您现在的位置是:首页 >其他 >〖Python网络爬虫实战㉕〗- Ajax数据爬取之Ajax 案例实战网站首页其他
〖Python网络爬虫实战㉕〗- Ajax数据爬取之Ajax 案例实战
- 订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000+
- 说明:本专栏持续更新中,目前专栏免费订阅,在转为付费专栏前订阅本专栏的,可以免费订阅付费专栏,可报销(名额有限,先到先得)。
即将转为付费专栏,更多详细请看,五一或有优惠活动哦。
- 作者:爱吃饼干的小白鼠。Python领域优质创作者,2022年度博客新星top100入围,荣获多家平台专家称号。
最近更新
?上节回顾
前面一节我们介绍了 Ajax 的基本原理和分析方法,在本节中,我们用一个正式的实例来实现一下 Ajax 数据的爬取。我们还是用我们上节课讲到的案例。
⭐️Ajax 案例实战
Ajax(Asynchronous JavaScript and XML)是一种用于创建异步通信和动态交互的技术。它允许在不刷新整个页面的情况下,向服务器发送HTTP请求并获取响应,从而使Web应用程序更加流畅和响应灵活。在本例中,我们将分析一个使用Ajax技术实现分析的案例。
?案例实战
✨准备工作
在本节开始之前,我们需要做好如下准备工作:
- 安装好 Python 3,并成功运行 Python 3 程序。
- 了解 Python HTTP 请求库 requests 的基本用法。
- 了解 Ajax 基础知识和分析 Ajax 的基本方法。
✨确定网址
本节我们以一个我的博客主页网站来试验一下 Ajax 的爬取,我的博客主页链接https://broken.blog.csdn.net/?type=blog,该网站的数据请求是通过Ajax 完成的,页面的内容是通过 JavaScript 渲染出来的,页面如图所示:

这里仍然以我的博客主页为例,接下来用 Python 来模拟这些 Ajax 请求,把我发过的文章爬取下来。
✨初步探索
首先,我们先尝试用之前的 requests 来直接提取页面,看看会得到怎样的结果。用最简单的代码实现一下 requests 获取首页源码的过程,代码如下:
import requests
url = 'https://broken.blog.csdn.net/?type=blog'
html = requests.get(url).text
print(html)我们来运行这个代码,虽然这里我们能看到一些内容,但是,我们往下翻页的就不在网页源代码中。那么,我们怎么样可以获取到其他内容,我们就用上节课讲到的方法。
✨分析请求
打开 Ajax 的 XHR 过滤器,然后一直滑动页面以加载新的页面内容。可以看到,会不断有 Ajax 请求发出。
选定其中一个请求,分析它的参数信息。点击该请求,进入详情页面,如图所示。
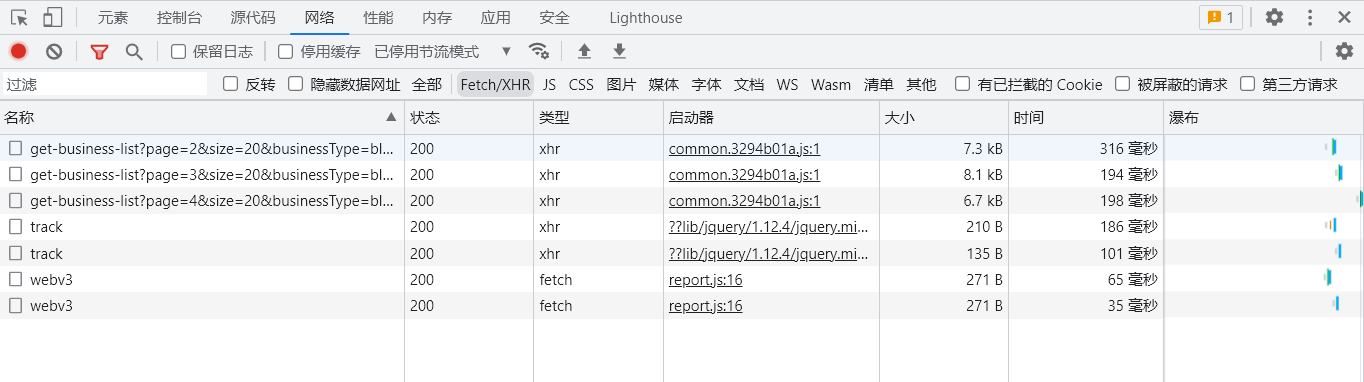
可以发现,这是一个 GET 类型的请求,请求链接为可以发现,这是一个 GET 类型的请求,请求链接为https://blog.csdn.net/community/home-api/v1/get-business-list?page=2&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=BROKEN__Y
请求的参数有8个:page、size=20、businessType=blog、orderby=、noMore=false、year=、month=、username=BROKEN__Y。
随后我们再看看其他请求,可以发现,它们的 size=20、businessType=blog、orderby=、noMore=false、year=、month=、username=BROKEN__Y 始终如一。改变的值就是 page,很明显这个参数是用来控制分页的,page=1 代表第一页,page=2 代表第二页,以此类推。
所以,我们只要修改page的值就可以得到我们要的数据。
接着我们再观察一下响应的数据,切换到 Preview 选项卡,结果如图所示:

这个内容是 JSON 格式的,浏览器开发者工具自动做了解析以方便我们查看。这样我们请求一个接口,就可以得到 20条文章,而且请求时只需要改变 page 参数即可。这样的话,我们只需要简单做一个循环,就可以获取所有文章了。
✨发送请求
我们通过前面的分析,我们会发现这个很简单,没有什么难的。我们接下来,直接开始写代码。
import requests
url = 'https://blog.csdn.net/community/home-api/v1/get-business-list'
