您现在的位置是:首页 >技术杂谈 >智能的本质人工智能与机器人领域的64个问题网站首页技术杂谈
智能的本质人工智能与机器人领域的64个问题
以艾伦·纽厄尔(Allen Newell)和赫伯特·西蒙(Herbert Simon)为代表,他们基本上倾向于智能已经达到数理逻辑的最高形式,并将符号处理作为研究重点,他们共同发表了著名论文《逻辑理论家》(Logic Theorist,1956)。这一派取得的第一个大的突破当属约翰·麦卡锡发表的文章《常识性程序》(Programs with Common Sense,1959),他认为:“将来随着科技的发展,机器对重复性工作及计算类任务的处理能力会轻松地超越人类,拥有‘常识’的智能才能被称为智能,常识主要源自世界的知识积累。”
阿兰·图灵在他的论文《计算机器与智能》(Computing Machinery and Intelligence,1950)中还提出了可以通过测试确认机器具备“智能”的机器思维概念——“图灵测试”
对于那些设计“神经网络”的人来说,问题在于连接的微调,能够使网络整体作出与输入相匹配的正确解释。例如,当出现一个苹果的形象时,网络就会反应出“苹果”一词,这种方式被称为“训练网络”。又例如,当向此系统展示很多苹果并最终要求系统产生“苹果”的回答时,系统会调整联结网络,从而识别多个苹果,这被称为“监督学习”。所以,系统的关键是要调整连接的强度。因而人工智能学科中此分支的另一种叫法是“联结主义”(connectionism)。弗兰克·罗森布拉特(Frank Rosenblatt)在1957年发明的感知机(Perceptron)模型以及奥利弗·塞尔弗里奇(Oliver Selfridge)在1958年提出的“万魔殿”(Pandemonium)理论是“神经网络”的开路先锋:摒弃知识表达和逻辑推理,独尊传播模式和自动学习。
智能根本不需要以“智能”行为的产生为前提,而只需要一组传感器和执行器就足够了。随着“车辆”复杂程度的不断提高,车辆本身也会表现出日益发达的智能行为。
1982年,约翰·霍普菲尔德(John Hopfield)基于对退火物理过程的模拟,提出了新一代的神经网络模型,正式开启了人工神经网络学科的新时代。
霍普菲尔德的主要成就在于发现其与统计力学之间的相似性。
2012年,深度学习神经网络领域取得了里程碑式的成就,亚历克斯·克里泽夫斯基 (Alex Krizhevsky) 与其他几位多伦多大学辛顿研究组的同事在一篇深度卷积神经网络方面的研究论文中证实:在深度学习训练期间,当处理完2000亿张图片后,深度学习的表现要远胜于传统的计算机视觉技术。
2013年,辛顿加入谷歌,而燕乐存加入Facebook。
有意思的是,虽然在深度学习领域做出杰出贡献的专家并非生于美国,但是他们最终都来到美国从事相关的工作。其中,燕乐存和约书亚·本吉奥是法国人,辛顿是英国人,吴恩达是中国人,亚历克斯·克里泽夫斯基和伊利亚·苏特斯科娃是俄罗斯人,布鲁诺·奥尔斯豪森是瑞士人。
深度信念网络是由多个受限玻尔兹曼机上下堆叠而组成的分层体系结构,每一个受限玻尔兹曼机(简称为RBM)的输出作为上一层RBM的输入,而且最高的两层共同形成相连存储器。一个层次发现的特征成为下一个层次的训练数据。
