虫结束执行时,close_spider被执行"""
self.file.close()
管道中的代码想要执行,必须告知scrapy,我添加了什么代码,在settings.py中操作
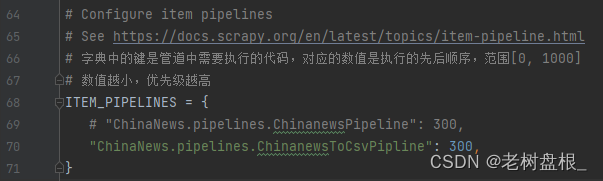
# 字典中的键是管道中需要执行的代码,对应的数值是执行的先后顺序,范围[0, 1000]
# 数值越小,优先级越高
ITEM_PIPELINES = {
# "ChinaNews.pipelines.ChinanewsPipeline": 300,
"ChinaNews.pipelines.ChinanewsToCsvPipline": 300,
}
四、UA反反爬的设置
在middlewares.py文件中操作,添加如下类
class ChinanewsUserAgentDownloaderMiddleware:
def __init__(self):
file = open('UserAgent.txt', 'r')
self.UAList = ast.literal_eval(file.read())
@classmethod
def from_crawler(cls, crawler):
"""在爬虫开始或结束时进行一些操作的函数"""
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
"""下载器发送请求前针对请求的处理"""
# 将一个UA放入到请求的headers中
request.headers['User-Agent'] = random.choice(self.UAList)
return None
def process_response(self, request, response, spider):
"""下载器请求完页面,和引擎通信时对响应结果做的处理"""
return response
def process_exception(self, request, exception, spider):
"""如果出现异常,怎么处理"""
pass
def spider_opened(self, spider):
"""日志信息处理"""
spider.logger.info("Spider opened: %s" % spider.name)
同样需要告诉scrapy我添加了什么代码
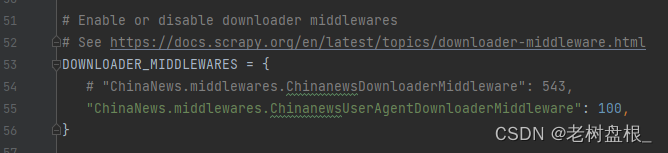
DOWNLOADER_MIDDLEWARES = {
# "ChinaNews.middlewares.ChinanewsDownloaderMiddleware": 543,
"ChinaNews.middlewares.ChinanewsUserAgentDownloaderMiddleware": 100,
}
这玩意儿是真有点抽象,要完全理解需要时间的,不过我觉得现在刚刚起步,不着急理解的,先依葫芦画瓢当个工具使用就就可以,毕竟用工具的时候不会有人会去完全弄清楚原理吧哈哈。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结