params = {
'page': '1',
'size': '20',
'businessType': 'blog',
'orderby': '',
'noMore': 'false',
'year': '',
'month': '',
'username': 'BROKEN__Y',
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
res = requests.get(url,params=params,headers=headers).text
print(res)我们来运行一下,看看什么效果。
{"code":200,"message":"success","traceId":"3affa30c-a4ad-4077-81c5-3fa6413ce52a","data":{"list":[{"articleId":129634466,"title":"基于OpenCV的人脸识别","description":"随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。介绍OpenCV中图像的处理。","url":"https://broken.blog.csdn.net/article/details/129634466","type":1,"top":true,"forcePlan":false,"viewCount":13803,"commentCount":50,"editUrl":"https://mp.csdn.net/console/editor/html/129634466","postTime":"2023-03-21 22:57:19","diggCount":77,"formatTime":"2023.03.21","picList":["https://img-blog.csdnimg.cn/b6f55bd8fcaa4f74b0260531daa83eca.png"]},{"articleId":130650220,"title":"〖Python网络爬虫实战㉔〗- Ajax数据爬取之Ajax 分析案例","description":"Ajax(Asynchronous JavaScript and XML)是一种用于创建异步通信和动态交互的技术。它允许在不刷新整个页面的情况下,向服务器发送HTTP请求并获取响应,从而使Web应用程序更加流畅和响应灵活。在本例中,我们将分析一个使用Ajax技术实现分析的案例。在下一节中,我们用一个正式的实例来实现一下 Ajax 数据的爬取。","url":"https://broken.blog.csdn.net/article/details/130650220","type":1,"top":false,"forcePlan":false,"viewCount":384,"commentCount":24,"editUrl":"https://mp.csdn.net/console/editor/html/130650220","postTime":"2023-05-12 22:37:58","diggCount":12,"formatTime":"前天 22:37","picList":["https://img-blog.csdnimg.cn/8978989ead1740eb8749046ddf7dc81c.jpeg"]},{"articleId":130556344,"title":"自动核对名单详细教程〖Python版〗","description":"大家好,今天我们来给大家分享一个很实用的东西。最近,有粉丝私信我,能不能做一个大学习自动核对名单的程序,我这个粉丝呢,她作为班级团支书,每次核对青年大学习的名单感到特别的头疼。那我接下来就来写一个能够自动核对大学习名单的小程序。","url":"https://broken.blog.csdn.net/article/details/130556344","type":1,"top":false,"forcePlan":false,"viewCount":381,"commentCount":13,"editUrl":"https://mp.csdn.net/console/editor/html/130556344","postTime":"2023-05-08 13:21:16","diggCount":15,"formatTime":"2023.05.08","picList":["https://img-blog.csdnimg.cn/22cd8e51ac744d52be93bf94123f1737.jpeg"]},{"articleId":130547061,"title":"〖Python网络爬虫实战㉓〗- Ajax数据爬取之什么是Ajax","description":"Ajax,全称为 Asynchronous JavaScript and XML,即异步的 JavaScript 和 XML。