不过,深度信念网络(DBNs)仍存在一定的局限性:它属于“静态分类器”(static classifiers),即它们必须在一个固定的维度进行操作。然而,语音和图像并不会在同一固定的维度出现,而是在(异常)多变的维度出现。所以它们需要“序列识别”(即动态分类器)加以辅助,但DBNs却爱莫能助。所以扩展DBNs到序列模式的一个方法就是将深度学习与“浅层学习架构”(例如,Hidden Markov Model)相结合。
“深度学习”的另一条发展主线源于邦彦福岛(Kunihiko Fukushima) 1980年创立的卷积网络理论。在此理论基础上,燕乐存(Yann LeCun)于1998年成功建立了第二代卷积神经网络。卷积网络基本上属于三维层级的神经网络,专门用于图像处理。
贝叶斯的概率理论将知识解释为一组概率(不确定的)表述,而把学习解释为改善那些概率事件的过程。随着获得更多的证据,人们会逐步掌握事物的真实面貌。
1996年,发展心理学家珍妮·萨弗朗(Jenny Saffran)的研究表明,婴儿正是通过概率理论了解世界,而且他们能在很短的时间内掌握大量事实。所以,贝叶斯定理在不经意间揭示了关于大脑工作方式的基本原理,我们不应将其简单地当做数学理论。
目前多个深度学习平台开放成为开源软件,譬如纽约大学的Torch,加州大学伯克利分校彼得·阿布比尔研究组的Caffe,加拿大蒙特利尔大学的Theano,日本Preferred Networks公司的Chainer,以及谷歌的Tensor Flow等。这些开源软件的出现使得研究深度学习的人数迅速增加。
2015年,德国图宾根大学的马蒂亚斯·贝特格团队成功地让神经网络学会捕捉艺术风格,然后再将此风格应用到图片中去。
2009年,加拿大阿尔伯塔大学研发的Fuego Go战胜了中国台湾棋王周俊勋

2016年,丰田公司向外界展示了一种能自我学习的汽车,这是AlphaGo以外深度强化学习实际应用的再一次尝试:设置好必须严格遵守的交通规则,让很多汽车在路上随意驰骋,过不了多久,这些汽车就能自学掌握驾驶本领。
据Tractica估计,目前占280亿美元市场份额的机器人产业中,大部分是工业机器人——用于生产线的机器人,完全跟智能不沾边。这些机器人永远不会在大街上挺进,攻克华盛顿或巴黎。它们的智能水平(和移动能力)就像你家的洗衣机一样。
柳树车库(Willow Garage),于2006年由谷歌早期的设计师斯科特·哈桑(Scott Hassan)创立。它可能是近十年来最有影响力的机器人实验室。2007年,柳树车库在斯坦福研发出机器人操作系统(Robot Operating System,ROS)并使之得到普及;2010年,他们制造了PR2机器人。ROS和PR2构建了一个规模庞大的机器人开发者的开源社区,极大地促进了新型机器人设计的发展。
2001年,尼古拉斯·汉森(Nikolaus Hansen)推出名为“协方差矩阵适应”(Covariance Matrix Adaptation,CMA)的演进策略理论,主要对非线性问题做数值优化。
