您现在的位置是:首页 >学无止境 >基于卷积的图像分类识别(三):VGGNet网站首页学无止境
基于卷积的图像分类识别(三):VGGNet
系列文章目录
本专栏介绍基于深度学习进行图像识别的经典和前沿模型,将持续更新,包括不仅限于:AlexNet, ZFNet,VGG,GoogLeNet,ResNet,DenseNet,SENet,MobileNet,ShuffleNet,EifficientNet,Vision Transformer,Swin Transformer,Visual Attention Network,ConvNeXt, MLP-Mixer,As-MLP,ConvMixer,MetaFormer
前言
2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员Karen Simonyan和Andrew Zisserman研发出了新的深度卷积神经网络:VGGNet,并在ILSVRC2014比赛分类项目中取得了第二名的好成绩(第一名是同年提出的GoogLeNet模型),同时在定位项目中获得第一名。
VGGNet模型通过探索卷积神经网络的深度与性能之间的关系,成功构建了16~19层深的卷积神经网络,并证明了增加网络深度可以在一定程度上提高网络性能,大幅降低错误率。此外,VGGNet具有很强的拓展性和泛化性,适用于其他类型的图像数据。至今,VGGNet仍然被广泛应用于图像特征提取。
VGGNet可以看成是加深版本的AlexNet,都是由卷积层、全连接层两大部分构成。
论文名称:Very deep convolutional networks for large-scale image recognition
论文下载链接:https://arxiv.org/pdf/1409.1556.pdf%E3%80%82
pytorch代码实现:https://github.com/Arwin-Yu/Deep-Learning-Classification-Models-Based-CNN-or-Attention
一、Vgg网络模型
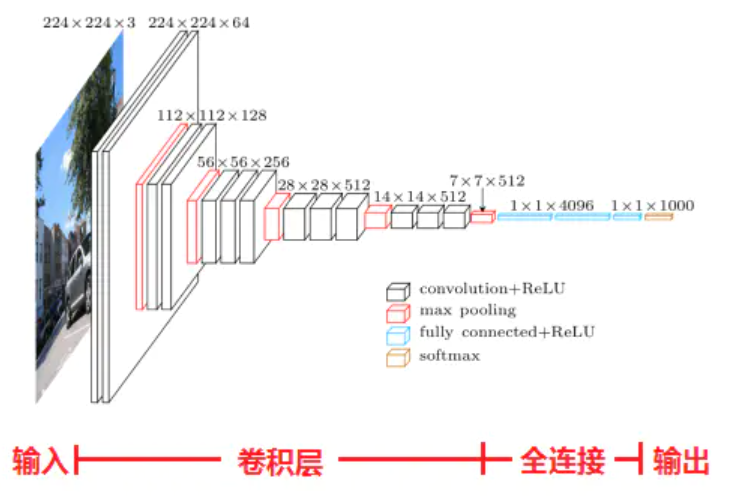
如上图所示是经典的Vgg16网络模型:
- 模型接收的输入是彩色图像,数据存储的形状为(B, C, H, W) 分别代表(图像数量,图片色彩通道,图片高度,图片宽度)以上图实例中为(1,3,224,224)
- 模型的特征提取阶段是不断重复堆叠卷积层和池化层实现的,一共经过5次下采样(图中红颜色的层结构),下采样方式为最大池化。注意:通过调整步长(strdie)和填充(padding),网络中的所有卷积操作都没有改变输入特征图的尺寸。
- 在最后的顶层设计中,经过三个全连接层实现对图片的分类操作。注意:由于全连接层的存在, 网络只能接收固定大小的图像尺寸。
二、网络贡献总结
1、结构简洁
VGG模型中,所有卷积层的卷积核大小,步长和填充都相同,并且通过使用最大化池对卷积层进行分层。所有隐藏层的激活单元都采用ReLU函数。在最后的顶层设计中,通过三层全连接层和Softmax输出层实现对图像的分类操作。由于其极简且清晰的结构,直到今天VGG也依然被很多工作用于图像的特征提取器,正所谓:大道至简。
2、小卷积核
VGGNet中所有的卷积层都使用了小卷积核(3×3)。这种设计有两个优点:一方面,可以大幅减少参数量;另一方面,节省下来的参数可以用于堆叠更多的卷积层,进一步增加了网络的深度和非线性映射能力,从而提高了网络的表达和特征提取能力。
小卷积核是VGG的一个重要特点,虽然VGG是在模仿AlexNet的网络结构,但并没有采用AlexNet中比较大的卷积核尺寸(如7×7),而是通过降低卷积核的大小(3×3),增加卷积子层数来达到同样的性能。
VGG模型中,指出两个3×3的卷积堆叠获得的感受野大小,相当于一个5×5的卷积;而3个3×3卷积的堆叠获取到的感受野相当于一个7×7的卷积。这样可以增加非线性映射,也能很好地减少参数(例如7×7的参数为49个,而3个3×3的参数为27)。
卷积计算结果尺寸(卷积后特征图的size)的计算方式如下。
输入的特征图尺寸为
i
mathrm{i}
i, 卷积核的尺寸为
k
k
k, 步长 (Stride) 为
s
s
s, 填充 (Padding) 为
p
p
p, 则输出的特 征图的尺寸
O
O
O 为。
o
=
⌊
i
+
2
p
−
k
2
⌋
+
1
o=leftlfloorfrac{i+2 p-k}{2}
ight
floor+1
o=⌊2i+2p−k⌋+1
假设特征图是