它不是一门编程语言,而是利用 JavaScript 在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。对于传统的网页,如果想更新其内容,那么必须刷新整个页面,但有了 Ajax,便可以在页面不被全部刷新的情况下更新其内容。","url":"https://broken.blog.csdn.net/article/details/130547061","type":1,"top":false,"forcePlan":false,"viewCount":438,"commentCount":11,"editUrl":"https://mp.csdn.net/console/editor/html/130547061","postTime":"2023-05-07 21:19:17","diggCount":8,"formatTime":"2023.05.07","picList":["https://img-blog.csdnimg.cn/264fed02132c4d12b2acfb8eb8a13440.jpeg"]},{"articleId":130494876,"title":"〖Python网络爬虫实战㉒〗- 数据存储之数据库详解","description":"本节讲解了使用 MYSQL和 MongoDB 两种数据库,后面我们会在实战案例中应用这些操作进行数据存储。","url":"https://broken.blog.csdn.net/article/details/130494876","type":1,"top":false,"forcePlan":false,"viewCount":476,"commentCount":13,"editUrl":"https://mp.csdn.net/console/editor/html/130494876","postTime":"2023-05-04 21:52:11","diggCount":10,"formatTime":"2023.05.04","picList":["https://img-blog.csdnimg.cn/87b93e59572e473b94cac6fb61a636e1.jpeg"]},{"articleId":130475339,"title":"从‘孔乙己长衫’现象看社会不公","description":"最近,大家自我调佩是“当代孔乙己”,学历成为思想负担,找工作时高不成低不就。尽管我们可能不一脱成名,但是如果你真有把长衫都脱去的决心和执行,那我想,你一定会赢的,因为你脱的够彻底,也就意味着抛弃过去,勇往直前,我们还怕什么呢,这样,也许真的能披荆斩棘,一帆风顺了。关键又有几个人能做到这一点哦。","url":"https://broken.blog.csdn.net/article/details/130475339","type":1,"top":false,"forcePlan":false,"viewCount":1093,"commentCount":27,"editUrl":"https://mp.csdn.net/console/editor/html/130475339","postTime":"2023-05-03 18:15:23","diggCount":15,"formatTime":"2023.05.03","picList":["https://img-blog.csdnimg.cn/e73179c8fdd947539117565b65a4f384.png"]},{"articleId":130444044,"title":"〖Python网络爬虫实战㉑〗- 数据存储之JSON操作","description":"loadloadsdump和dumps,1、json.loads将一个Python数据结构(字符串)转换为JSON格式数据2. json.dumps将一个JSON编码的字符串转换回一个Python数据结构,即字符串3. json.dump() 和 json.load() 