目前,在全世界的医院中,大约有超过3000个达·芬奇机器人。从2000年桑尼维尔的Intuitive Surgical公司被允许在医院配置机器人设备开始,这些机器人已参与近200万例外科手术。
2016年,在位于华盛顿的国家儿童健康系统部门(Children’s National Health System)工作的彼得·金(Peter Kim)推出了一款机器人外科医生——智能组织自动机器人(Smart Tissue Autonomous Robot,STAR),它能够单独执行大部分的手术操作任务(不过所用时间大约为人类外科医生的十倍)。
最先进的机器人是飞机。人们很少会把飞机看做机器人,但它是货真价实的机器人:它能自主完成从起飞到降落的大部分动作。
根据2015年波音777的飞行员调查报告显示,在正常飞行过程中,飞行员真正需要手动操纵飞机的时间仅有7分钟,而飞行员操控空中客车飞机的时间则还会再少一半。
雷蒙德·索洛莫诺夫(Ray Solomonoff)提出用于机器学习的“归纳推理机器”(An Inductive Inference Machine)。归纳法就是那种让我们能够举一反三的学习方法。他的方法中借鉴了贝叶斯推理理论,例如,在机器学习中引入概率理论。
在完善英戈·雷兴贝格(Ingo Rechenberg)的“进化策略”(Evolution Strategies,1971)理论的基础上,约翰·霍兰德(John Holland)在1975年提出了著名的“遗传算法”(genetic algorithms)理论,这是一种不同的程序设计方式,软件的生成与生物进化规则相当:不是依靠单纯的编写解决问题的程序,而是让一组程序通过自身的演化(根据某些算法)而变得更“合适”(更有效地发现解决问题的方法)。
1976年,理查德·莱恩(Richard Laing)发表了《通过自我检测实现复制的机器人模型》(Automaton Models of Reproduction by Self-inspection),提出了通过自我检测实现自我复制的理论范式。
27年后,约翰·霍普金斯大学的伽克里特·苏哈克恩(Jackrit Suthakorn)和克莱戈里(Gregory Chirikjian)采用这个理论制造出了一个能基本自我复制的机器人
自1979年以来,科德尔·格林(Cordell Green)一直尝试通过自动编程机制实现原本由软件工程师人工完成的软件编写工作。
在我看来,科研和工程在一定程度上,所需要的思维是极不相同的,他们甚至可以说是水火不相容的。
1956年,在一次著名的人工智能会议上,有人提出了第三种人工智能领域研究方法。雷蒙德·索洛莫诺夫(Ray Solomonoff)提出用于机器学习的“归纳推理机器”(An Inductive Inference Machine)。归纳法就是那种让我们能够举一反三的学习方法。他的方法中借鉴了贝叶斯推理理论,例如,在机器学习中引入概率理论。然而,索洛莫诺夫的归纳推理方法却是不可计算的,尽管其中的一些近似计算可以在计算机上运行。
的问题是能否编写一个可以帮助所有人解决所有数学问题的程序:只要运行程序,任何数学命题都能迎刃而解。1931年,库尔特·哥德尔(Kurt Goedel)证明了这个计划不严密,正式回应了希尔伯特提出的挑战。他的结论是:“那样的程序不可能存在,因为至少有一个命题我们无法证明其真伪。”
