您现在的位置是:首页 >技术杂谈 >GPT前2代版本简介网站首页技术杂谈
GPT前2代版本简介
承接上文ChatGPT进化的过程简介
2018年,Google的Bert和OpenAI的GPT绝代双骄,两者非常像,都是语言模型,都基本上是无监督的方式去训练的,你给我一个文本,我给你一个语言模型出来。
GPT前两代没有什么特别的,第三代才有点大发神威。
GPT还不是特别火的时候,已经预计每天产生450亿词,每小时生成100W本书,所以以后看到的东西,可能是AI生成出来的。
这仅仅是22年5月份的GPT-3的情况。
微软给OpenAI提供大规模的数据中心、上万个GPU并行训练 ,其他公司很难复现,因成本太高,训练GPT3,电费画了1200万美元。
22年初,最开始的GPT3的应用,只是在传统的GPT基础之上做的扩展,并不是让网络结构更大、训练数据更多,而是让网络模式去解决一些以前解决不了的问题。
传统的GPT存在的问题
-
存在偏见
NLP偏见非常大,因为它学的是互联网当中历史上一切的东西,在历史上会存在一些偏见,比如,
我今天买了一个华为手机,AI告诉你心情非常失落;买了苹果手机,心情非常高兴。
AI大概率会认为黑人是杀人犯,白人是教授、医生。
会把这些偏见强行加入进来,这是最大的问题。
-
答非所问
可能输出的是长篇大论,可能自作聪明生成一些没用的东西。
GPT可以生成小说、代码等,你给它一些价值的内容,都可以按照要求去生成。
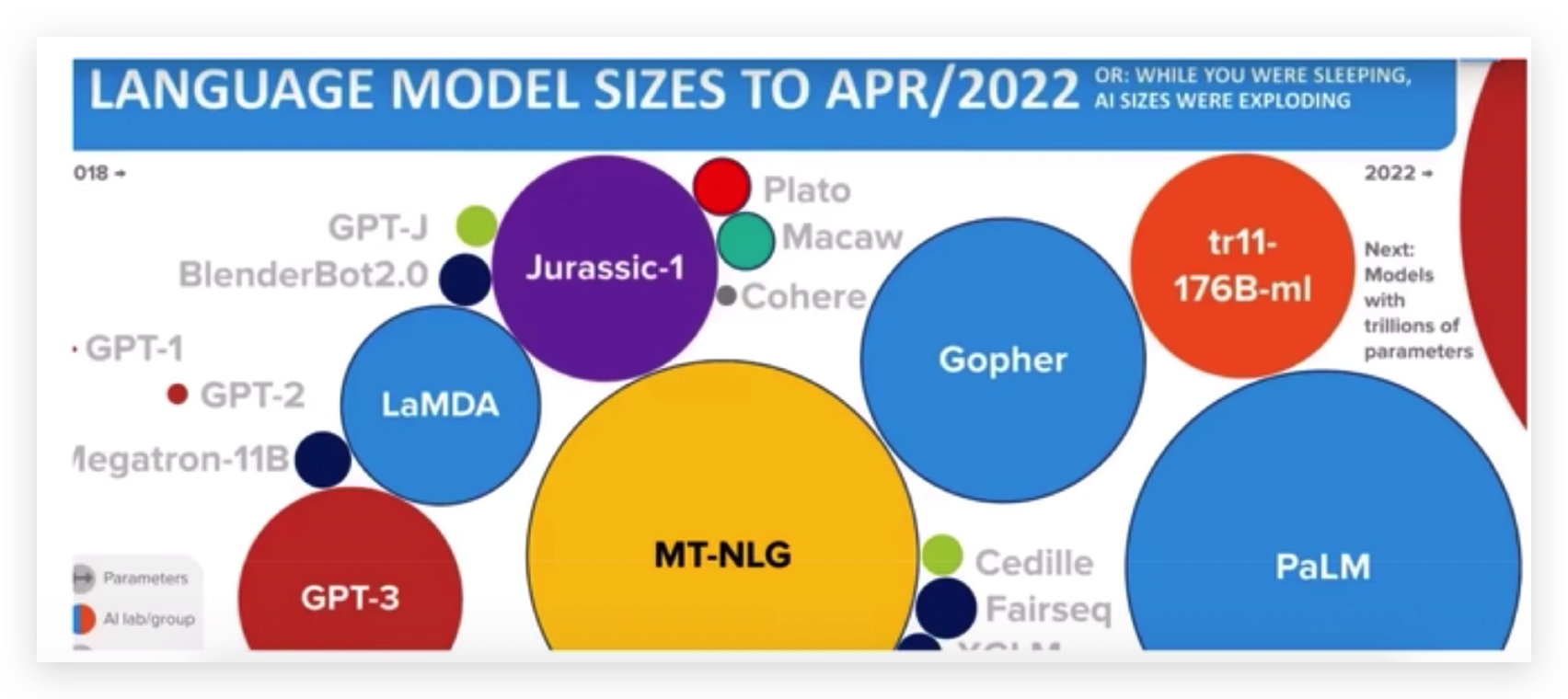
以前一年有几个大模型出现,现在平均每4天就有一个大模型问世。
GPT这个圈大概有1750亿的权重参数,其他更大的圆,权重参数更多。更大的语言模型,训练生成的成本会更高。
在NLP领域当中,一定是模型越大、参数越大,越好吗?