来编码和解码JSON数据,用于处理文件我们可以这样记忆:按照如下记忆:文件:dump、load字符串:dumps、loads编码:dump、dumps解码:load、loads。","url":"https://broken.blog.csdn.net/article/details/130444044","type":1,"top":false,"forcePlan":false,"viewCount":640,"commentCount":19,"editUrl":"https://mp.csdn.net/console/editor/html/130444044","postTime":"2023-04-29 22:52:15","diggCount":11,"formatTime":"2023.04.29","picList":["https://img-blog.csdnimg.cn/86b3bdb8e03443e7acc85733a3c02c27.jpeg"]},{"articleId":130435996,"title":"〖Python网络爬虫实战⑳〗- 数据存储之CSV操作实战","description":"我们在学完这个案例之后,大家就会明白这个其实很简单,其他的只需要模仿这个来写就可以了。CSV文件实战需要考虑多个方面,包括选择合适的文件格式、设置正确的文件头、使用有效的编码方式等。我们这里就不过多介绍,我们还是数据库用到的机会比较大。","url":"https://broken.blog.csdn.net/article/details/130435996","type":1,"top":false,"forcePlan":false,"viewCount":623,"commentCount":16,"editUrl":"https://mp.csdn.net/console/editor/html/130435996","postTime":"2023-04-28 22:27:09","diggCount":14,"formatTime":"2023.04.28","picList":["https://img-blog.csdnimg.cn/edcb8c1c456f45d6afb4e0c48da29180.jpeg"]},{"articleId":130375191,"title":"〖Python网络爬虫实战⑲〗- 数据存储之CSV文件","description":"我们了解了 CSV 文件的写入和读取方式。这也是一种常用的数据存储方式,需要熟练掌握。但是,CSV文件的使用也存在一些限制和局限性。例如,CSV文件只能存储纯文本数据,不能存储二进制数据或者复杂的数据结构。此外,CSV文件的格式比较固定,不能自定义格式或者添加数据分隔符等。为了解决这些问题,我们需要寻找更好的数据存储方式。我们一般会使用“JSON”的数据存储格式,它可以存储多种类型的数据,并且支持自定义格式和数据分隔符等。后面我们也会讲到JSON数据的保存。","url":"https://broken.blog.csdn.net/article/details/130375191","type":1,"top":false,"forcePlan":false,"viewCount":1014,"commentCount":25,"editUrl":"https://mp.csdn.net/console/editor/html/130375191","postTime":"2023-04-25 23:21:31","diggCount":16,"formatTime":"2023.04.25","picList":["https://img-blog.csdnimg.cn/71bafaff78f143d9bce9f2613832cd2d.jpeg"]},{"articleId":130330178,"title":"〖Python网络爬虫实战⑱〗- 数据存储之TXT纯文本","description":"上面便是利用 Python 将我们获取到的数据保存为 TXT 文件的方法,这种方法简单易用,操作高效,是一种最基本的保存数据的方法。保存TXT文件是非常简单的。