在1936年,阿兰·图灵则提出了自己的解决方案(即现在熟知的通用图灵机),从而使我们的技术无限接近于希尔伯特梦想中的程序。
是否这些计算机设备具有“智能”。例如,它们是否表现得像真正的人类(通过图灵测试),是否具有意识,甚至超越其创造者的智能水平(奇点)。 机器就像是一出生就成年的人,这等于你一出生就已经25岁了,而且永不衰老,除非某个器官停止工作。关于人类智能的一个基本事实就是智能来源于人类的童年时代。只有经历童年,人类才会成长为具备书写(或阅读)文字能力的人。其实,人类身体的生理发育与其思维的认知发育并行。发展心理学家艾莉森·高普尼克(Alison Gopnik)在其著作《宝宝也是哲学家》(The Philosophical Baby,2009)中指出,儿童与成年人的大脑大相径庭(尤其是前额叶皮层)。她甚至断言,儿童和成年人是两种截然不同的智人类型。他们从身体层面上行使着不同的功能。若抛开形成期,是否能创造与人类智能相当的“智能”还是一个很大的未知数。
机器就像是一出生就成年的人,这等于你一出生就已经25岁了,而且永不衰老,除非某个器官停止工作。关于人类智能的一个基本事实就是智能来源于人类的童年时代。只有经历童年,人类才会成长为具备书写(或阅读)文字能力的人。其实,人类身体的生理发育与其思维的认知发育并行。发展心理学家艾莉森·高普尼克(Alison Gopnik)在其著作《宝宝也是哲学家》(The Philosophical Baby,2009)中指出,儿童与成年人的大脑大相径庭(尤其是前额叶皮层)。她甚至断言,儿童和成年人是两种截然不同的智人类型。他们从身体层面上行使着不同的功能。若抛开形成期,是否能创造与人类智能相当的“智能”还是一个很大的未知数。
艾莉森·高普尼克强调儿童通过“反事实”(假设分析)的过程认识物质世界和社交世界:他们在了解了(生理和心理)世界的运行方式以后,首先会进行虚构(想象的世界与想象的朋友),然后他们了解事物的真实面貌(与世界的互动改变了他们原来的假想,与人的互动改变他们的思维)。当经历儿童阶段时,人类会学会按照世界和其他人设定的规则“智能地”行事。与人类的其他方面很类似,这个运行机制并不健全。例如,我们都曾学会说谎:我们说谎一般是为了改变周围人的想法。以前一位同事曾跟我说:“机器从不说谎。”这就是我认为科学在短时间内还无法创造出智能机器的原因。在所有符合“智能”定义的事情中,说谎是我们从小就学会的事情,还有许多其他事情也是如此。

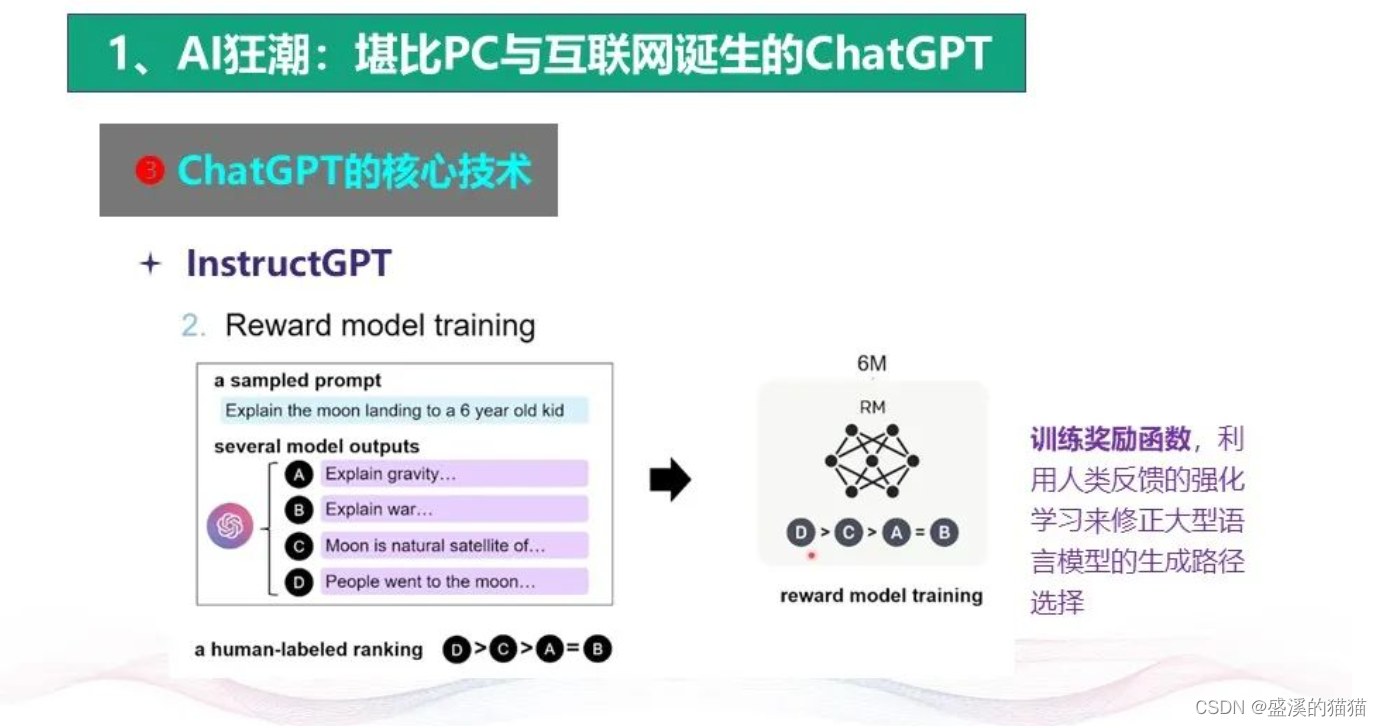
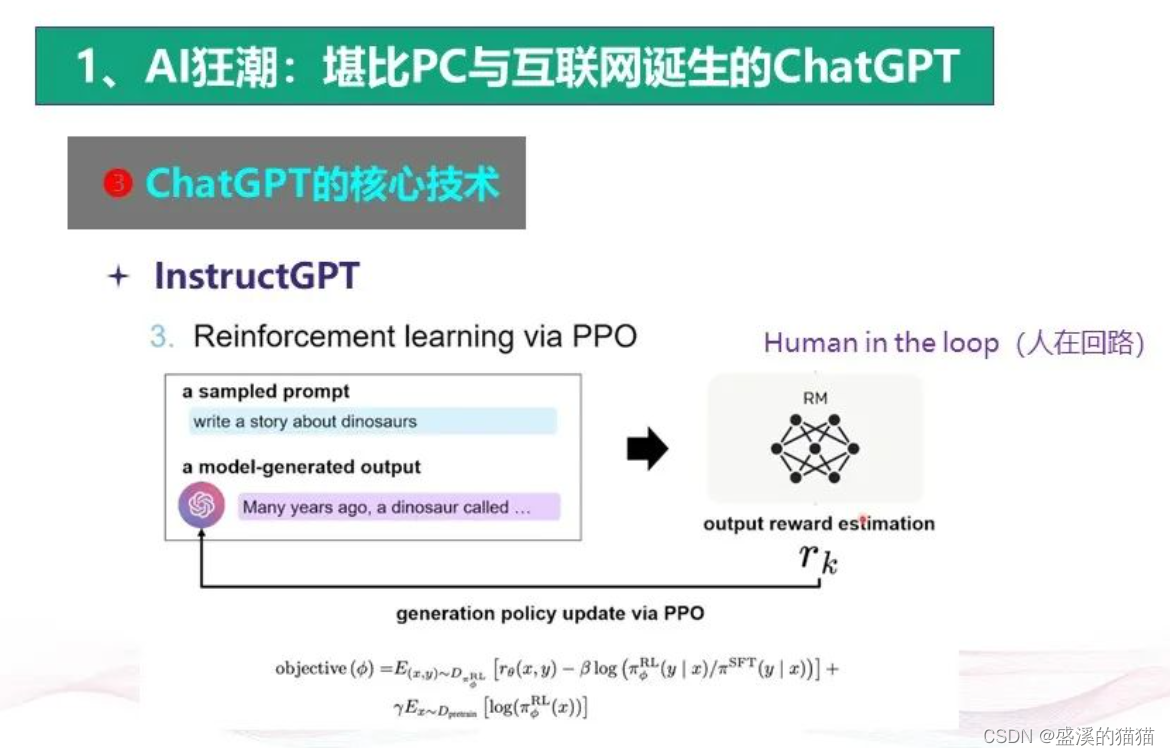



现在“深度学习”人工智能领域的研究内容很简单,就是罗列大量的数字进行运算。
这是一种很聪明的大数据集的处理方法,由此可以为数据集分类。但这种方法无需通过颠覆性模式创新来实现,只要提高计算能力即可。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结