您现在的位置是:首页 >其他 >Shell脚本文本三剑客之awk编辑器(人类从不掩饰探索星空的愿望)网站首页其他
Shell脚本文本三剑客之awk编辑器(人类从不掩饰探索星空的愿望)
文章目录
一、awk简介
awk是linux的一个强大的命令,具备强大的文本格式化能力,比如对一堆看起来没有什么规律的日志文件,文本文件等,通过awk命令格式化输出为专业的可以做为应用级数据分析的样式。
二、awk工作原理
逐行读取文本,默认以空格或制表符为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个“字段”,然后再进行处理。awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。
在使用awk命令的过程中,可以使用逻辑操作符"&&“表示"与”、“||“表示"或”、”!“表示"非”,还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方
三、awk命令格式
awk [选项] ‘模式或条件 {操作表达式}’ 文件名…
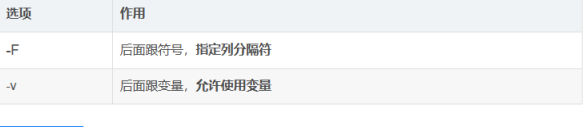
awk常用选项
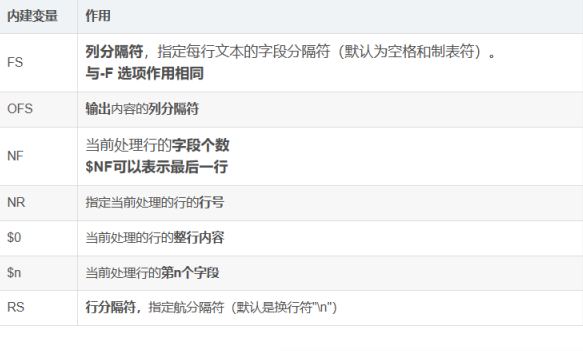
awk常见内建变量
四、awk命令的使用
1.print操作按行输出文本
//1.输出所有内容
[root@localhost1 ~]#awk '{print}' numfile
one
two
three
four
five
six
seven
eight
nine
ten
[root@localhost1 ~]#awk '{print $0}' numfile #$0代表匹配到的整行
one
two
three
four
five
six
seven
eight
nine
ten
//2.指定行,输出1~3行内容
[root@localhost1 ~]#awk 'NR==1,NR==3 {print}' numfile
one
two
three
[root@localhost1 ~]#awk '(NR>=1)&&(NR<=3) {print}' numfile
one
two
three
//3.指定的几行,输出第1、3行
[root@localhost1 ~]#awk 'NR==1||NR==3 {print}' numfile
one
three
//4.输出奇偶行
[root@localhost1 ~]#awk '(NR%2)==0 {print}' numfile
two
four
six
eight
ten
[root@localhost1 ~]#awk '(NR%2)==1 {print}' numfile
one
three
five
seven
nine
//5.输出行号
[root@localhost1 ~]#awk '{print NR,$0}' file1
1 one two three
2 four five six
3 seven eight nine
4 ten eleven twelve
//6.指定第1行包含o的行。输出行号和内容
[root@localhost1 ~]#awk '$1~"o" {print NR,$0}' file1
1 one two three
2 four five six
//7.指定输出包含指定字符串的行
[root@localhost1 ~]#awk '/root/ {print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
//8.指定输出包含指定正则表达式的行
[root@localhost1 ~]#awk '/^root.*bash$/ {print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
2.print操作按字段截取输出文本
//1.指定字段分隔符":",输出每行1,3字段
[root@localhost1 ~]#awk -F ':' '{print $1,$3}' /etc/passwd
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 8
...
avahi 70
postfix 89
tcpdump 72
hx 1000
apache 48
zhangsan 1001
lisi 1002
zhaoliu 1003
wangwu 1004
qianqi 1005
zhuba 1006
//2.在第1条基础上,限定行范围,第3个字段值小于1000的行,输出每行1,3字段
[root@localhost1 ~]#awk -F ':' '$3>1000 {print $1,$3}' /etc/passwd
nfsnobody 65534
zhangsan 1001
lisi 1002
zhaoliu 1003
wangwu 1004
qianqi 1005
zhuba 1006
//3.指定最后一个字段包含sbin的行,输出第1和最后一个字段
[root@localhost1 ~]#awk -F ':' '$NF~"sbin" {print $1,$NF}' /etc/passwd
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
operator /sbin/nologin
games /sbin/nologin
...