下一篇文章,我们准备介绍关于CSV文件的保存,如果,大家想多出一点CSV实战的文章,在评论区留言,我就多更一点,如果没有的话,我就一篇文章带过。","url":"https://broken.blog.csdn.net/article/details/130330178","type":1,"top":false,"forcePlan":false,"viewCount":883,"commentCount":43,"editUrl":"https://mp.csdn.net/console/editor/html/130330178","postTime":"2023-04-23 21:55:52","diggCount":30,"formatTime":"2023.04.23","picList":["https://img-blog.csdnimg.cn/873be33f974c40ad9e82b7fe4d1837c7.jpeg"]},{"articleId":130273446,"title":"【必读】关于专栏〖Python网络爬虫实战〗转为付费专栏的订阅说明","description":"我们后面会不定期举行优惠购买付费专栏活动,我们最近初步计划于5月1日左右,向广大用户开方,目前,已经有17位小伙伴订阅了本专栏,由于平台看不到哪些人订阅了本专栏。在2023-05-01之后留言截图的无效,因为,转为付费专栏之后,所有订阅本专栏的会自动取消。之前,博主承诺,在转为付费专栏前订阅本专栏的,可以免费订阅付费专栏,可报销。本专栏从2023-04-03开设,累计至今,已更新17篇文章。在本专栏留下关注本专栏的截图的,购买本专栏可全额报销。在2023-06-01之后在订阅本专栏的,无报销资格。","url":"https://broken.blog.csdn.net/article/details/130273446","type":1,"top":false,"forcePlan":false,"viewCount":416,"commentCount":5,"editUrl":"https://mp.csdn.net/console/editor/html/130273446","postTime":"2023-04-20 19:47:08","diggCount":3,"formatTime":"2023.04.20","picList":["https://img-blog.csdnimg.cn/1036458cc33d468493bfce323f479153.jpeg"]},{"articleId":130255490,"title":"〖Python网络爬虫实战⑰〗- 网页解析利器parsel实战","description":"在parsel实战中,我完成了一个使用parsel库的选择器来选择 特定元素的内容。在这个实战中,我使用了xpath和css方法来指定选择的元素的位置和样式。Parsel是一个用于解析JSON数据的Python库。","url":"https://broken.blog.csdn.net/article/details/130255490","type":1,"top":false,"forcePlan":false,"viewCount":951,"commentCount":35,"editUrl":"https://mp.csdn.net/console/editor/html/130255490","postTime":"2023-04-19 23:42:01","diggCount":18,"formatTime":"2023.04.19","picList":["https://img-blog.csdnimg.cn/9f76b947d62a4736a486bd1dc4d022e5.jpeg"]},{"articleId":130208876,"title":"〖Python网络爬虫实战⑯〗- 网页解析利器parsel","description":"Parsel是一个用于解析JSON数据的Python库。它提供了一个简单易用的API,可以轻松地从JSON文件或字符串中解析数据。可以对 HTML 和 XML 进行解析,并支持使用 XPath 和 CSS Selector 对内容进行提取和修改,同时它还融合了正则表达式提取的功能。功能灵活而又强大。parsel 是一个融合了 XPath、CSS Selector 和正则表达式的提取库,功能强大又灵活,建议好好学习一下。","url":"https://broken.blog.csdn.net/article/details/130208876","type":1,"top":false,"forcePlan":false,"viewCount":921,"commentCount":6,"editUrl":"https://mp.csdn.net/console/editor/html/130208876","postTime":"2023-04-17 23:18:44","diggCount":7,"formatTime":"2023.04.17","picList":["https://img-blog.csdnimg.cn/86e78c497e7448aab32f7e3c93b1dcfa.jpeg"]},{"articleId":130187487,"title":"〖Python网络爬虫实战⑮〗- pyquery的使用","description":"PyQuery 是 Python 仿照 jQuery 的严格实现。