在训练集和验证集中是这样的,数据、标签越多,答案越固定。 NLP比的是一定做的对吗? 就一种固定答案吗? 不是的。 我比你描述的更好,但它是一种错误的答案,跟原始答案不一样,你能说我错了吗!
ChatGPT在训练和做策略的时候,它追求的不是一个特别大的参数量。 参数越大,模型越复杂,答案越固定,越朝着正确答案去逼近。
而对话聊天,理解的东西是通俗的,不需要一摸一样,只需要近似和好理解就行。
GPT1
GPT全称Generate Pre-Training,生成式预训练模型怎么训练呢?
不用给它标签,而是输入一句话,让它预测下一个词。
比如输入“今天天气”,预测下一个字是“真”,将“今天天气真”输入作为一句话,预测下一个字是“好”,就这样一个字一个字的往外蹦。
Bert是基于“完形填空”去做的,有上下文语境。 GPT难度更大,生成式的结果不固定,可变的因素太多了,GPT是预测后文,预测未来的事。
GPT损失函数就是预测下一个词
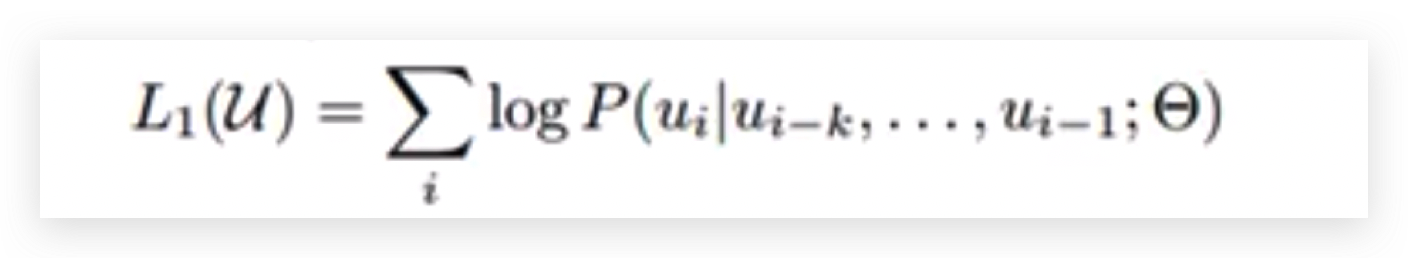
输入一组权重参数和前文,来预测后文。
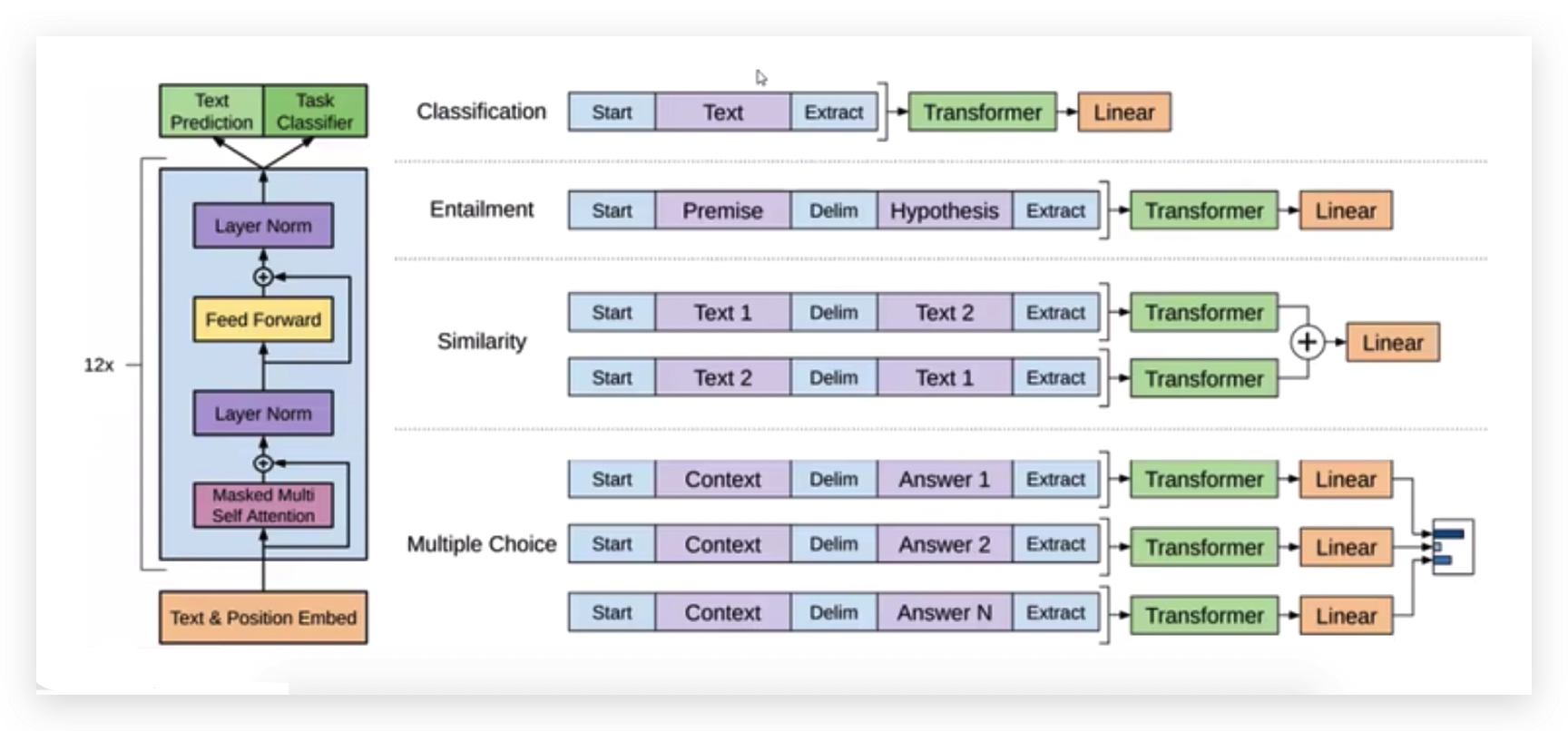
GPT1有一个问题,训练了一个预训练模型,后续怎么应用呢?比如应用到机器翻译、文本摘要。。
