您现在的位置是:首页 >技术杂谈 >CGAN(条件GAN)网站首页技术杂谈
CGAN(条件GAN)
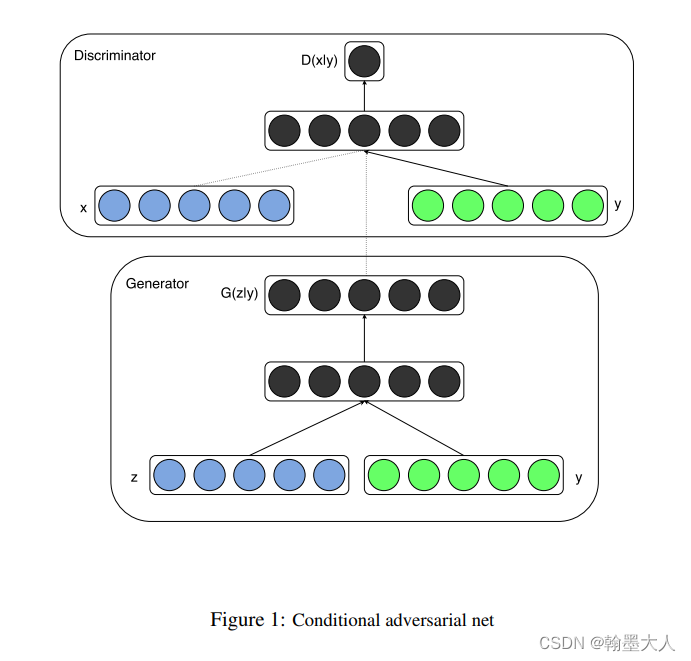
相比于GAN,CGAN给生成器和辨别器都添加了一个辅助信息,假设为y,y可以是标签类别或者其他模态的信息。
目标函数相比于GAN在输入端的x和z变为在y条件下生成的x和z。