rpcuser /sbin/nologin
nfsnobody /sbin/nologin
gnome-initial-setup /sbin/nologin
sshd /sbin/nologin
avahi /sbin/nologin
postfix /sbin/nologin
tcpdump /sbin/nologin
apache /sbin/nologin
named /sbin/nologin
dhcpd /sbin/nologin
//4.输出最后一个字段既不是/sbin/nologin也不是/bin/bash的行
[root@localhost1 ~]#awk -F ':' '($NF!="/sbin/nologin")&&($NF!="/bin/bash") {print $1,$NF}' /etc/passwd
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
3.使用BEGIN和END指定操作
awk [选项] ‘BEGIN {表达式}; [条件] {操作表达式}; END {表达式}’ 文件名…
- BEGIN {操作1} awk在读取文件之前执行的操作
- [条件] {操作2} awk 逐行读取文件时执行的操作
- END {操作3} awk在处理完文件所有行之后执行的操作
//1.输出结尾为nologin的行,并为每行计数显示行号,最后输出总行数
[root@localhost1 ~]#awk 'BEGIN {a=0}; /nologin$/ {a++; print a,$0}; END {print " 共有"a"行"}' /etc/passwd
1 bin:x:1:1:bin:/bin:/sbin/nologin
2 daemon:x:2:2:daemon:/sbin:/sbin/nologin
3 adm:x:3:4:adm:/var/adm:/sbin/nologin
4 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
5 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
...
34 nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin
35 gnome-initial-setup:x:988:982::/run/gnome-initial-setup/:/sbin/nologin
36 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
37 avahi:x:70:70:Avahi mDNS/DNS-SD Stack:/var/run/avahi-daemon:/sbin/nologin
38 postfix:x:89:89::/var/spool/postfix:/sbin/nologin
39 tcpdump:x:72:72::/:/sbin/nologin
40 apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
41 named:x:25:25:Named:/var/named:/sbin/nologin
42 dhcpd:x:177:177:DHCP server:/:/sbin/nologin
共有42行
//1.输出以:分割的第1和3个字段
[root@localhost1 ~]#echo $PATH |awk 'BEGIN {FS=":"}; {print $1,$3}'
/usr/local/sbin /usr/sbin
//2.输出$PATH的每个文件
[root@localhost1 ~]#echo $PATH |awk 'BEGIN {RS=":"}; {print NR,$0} END {print "共有"NR"行"}'
1 /usr/local/sbin
2 /usr/local/bin
3 /usr/sbin
4 /usr/bin
5 /root/bin
共有5行
//3.输出ens33网卡的ip和mac地址
[root@localhost1 ~]#ifconfig ens33
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.116.10 netmask 255.255.255.0 broadcast 192.168.116.255
inet6 fe80::7791:1d06:d2da:af8e prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:3b:4b:c3 txqueuelen 1000 (Ethernet)
RX packets 19934 bytes 1547296 (1.4 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8225 bytes 867536 (847.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@localhost1 ~]#ifconfig ens33 |awk 'NR==2 {print $2}'
192.168.116.10
[root@localhost1 ~]#ifconfig ens33 |awk '/ether/ {print $2}'
00:0c:29:3b:4b:c3
//4.内存占用多少MB
[root@localhost1 ~]#free -m
total used free shared buff/cache available
Mem: 1819 563 849 14 406 1080
Swap: 8191 0 8191
[root@localhost1 ~]#free -m | awk 'NR==2 {print $3}'
563
[root@localhost1 ~]#free -m | awk '/Mem/ {print $3}'
563
//5.内存占用率
[root@localhost1 ~]#free -m
total used free shared buff/cache available
Mem: 1819 563 848 14 406 1080
Swap: 8191 0 8191
[root@localhost1 ~]#free -m | awk '/Mem/ {print ($4/$2*100)"%"}'
46.619%
[root@localhost1 ~]#free -m | awk '/Mem/ {print int($4/$2*100)"%"}'