训练好的语言模型要先理解上下文以及预测后面是什么,但是如果想再做自己的事情,那要再连下一个任务了,即要连接一个输出层,比如连接一个全连接层Linear,做分类任务。
所以GPT第一代版本不是我们所希望的,先有预训练模型,再结合输出层,做一步任务。即预训练模型的基础之上做了一个微调。
GPT2
在GPT第二代版本中,出现了zero-shot,即以不变应万变,模型训练完了之后,无论做什么任务,都不需要微调,而是通过暗示的方式。
比如我想做一个分类任务,预测下“你有一双漂亮的大眼睛”这句话是夸我还是骂我呢,则加一个暗示“这句话是夸我还是骂我呢”。 把这个提示跟上下文一起传入到这个模型当中,模型在学习的时候,它看到了输入的这句话,也看到了提示,那接下来回答的时候,需要参考这个提示。
这是zero shot做分类的场景。
还可以做机器翻译,比如输入一句话,再给它一个提示,将这句话翻译成英文。
还可以做回归任务,比如输入一句话,预测下这句话中含有的单词个数。
GPT2的思想是先有一个统一的大模型,在这个模型当中无论后续做什么,做哪个领域的任务,都可以过来问这个模型,都可以加个提示,加了提示之后,模型在回答的时候围绕着前文的输入,再根据提示继续往下生成。
从GPT2开始,大家看到希望了,在NLP这个领域又统一成了一个生成式的大模型,而不是有很多小的下游任务进行微调。
GPT如何增加多样性?