模型框架可以表示为:
代码:
import argparse
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '2'
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--n_classes", type=int, default=10, help="number of classes for dataset")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)#(1,32,32)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.label_emb = nn.Embedding(opt.n_classes, opt.n_classes)
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim + opt.n_classes, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, noise, labels):
# Concatenate label embedding and image to produce input
gen_input = torch.cat((self.label_emb(labels), noise), -1)#(64,110)
img = self.model(gen_input)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.label_embedding = nn.Embedding(opt.n_classes, opt.n_classes)#10个查询向量,每个映射为10维
self.model = nn.Sequential(
nn.Linear(opt.n_classes + int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1),
)
def forward(self, img, labels):
# Concatenate label embedding and image to produce input
d_in = torch.cat((img.view(img.size(0), -1), self.label_embedding(labels)), -1)#(64,1034)
validity = self.model(d_in)#(64,1)
return validity
# Loss functions
adversarial_loss = torch.nn.MSELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Configure data loader
# os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"/home/Projects/ZQB/a/dataset",
train=True,
download=False,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),#32×32
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor
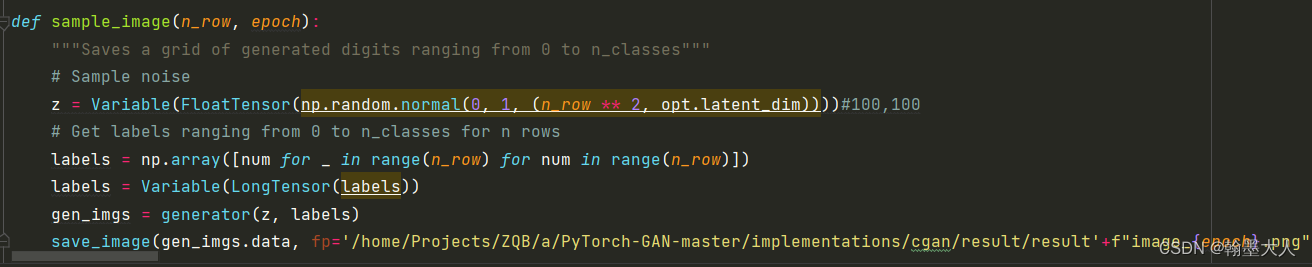
def sample_image(n_row, epoch):
"""Saves a grid of generated digits ranging from 0 to n_classes"""
# Sample noise
z = Variable(FloatTensor(np.random.normal(0, 1, (n_row ** 2, opt.latent_dim))))#100,100
# Get labels ranging from 0 to n_classes for n rows
labels = np.array([num for _ in range(n_row) for num in range(n_row)])
labels = Variable(LongTensor(labels))
gen_imgs = generator(z, labels)
save_image(gen_imgs.data, fp='/home/Projects/ZQB/a/PyTorch-GAN-master/implementations/cgan/result/result'+f"image_{epoch}.png", nrow=n_row, normalize=True)
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):#(64,1,32,32)/(64)
batch_size = imgs.shape[0]#64
# Adversarial ground truths
valid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)#(64,1)
fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)#(64,1)
# Configure input
real_imgs = Variable(imgs.type(FloatTensor))
labels = Variable(labels.type(LongTensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise and labels as generator input
z = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))#(64,100)
gen_labels = Variable(LongTensor(np.random.randint(0, opt.n_classes, batch_size)))#64
# Generate a batch of images
gen_imgs = generator(z, gen_labels)#(64,1,32,32)
# Loss measures generator's ability to fool the discriminator
validity = discriminator(gen_imgs, gen_labels)#(64,1)
g_loss = adversarial_loss(validity, valid)#0.9160
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
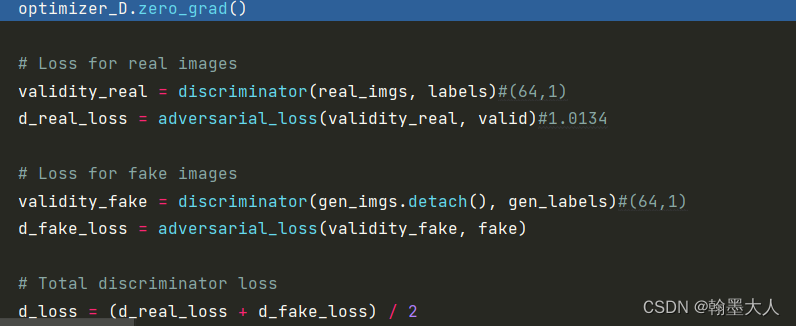
optimizer_D.zero_grad()
# Loss for real images
validity_real = discriminator(real_imgs, labels)#(64,1)
d_real_loss = adversarial_loss(validity_real, valid)#1.0134
# Loss for fake images
validity_fake = discriminator(gen_imgs.detach(), gen_labels)#(64,1)
d_fake_loss = adversarial_loss(validity_fake, fake)
# Total discriminator loss
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
# if batches_done % opt.sample_interval == 0:
sample_image(n_row=10, epoch=epoch)
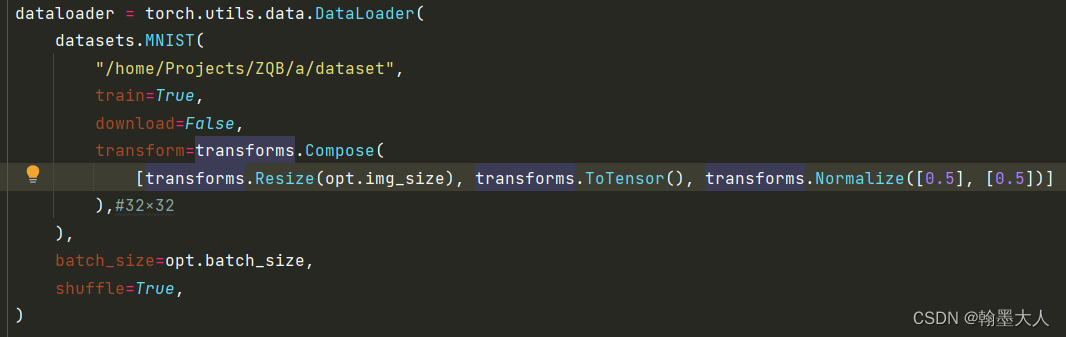
1:首先从数据加载开始看:
指定数据集读取位置,如果没有提前下载,将download改为True。接着对数据集图片进行变换,首先resize到32×32大小,接着转换为tensor后归一化。最后通过Dataloader进行加载,batchsize为64.
2:定义两个优化器。两个配置一样。
3:用1填充validation,用0填充fake,判别器对于真实的image期望输出1,对于噪声生成的image期望输出0.
4:接着生成噪声和附加条件y=gen_labels。其中gen_labels为0到10的整数,batchsize为64,即生成64个。

