您现在的位置是:首页 >技术交流 >利用具有局部信息的引导自注意进行息肉分割网站首页技术交流
利用具有局部信息的引导自注意进行息肉分割
文章目录
Using Guided Self-Attention with Local Information for Polyp Segmentation
摘要
背景
自动准确的息肉分割对于癌症的早期诊断至关重要。现有的息肉分割方法大多基于卷积神经网络,通常利用全局特征通过精心设计的模块来增强局部特征,从而处理息肉的多样性。尽管基于CNN的方法取得了令人印象深刻的结果,但它们无力对显式的长期关系进行建模,这限制了它们的性能。与CNN不同的是,由于自注意力,Transformer具有很强的远程关系建模能力。然而,自注意力总是将注意力分散到意想不到的区域,并且Transformer的局部特征提取能力不足,导致定位不准确和边界模糊。为了解决这些问题,我们提出了用于精确息肉分割的PPFormer。
方法
- 首先采用浅层CNN编码器和深层Transformer编码器来提取丰富的特征
- 在解码器中,我们提出了PP引导的自注意力,该自注意使用预测图来引导自注意聚焦于硬区域,以增强模型对息肉边界的感知。
- 局部到全局机制旨在鼓励Transformer在局部窗口中捕获更多信息,以更好地定位息肉。

(a) 是输入图像,感兴趣的像素用“+”标记
(b) 是标签
(c) 显示了通过PPguided自我注意力学习到的注意力图
(d) 展示了原生自我注意力学习到的注意力图
本文方法
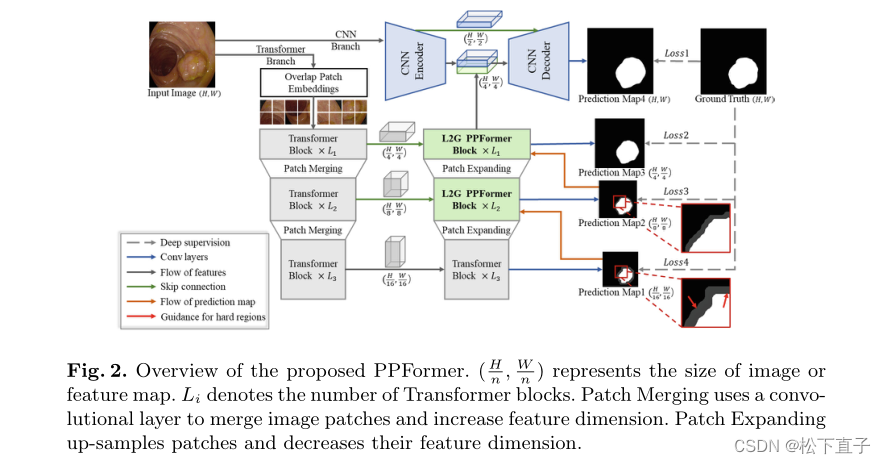
总体而言,PPFormer是一种编码器-解码器架构,可生成不同级别的预测图。
PPFormer的编码器由两个并行分支组成:
(1)用于全局特征提取的Transformer编码器。我们采用卷积视觉转换器(CvT)来构建转换器编码器。由于CvT删除了位置编码,我们的模型支持各种大小的输入图像。
(2) CNN编码器用于获得更多的低级别特征,以实现更好的像素级分割。我们采用VGG-16的前两个块来构建它。
PPFormer的解码器包括两个阶段:
(1)在第一阶段,模型预测具有高级特征的粗略结果,并使用预测图来引导L2G PPFormer块中的自我注意