基于前面的词,预测下一个词,再根据前面两个词预测第三个词,再根据前面三个词预测第四个词。。。
在预测的时候会陷入一个死循环,比如成语接龙的时候,

生成的东西都一样,就是死循环。
再比如

不能老说“然后”,希望有点多样性,对于模型来说也是如此,前面总在说的东西 后面就别再重复了。
GPT是通过“温度Temperature”来提高多样性的,对预测结果进行概率重新选择。
GPT生成的结果并不是唯一的,比如你问GPT“今天晚上吃什么?”,结果可能是“吃香蕉”(输出概率是0.1)、“吃蔬菜(概率0.2)”、“吃鸡肉(概率0.3)”、“吃羊肉(概率0.4)”。
在这个任务当中,它每次一定输出概率最高的吗? 吃羊肉的概率最高,不能天天吃羊肉吧。
GPT实际上是做一个采样,跟买彩票一样,虽然中奖的概率低,但并不是说是不可能事件,只是采样到的可能性比较低。
计算各类别预测结果,但是要在不同类别预测结果的基础之上做一个采样,概率最高的采样到的可能性越大,概率低的采样到的可能性低。
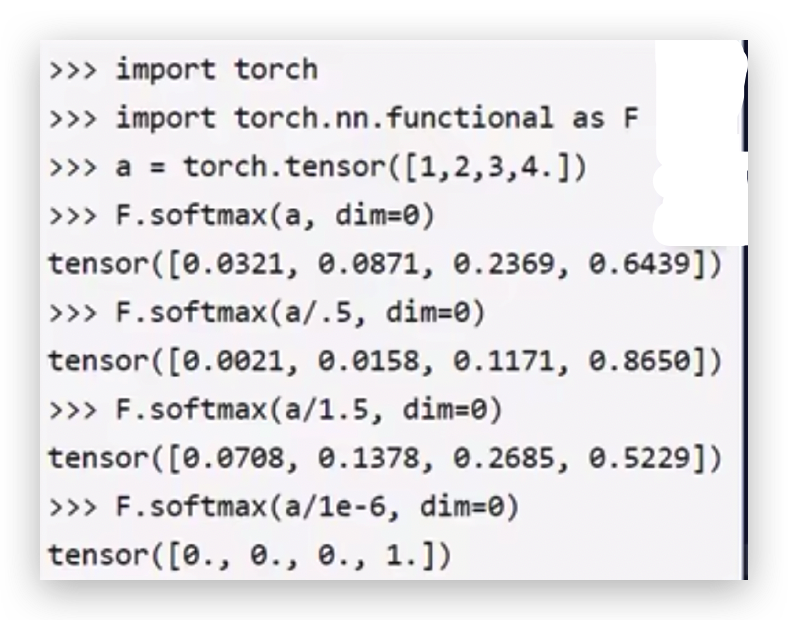
输入“1、2、3、4”,将输入通过softmax转换成概率值,数字越大,概率越高,数字越小,概率越低。
能不能改变概率的分布呢?
除上一个小于0的数比如0.5之后,之前的数值就会放大,比如之前最高的概率是0.6439除以0.5变成了0.8650,概率值被放大,变得越高,越容易被输出,准备越准。
T越小于1或小于1的程度越大,越想得到什么就是越准的,越准的那一个得分越高 ,得分越高,概率值越高。
所以GPT3中温度设置的越低,输出就越固定,今天晚上吃羊,明天再问还是吃羊,因为羊的概率实在太高了。
温度为1默认是softmax值,温度越高,多样性越丰富,温度越低,相当于越希望得到最准的那个。
Top k 和 Top p
但是并不是说什么结果都能输出来,还需要设置2个参数Top k和Top p。
生成一个词,有10万种可能性,并不是说所有词都能生成出来,不可能“今天吃啥”,输出“吃个大理石”、“吃个耳机”,这些词别给采样出来。
Top k在任务中就选概率前10个来采样,后面都给设置成0,后面的太离谱了,就别往外输出了。
Top p是累加,就是取前多少个,能让累加概率得到0.9以上或0.95以上。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结