28
×
28
28 imes 28
28×28 的, 假设卷记的步长step
=
1
=1
=1, padding
=
0
=0
=0 。
- 使用一层 5 × 5 5 imes 5 5×5 卷积核, 由 ( 28 − 5 ) / 1 + 1 = 24 (28-5) / 1+1=24 (28−5)/1+1=24 可得, 输出的特征图尺寸为 24 × 24 24 imes 24 24×24 。
- 使用两层 3 × 3 3 imes 3 3×3 卷积核。
- 第一层, 由 ( 28 − 3 ) / 1 + 1 = 26 (28-3) / 1+1=26 (28−3)/1+1=26 可得, 输出的特征图尺寸为 26 × 26 26 imes 26 26×26 。
- 第二层, 由
(
26
−
3
)
/
1
+
1
=
24
(26-3) / 1+1=24
(26−3)/1+1=24 可得, 输出的特征图尺寸为
24
×
24
24 imes 24
24×24 。
可以看到最终结果两者相同, 即两个 3 × 3 3 imes 3 3×3 的卷积堆叠获得的感受野大小, 相当于一个 5 × 5 5 imes 5 5×5 的卷积。
3、小池化核
相比AlexNet的3x3的池化核,VGG全部采用2x2的池化核。
4、通道数多
VGG网络第一层的通道数为64,后面每层都进行了翻倍,最多到512个通道。相比较于AlexNet和ZFNet最多得到的通道数是256,VGG 的通道数的进行了翻倍,使得更多的信息可以被卷积操作提取出来。
5、层数更深、特征图更多
网络中,卷积层专注于扩大feature maps的通道数、池化层专注于缩小feature maps的宽和高,使得模型架构上更深更宽的同时,控制了计算量的增加规模。
三、 代码实现
这里给出模型搭建的python代码(基于pytorch实现)。完整的代码是基于图像分类问题的(包括训练和推理脚本,自定义层等)详见我的GitHub:完整代码链接
import torch.nn as nn
import torch
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
# vgg_tiny(VGG11), vgg_small(VGG13), vgg(VGG16), vgg_big(VGG19)
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg11(num_classes):
cfg = cfgs["vgg11"]
model = VGG(make_features(cfg), num_classes=num_classes)
return model
def vgg13(num_classes):
cfg = cfgs["vgg13"]
model = VGG(make_features(cfg), num_classes=num_classes)
return model
def vgg16(num_classes):
cfg = cfgs["vgg16"]
model = VGG(make_features(cfg), num_classes=num_classes)
return model
def vgg19(num_classes):
cfg = cfgs['vgg19']
model = VGG(make_features(cfg), num_classes=num_classes)
return model
总结
VGG是于2014年提出的经典卷积神经网络模型。VGG网络结构简单而规整,由一系列重复的卷积块(Conv Block)和池化块(Pool Block)构成。每个卷积块包含若干个卷积层和激活函数,每个池化块则包含一个池化层。所有的卷积层和池化层都使用相同的卷积核尺寸和步长,从而使得网络结构规整。
此外,VGGNet采用了较小的卷积核尺寸(通常为3×3),这样可以减少模型参数数量,并且通过堆叠多层卷积层来增加模型的深度,从而提高模型的表达能力和分类准确率。在池化层中,VGGNet使用最大池化(Max Pooling)来减少特征图的大小。
VGGNet有多个版本,包括VGG-16、VGG-19等。其中VGG-16包含16个卷积层和3个全连接层,其中VGG-19包含19个卷积层和3个全连接层。这些版本的VGGNet都在ImageNet图像分类竞赛中取得了优异的成绩,并成为了图像分类任务中的经典模型之一。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结