(2) 在第二阶段,应用来自CNN编码器的低级别特征来细化分割结果。
PP-Guided Self-Attention
使用高级特征来生成低分辨率的预测图(现在不使用sigmoid函数)。patch级分割结果对每个图像patch进行评分,绝对值得分高表示斑块可能属于前景(息肉)或背景。
相反,低分数表明patch的属性很难确定,这经常发生在息肉的边界上。因此,提出了引导注意力矩阵MGA来引导这些patch:
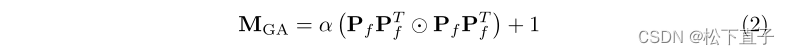
Pf调整大小并展平预测图,MGA重点关注不确定区域,并要求它们与高核心斑块而不是其他不确定区域建立关系,以确定其归属。然后,我们融合MGA和MSA来计算PP引导的自我注意:
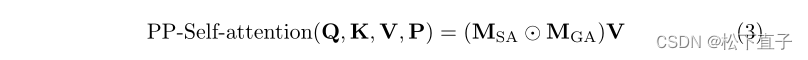
与普通的自我注意相比,PP引导的自我注意利用预测图作为引导信息,使模型聚焦于硬区域
Local-to-Global Mechanism
为了降低内存和计算复杂度,CvT采用压缩卷积投影来获得k和v。然而,由于局部信息的丢失,它们不适合在解码器中使用。因此,我们设计了L2G机制,以低内存使用率在局部窗口中捕获更多信息
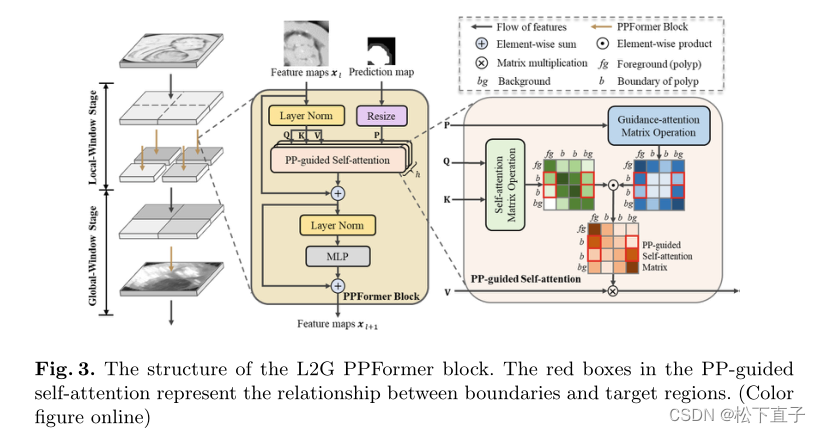
图3说明了L2G PPFormer块中的L2G机制,该块由局部窗口阶段和全局窗口阶段组成。在前一阶段,我们将输入特征图x∈RH×W×C拆分为s×s个非重叠窗口:x→ {x1,x2,…,xs×s},其中每个窗口的大小为H s×W s×C,s是全局窗口阶段的压缩卷积投影的步长。接下来,我们在每个局部窗口中独立执行PPFormer块。重要的是,我们在局部窗口阶段使用步长为1的卷积投影,以保留更多的局部特征,从而更好地定位息肉。在全局窗口阶段,另一个PPFormer块用于对长期关系进行建模。
损失函数
PFormer通过加权IoU损失和二进制交叉熵(BCE)损失进行端到端训练
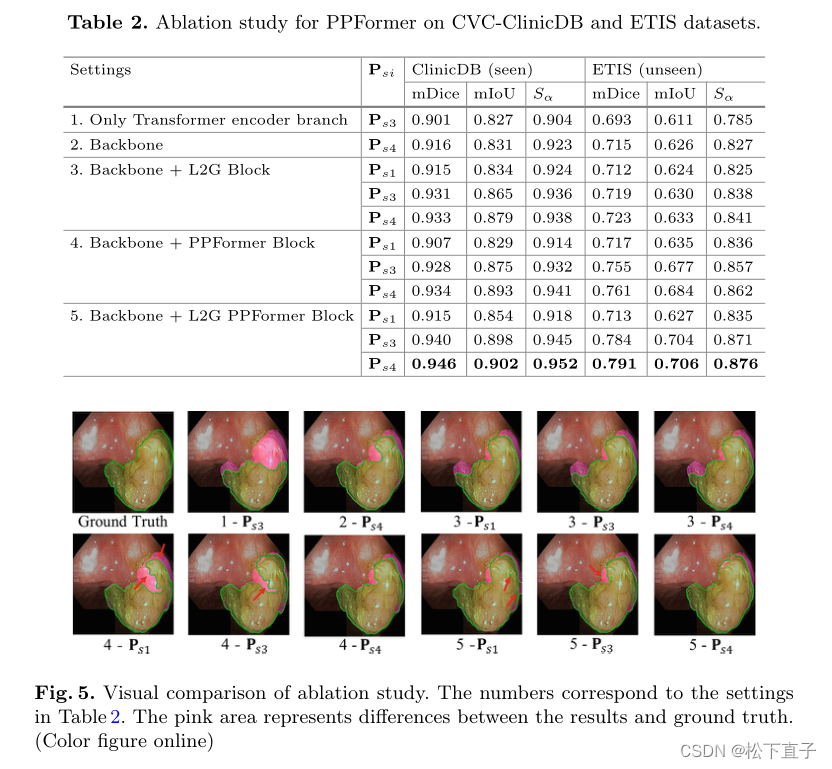
实验结果






站长推荐
- U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结