语法与 jQuery 几乎完全相同,所以不用再去费心去记一些奇怪的方法了。","url":"https://broken.blog.csdn.net/article/details/130187487","type":1,"top":false,"forcePlan":false,"viewCount":1327,"commentCount":49,"editUrl":"https://mp.csdn.net/console/editor/html/130187487","postTime":"2023-04-16 21:14:08","diggCount":30,"formatTime":"2023.04.16","picList":["https://img-blog.csdnimg.cn/787720cece854478b2d773b11488a59f.jpeg"]},{"articleId":130159429,"title":"〖Python网络爬虫实战⑭〗- BeautifulSoup详讲","description":"BeautifulSoup 是一个用于解析和生成 HTML,XML 和其他网页的 Python 库。它可以用于爬取,解析和提取网页内容,并能够通过转换器实现惯用的文档导航、查找、修改文档的方式。BeautifulSoup是一个用Python编写的库,用于解析HTML和XML文档,并提取其中的数据。它是一个简单易用的工具,可以提高从HTML和XML文档中提取数据的效率。BeautifulSoup使用正则表达式和re模块来解析HTML和XML文档。它支持各种类型的标签,例如","url":"https://broken.blog.csdn.net/article/details/130159429","type":1,"top":false,"forcePlan":false,"viewCount":1121,"commentCount":18,"editUrl":"https://mp.csdn.net/console/editor/html/130159429","postTime":"2023-04-14 22:11:42","diggCount":17,"formatTime":"2023.04.14","picList":["https://img-blog.csdnimg.cn/a01650dc30f040efb412c02e9d56a4c0.jpeg"]},{"articleId":130113275,"title":"〖Python网络爬虫实战⑬〗- XPATH实战案例","description":"我们通过学习了简单的Xpath操作,以及在另外一篇xpath的实战案例下,本文,继续分享一个关于xpath的实战案例。xpath最大的难点就是如何写下path后面的语法,我们要找到对应的节点,就可以了。","url":"https://broken.blog.csdn.net/article/details/130113275","type":1,"top":false,"forcePlan":false,"viewCount":705,"commentCount":19,"editUrl":"https://mp.csdn.net/console/editor/html/130113275","postTime":"2023-04-12 18:18:42","diggCount":13,"formatTime":"2023.04.12","picList":["https://img-blog.csdnimg.cn/e7b8d0b5b2c34ef4a19750bbedd89c2d.jpeg"]},{"articleId":130070529,"title":"〖Python网络爬虫实战⑫〗- XPATH语法介绍","description":"前面我们实现了一个最基本的爬虫,但提取页面信息时使用的是正则表达式,过程比较烦琐,且万一有地方写错了,可能会导致匹配失败、所以使用正则表达式提取页面信息多少还是有些不方便.对于网页的节点来说、可以定义id,class或其他属性,而且节点之间还有层次关系,在网页中可以通过XPath或CSS选择器来定位一个或多个节点。