46%
//6.CPU空闲率
[root@localhost1 ~]#top -b -n1 |awk -F "," '/Cpu/ {print $4}' |awk '{print $1"%"}'
98.5%
//7.计算开机时间
[root@localhost1 ~]#date -d "$(awk '{print $1}' /proc/uptime) second ago" +"%Y%m%d %H:%M:%S"
20220905 21:28:50
[root@localhost1 ~]#date -d "-$(awk '{print $1}' /proc/uptime) second" +"%Y%m%d %H:%M:%S"
20220907 08:32:41
5.使用操作getline
- 当getline左右无重定向符“<”或“|”时,awk首先读取到了第一行,就是1,然后getline,就得到了1下面的第二行,就是2,因为getline之后,awk会改变对应的NF,NR,FNR和$0等内部变量,所以此时的$0的值就不再是1,而是2了,然后将它打印出来。
- 当getline左右有重定向符“<”或“|”时,getline则作用于定向输入文件,由于该文件是刚打开,并没有被awk读入一行,只是getline读入,那么getline返回的是该文件的第一行,而不是隔行。
//1.利用getline输出奇偶行
[root@localhost1 ~]#seq 10 |awk '{getline;print $0}'
2
4
6
8
10
[root@localhost1 ~]#seq 10 |awk '{print $0;getline}'
1
3
5
7
9
//2.利用getline输出主机名
[root@localhost1 ~]#awk 'BEGIN {"hostname" |getline ;{print $0} }'
localhost1
//3.利用getline读取w命令显示的行数,统计出在线用户数(减去前2个无关行)
[root@localhost1 ~]#w
14:56:47 up 6:24, 1 user, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 192.168.116.1 14:17 7.00s 0.14s 0.02s w
[root@localhost1 ~]#w |awk 'NR>2 {print $0 | "wc -l"}'
1
6.使用操作OFS
//1.利用OFS输出第1和3个字段,并用:作为输出的分隔符
[root@localhost1 ~]#echo "A B C D" |awk '{OFS=":";print $1,$3}'
A:C
//2.利用OFS指定分割符输出整行内容时,需要使用$1=$1刷新整行内容
[root@localhost1 ~]#echo "A B C D" |awk '{OFS=":";$1=$1;print $0}'
A:B:C:D
7.配合数组使用
//1.输出指定数组值
[root@localhost1 ~]#awk 'BEGIN {a[0]=10;a[1]=20;print a[1]}'
20
[root@localhost1 ~]#awk 'BEGIN {a[0]=10;a[1]=20;print a[0]}'
10
//2.使用字符串作为数组索引,输出指定数组值
[root@localhost1 ~]#awk 'BEGIN {a["abc"]=10;a["xyz"]=20;print a["abc"]}'
10
//数组值也可以为字符串
[root@localhost1 ~]#awk 'BEGIN {a["abc"]="aa";a["xyz"]="xx";print a["abc"]}'
aa
//3.遍历数组
[root@localhost1 ~]#awk 'BEGIN {a[0]=10;a[1]=20;a[2]=30; for(i in a) {print i,a[i]}}' 0 10
1 20
2 30
利用数组做统计
awk 根据指定字段读取每行的字段内容,使用字段内容作为数组的索引,如果出现相同内容的行,则用这个行内容做的数组的值自增1;END{ for(i in arr) {print arr[i],i} awk 读取完所有行内容后,使用for循环遍历这个数组的下标,打印每个下标出现的次数和下标的值。
awk ‘{arr{$n}++}; END{ for(i in arr) {print arr[i],i}’ 文件名…
//1.利用数组统计,输出文件中各行出现的次数并排序
[root@localhost1 ~]#cat test.txt | awk '{arr[$1]++}; END{for(i in arr) {print arr[i],i}}' test.txt |sort -rn
4 aaa
3 bbb
1 ccc
//2.利用数组统计,过滤输入密码超过3次的主机ip
[root@localhost1 /]#awk '/Failed password/ {a[$13]++};END{for(i in arr) {print arr[i],i}}' /var/log/secure |awk '$1>3 {print $2}'
192.168.116.1
192.168.116.10
利用数组做去重
awk ‘1’ 就是 awk ‘1{print}’ ,允许打印读入的行内容,例:echo 123 | awk ‘1’
awk ‘0’ 就是 awk ‘0{print}’ ,不允许打印读入的行内容,例:echo 123 | awk ‘0’
var++ 的形式:先读取 var 变量值,再对 var 值 +1
awk 处理第一行时:先读取 a[$1] 值再自增,a[$1] 即 a[1] 值为空(即0),即为 awk ‘!0’,即为 awk ‘1’,即为 awk’1{print}’
awk 处理第二行时:先读取 a[$1] 值再自增,a[$1] 即 a[1] 值为 1,即为 awk ‘!1’,即为 awk ‘0’,即为 awk ‘0{print}’
//使用!arr[$1]++实现禁止重复读取到的内容输出
[root@localhost1 ~]#arr=(1 2 3 4 3 4 5 3 5 2 3 1)
[root@localhost1 ~]#echo ${arr[@]} |awk 'BEGIN{RS=" "}; !arr[$1]++'
1
2
3
4
5






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结