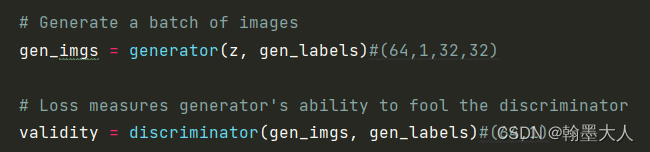
5:将噪声和标签输入到生成器中,产生的图像再输入到判别器中。
查看生成器的构成:
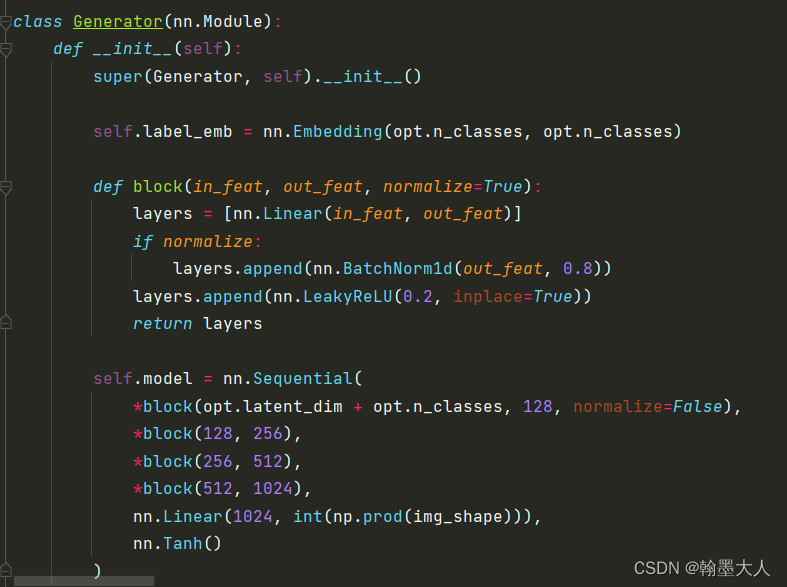
将噪声和经过编码后的标签concat之后输入到生成器中,label=64.

第一个参数限制类别只能在0-9之间,第二个参数将每一个标签数字映射到10维空间,即经过编码之后标签的大小为(64,10)。噪声的大小为(64,100),则concat之后大小为(64,110)。最后经过5个线性层,最后一个输入为1024,输出为image_size的乘积。即将每一个batch的每一个像素输出一个值。最后经过resize到原图大小。

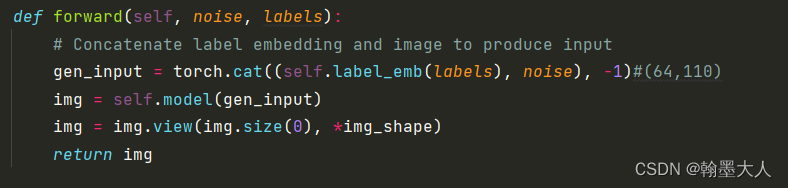
接着是生成器:

将生成的image和编码后的标签输入到模型中,输出一个概率值。
接着计算生成器损失:为了骗过辨别器,希望判别器对于噪声输出的图片判别为1。这里用的MSE,因此不需要对最后输出的概率值进行sigmoid。

接着训练判别器:对于真实的图片由其对应的label,我们希望输出为1,对于假的图片和随机生成的标签,我们希望输出为0,计算两个损失和。
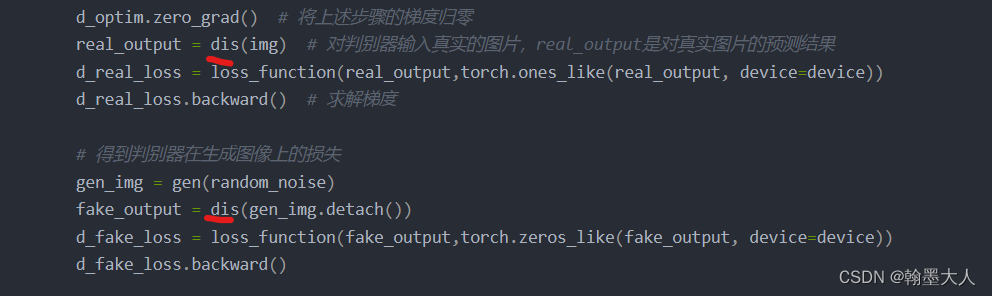
与DCGAN相比,判别器的输入缺少了标签,也就是说生成器的输出是任意的,噪声只是拟合真实图片的分布,而不限制输出的数值等。
6:最后将每一个epoch的输出保存下来:
这里主要限制了label的数值,通过一个for循环,不再是随意的而是10行,每一行是0-9。
结果展示:









站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结