那么、在解析页面时,利用XPath或CSS选择器提取某个节点,然后调用相应方法获取该节点的正文内容或者属性,不就可以提取我们想要的任意信息了吗?","url":"https://broken.blog.csdn.net/article/details/130070529","type":1,"top":false,"forcePlan":false,"viewCount":631,"commentCount":7,"editUrl":"https://mp.csdn.net/console/editor/html/130070529","postTime":"2023-04-10 22:21:37","diggCount":5,"formatTime":"2023.04.10","picList":["https://img-blog.csdnimg.cn/57c112d23f3d417fb23385f2c0d82b3e.jpeg"]},{"articleId":130044425,"title":"〖Python网络爬虫实战⑪〗- 正则表达式实战(二)","description":"大家就会发现我们就把每个链接地址获取了下来。正则表达式是不是很神奇。大家可以尝试获取其他的数据。我们获取到了图片地址,我们还可以保存下来,在后面的教学过程中,会教大家如何保存下来,这里重点是练习正则表达式。","url":"https://broken.blog.csdn.net/article/details/130044425","type":1,"top":false,"forcePlan":false,"viewCount":589,"commentCount":0,"editUrl":"https://mp.csdn.net/console/editor/html/130044425","postTime":"2023-04-09 17:34:35","diggCount":0,"formatTime":"2023.04.09","picList":["https://img-blog.csdnimg.cn/8a8335490e10438d9f822738906d5208.jpeg"]},{"articleId":130042435,"title":"〖Python网络爬虫实战⑩〗- 正则表达式实战(一)","description":"今天,我们先通过一个简单的小案例,来学习正则表达式是如何使用的,下一篇,我们继续讲一个案例,加深大家对正则表达式的理解。","url":"https://broken.blog.csdn.net/article/details/130042435","type":1,"top":false,"forcePlan":false,"viewCount":397,"commentCount":0,"editUrl":"https://mp.csdn.net/console/editor/html/130042435","postTime":"2023-04-09 15:40:24","diggCount":0,"formatTime":"2023.04.09","picList":["https://img-blog.csdnimg.cn/e87b37225e4a4d2b98ec9a18c9b2ec7a.jpeg"]},{"articleId":130032579,"title":"〖Python网络爬虫实战⑨〗- 正则表达式基本原理","description":"我们可以从HTML代码提取我们想要的数据。我们知道正则表达式就是其中一个有效的办法。通过本文我们基本了解了其中的原理。后面我们将通过两个具体案例来加深对正则表达式的理解。","url":"https://broken.blog.csdn.net/article/details/130032579","type":1,"top":false,"forcePlan":false,"viewCount":1569,"commentCount":11,"editUrl":"https://mp.csdn.net/console/editor/html/130032579","postTime":"2023-04-08 19:21:15","diggCount":15,"formatTime":"2023.04.08","picList":["https://img-blog.csdnimg.cn/5f36faa4684f4005a930c607f694e16b.jpeg"]}],"total":159}}
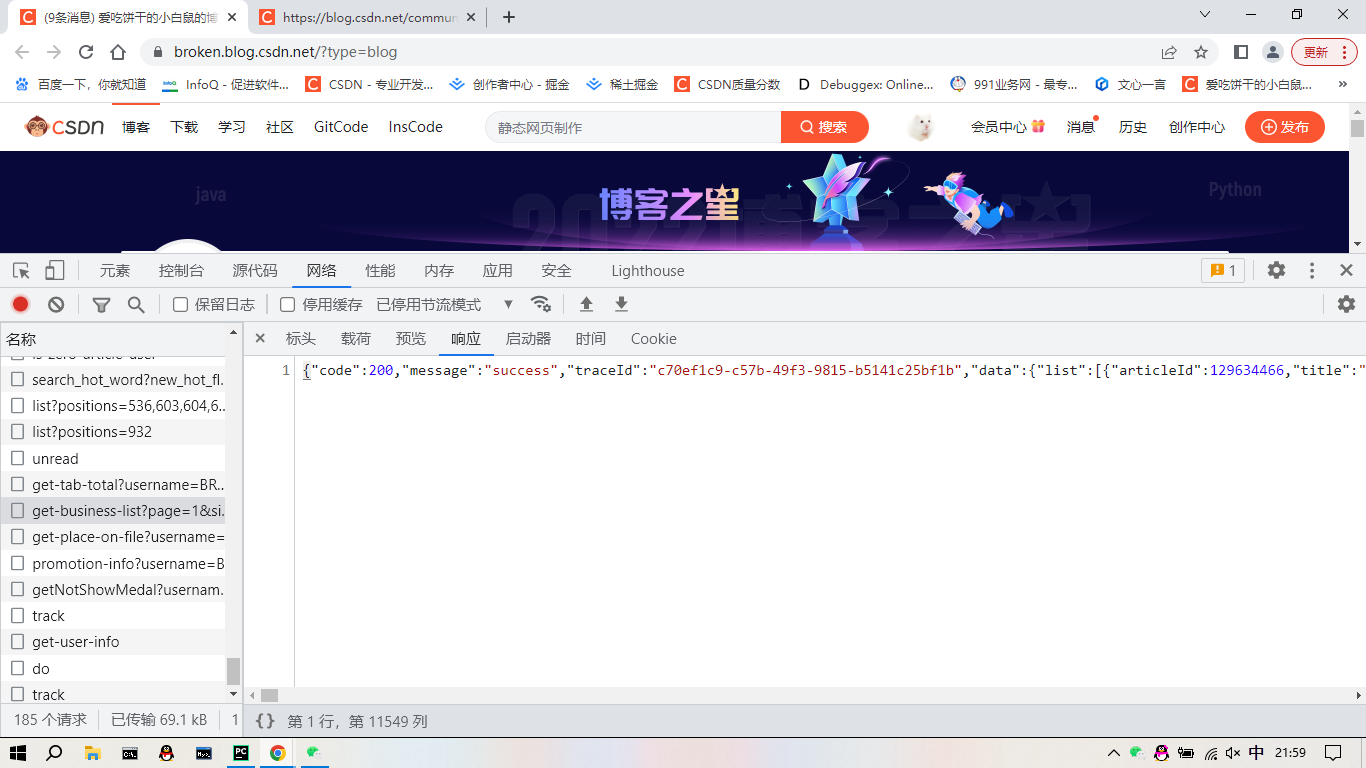
