您现在的位置是:首页 >技术教程 >大数据之PySpark的RDD创建和分区网站首页技术教程
大数据之PySpark的RDD创建和分区
简介大数据之PySpark的RDD创建和分区
前言
#博学谷IT学习技术支持#
上篇文章对PySpark的RDD做了简单的介绍,以及总结了RDD的特性,该篇文章主要介绍RDD的创建方式,PySpark的RDD创建方式主要有两种,一种是在程序中直接创建,另一种是通过加载外部系统创建。
一、RDD创建
- 创建SparkContext对象
SparkContext为Spark程序的入口,代表和Spark集群的链接,Spark集群中通过SparkContext创建RDD,创建SparkContext对象前需要先创建SparkConf,该SparkConf对象用来传递应用的基本信息。

- 并行化方式创建RDD
第一步已经得到SparkContext对象,通过该对象的parallelize方法即可创建RDD,该方法需要传入可迭代的对象或集合;

使用SparkContext对象时可以指定分区数量

- 读取小文件创建RDD
实际需求中,有时需要读取大量的小文件,文件不大,但数量很多,如果一个文件读取为RDD的一个分区,处理数据效率较为低下,此时可以使用SparkContext对象的wholeTextFiles方法,该方式主要用于读取小文件。
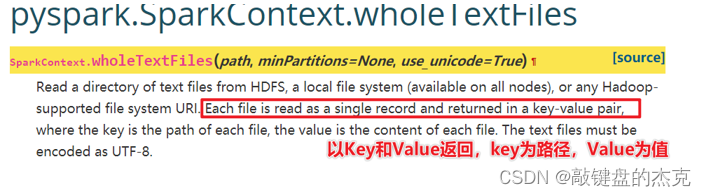
- PySpark可以从Hadoop支持的任何存储源创建RDD,例如本地文件系统、HDFS、HBase等,同时支持整个目录,多文件,并且也支持压缩文件。
使用SparkContext对象的textFile即可读取外部数据,返回DataFrame对象

二、RDD分区数
- 概念
分区是一个偏物理层的概念,是RDD并行计算的单位;数据在RDD上被切分为多个子集合,一个子集合可以看成一个分区,运算逻辑会作用在每一个分区上,每个分区是由单独的任务执行,所以分区数越高,整个应用的并行度越高。 - 影响分区数据的因素,主要有三点:·
(1)RDD分区的原则是使分区数尽可能等于集群CPU核数,这样可最大限度发挥CPU的性能
(2)实际操作中,为了充分利用CPU的性能,并行度会设置为CPU核数的2至3倍
(3)与启动时指定的核数、调用方法时指定的分区数、文件本身分区数有关系
总结
RDD的创建主要有两种,一种是并行化方式创建RDD,另一种是通过外部存储系统创建RDD,具体使用哪种方式,需要根据实际需求判断适合使用哪种方式创建RDD。
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结