我们可以看到,内容和我们在浏览器看到的响应是一样的,说明,我们就基本上成功了一半。
✨解析数据
我们接下来就是解析数据,我们很容易发现,这个是json类型的数据,我们直接提取他。我们直接写代码。我们这里只提取文章的标题,大家感兴趣的话,还可以尝试提取其他的内容。
import requests
url = 'https://blog.csdn.net/community/home-api/v1/get-business-list'
params = {
'page': '1',
'size': '20',
'businessType': 'blog',
'orderby': '',
'noMore': 'false',
'year': '',
'month': '',
'username': 'BROKEN__Y',
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
res = requests.get(url,params=params,headers=headers)
# print(res)
html_lists = res.json()['data']['list']
for html_list in html_lists:
title = html_list['title']
print(title)我们来运行一下,看看效果。
基于OpenCV的人脸识别
〖Python网络爬虫实战㉔〗- Ajax数据爬取之Ajax 分析案例
自动核对名单详细教程〖Python版〗
〖Python网络爬虫实战㉓〗- Ajax数据爬取之什么是Ajax
〖Python网络爬虫实战㉒〗- 数据存储之数据库详解
从‘孔乙己长衫’现象看社会不公
〖Python网络爬虫实战㉑〗- 数据存储之JSON操作
〖Python网络爬虫实战⑳〗- 数据存储之CSV操作实战
〖Python网络爬虫实战⑲〗- 数据存储之CSV文件
〖Python网络爬虫实战⑱〗- 数据存储之TXT纯文本
【必读】关于专栏〖Python网络爬虫实战〗转为付费专栏的订阅说明
〖Python网络爬虫实战⑰〗- 网页解析利器parsel实战
〖Python网络爬虫实战⑯〗- 网页解析利器parsel
〖Python网络爬虫实战⑮〗- pyquery的使用
〖Python网络爬虫实战⑭〗- BeautifulSoup详讲
〖Python网络爬虫实战⑬〗- XPATH实战案例
〖Python网络爬虫实战⑫〗- XPATH语法介绍
〖Python网络爬虫实战⑪〗- 正则表达式实战(二)
〖Python网络爬虫实战⑩〗- 正则表达式实战(一)
〖Python网络爬虫实战⑨〗- 正则表达式基本原理我们可以看到,我们就把第一页的文章获取下来了。
✨多页爬取
那么,我们怎么实现爬取多页呢,我们之前说了page的参数,这个参数是控制页数的。我们只需要简单做一个循环,就可以获取所有文章了。
import requests
for page in range(1,10)
url = 'https://blog.csdn.net/community/home-api/v1/get-business-list'
params = {
'page': page,
'size': '20',
'businessType': 'blog',
'orderby': '',
'noMore': 'false',
'year': '',
'month': '',
'username': 'BROKEN__Y',
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
res = requests.get(url,params=params,headers=headers)
# print(res)
html_lists = res.json()['data']['list']
for html_list in html_lists:
title = html_list['title']
print(title)我们这里就不去运行了,但是,我们可以把效果告诉大家,可以获取我博客主页所以文章的标题。
?总结
本节中我们通过一个案例来体会了 Ajax 分析和爬取的基本流程,希望大家通过本节能够更加熟悉 Ajax 的分析和爬取实现。
另外,我们也观察到,由于 Ajax 接口大部分返回的是 JSON 数据,所以在一定程度上可以避免一些数据提取的工作,这也在一定程度上减轻了工作量。







站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结