您现在的位置是:首页 >学无止境 >MySQL CRUD (带样例)网站首页学无止境
MySQL CRUD (带样例)
简介MySQL CRUD (带样例)
目录
C语言总结 在这 常见八大排序 在这
作者和朋友建立的社区: 非科班转码社区-CSDN社区云 ? ? ?
期待hxd的支持哈 ? ? ?
最后是打鸡血环节: 少年不该止步于此 ? ? ?
最近作者和好友建立了一个公众号
公众号介绍:
专注于自学编程领域。由USTC、WHU、SDU等高校学生、ACM竞赛选手、CSDN万粉博主、双非上岸BAT学长原创。分享业内资讯、硬核原创资源、职业规划等,和大家一起努力、成长。( 二维码在文章底部哈! )
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
CRUD 只是一个统称,并不是说操作就是对应哲学命令。
1. Create(创建)
语法
INSERT [ INTO ] table_name[( column [, column ] ...)]VALUES (value_list) [, (value_list)] ...value_list: value , [, value ] ...案例
-- 创建一张学生表CREATE TABLE students (id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT ,sn INT NOT NULL UNIQUE COMMENT ' 学号 ' ,name VARCHAR ( 20 ) NOT NULL ,qq VARCHAR ( 20 ));1.1 单行数据 + 全列插入
-- 插入两条记录, value_list 数量必须和定义表的列的数量及顺序一致-- 注意,这里在插入的时候,也可以不用指定 id( 当然,那时候就需要明确插入数据到那些列了 ) ,那么 mysql 会使用默认的值进行自增。INSERT INTO students VALUES ( 100 , 10000 , ' 唐三藏 ' , NULL );Query OK, 1 row affected ( 0.02 sec)INSERT INTO students VALUES ( 101 , 10001 , ' 孙悟空 ' , '11111' );Query OK, 1 row affected ( 0.02 sec)-- 查看插入结果SELECT * FROM students;+-----+-------+-----------+-------+| id | sn | name | qq |+-----+-------+-----------+-------+| 100 | 10000 | 唐三藏 | NULL || 101 | 10001 | 孙悟空 | 11111 |+-----+-------+-----------+-------+2 rows in set ( 0.00 sec)1.2 多行数据 + 指定列插入
-- 插入两条记录, value_list 数量必须和指定列数量及顺序一致INSERT INTO students (id, sn, name) VALUES( 102 , 20001 , ' 曹孟德 ' ),( 103 , 20002 , ' 孙仲谋 ' );Query OK, 2 rows affected ( 0.02 sec)Records: 2 Duplicates: 0 Warnings : 0-- 查看插入结果SELECT * FROM students;+-----+-------+-----------+-------+| id | sn | name | qq |+-----+-------+-----------+-------+| 100 | 10000 | 唐三藏 | NULL || 101 | 10001 | 孙悟空 | 11111 || 102 | 20001 | 曹孟德 | NULL || 103 | 20002 | 孙仲谋 | NULL |+-----+-------+-----------+-------+4 rows in set ( 0.00 sec)1.3 插入否则更新
由于 主键 或者 唯一键 对应的值已经存在而导致插入失败-- 主键冲突INSERT INTO students (id, sn, name) VALUES ( 100 , 10010 , ' 唐大师 ' );ERROR 1062 ( 23000 ): Duplicate entry '100' for key 'PRIMARY'-- 唯一键冲突INSERT INTO students (sn, name) VALUES ( 20001 , ' 曹阿瞒 ' );ERROR 1062 ( 23000 ): Duplicate entry '20001' for key 'sn'可以选择性的进行同步更新操作 语法:INSERT ... ON DUPLICATE KEY UPDATEcolumn = value [, column = value ] ...INSERT INTO students (id, sn, name) VALUES ( 100 , 10010 , ' 唐大师 ' )ON DUPLICATE KEY UPDATE sn = 10010 , name = ' 唐大师 ' ;Query OK, 2 rows affected ( 0.47 sec)-- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等-- 1 row affected: 表中没有冲突数据,数据被插入-- 2 row affected: 表中有冲突数据,并且数据已经被更新-- 通过 MySQL 函数获取受到影响的数据行数SELECT ROW_COUNT();+-------------+| ROW_COUNT() |+-------------+| 2 |+-------------+1 row in set ( 0.00 sec)-- ON DUPLICATE KEY 当发生重复 key 的时候1.4 替换
-- 主键 或者 唯一键 没有冲突,则直接插入;-- 主键 或者 唯一键 如果冲突,则删除后再插入REPLACE INTO students (sn, name) VALUES ( 20001 , ' 曹阿瞒 ' );Query OK, 2 rows affected ( 0.00 sec)-- 1 row affected: 表中没有冲突数据,数据被插入-- 2 row affected: 表中有冲突数据,删除后重新插入2. Retrieve(读取)
语法:SELECT[DISTINCT] {* | {column [, column] ...}[FROM table_name][WHERE ...][ORDER BY column [ASC | DESC], ...]LIMIT ...案例:-- 创建表结构CREATE TABLE exam_result (id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,name VARCHAR(20) NOT NULL COMMENT ' 同学姓名 ',chinese float DEFAULT 0.0 COMMENT ' 语文成绩 ',math float DEFAULT 0.0 COMMENT ' 数学成绩 ',english float DEFAULT 0.0 COMMENT ' 英语成绩 ');-- 插入测试数据INSERT INTO exam_result (name, chinese, math, english) VALUES(' 唐三藏 ', 67, 98, 56),(' 孙悟空 ', 87, 78, 77),(' 猪悟能 ', 88, 98, 90),(' 曹孟德 ', 82, 84, 67),(' 刘玄德 ', 55, 85, 45),(' 孙权 ', 70, 73, 78),(' 宋公明 ', 75, 65, 30);Query OK, 7 rows affected (0.00 sec)Records: 7 Duplicates: 0 Warnings: 02.1 SELECT 列
全列查询
-- 通常情况下不建议使用 * 进行全列查询-- 1. 查询的列越多,意味着需要传输的数据量越大;-- 2. 可能会影响到索引的使用。(索引待后面课程讲解)SELECT * FROM exam_result;+----+-----------+-------+--------+--------+| id | name | chinese | math | english |+----+-----------+-------+--------+--------+| 1 | 唐三藏 | 67 | 98 | 56 || 2 | 孙悟空 | 87 | 78 | 77 || 3 | 猪悟能 | 88 | 98 | 90 || 4 | 曹孟德 | 82 | 84 | 67 || 5 | 刘玄德 | 55 | 85 | 45 || 6 | 孙权 | 70 | 73 | 78 || 7 | 宋公明 | 75 | 65 | 30 |+----+-----------+-------+--------+--------+7 rows in set (0.00 sec)指定列查询
-- 指定列的顺序不需要按定义表的顺序来SELECT id, name, english FROM exam_result;+----+-----------+--------+| id | name | english |+----+-----------+--------+| 1 | 唐三藏 | 56 || 2 | 孙悟空 | 77 || 3 | 猪悟能 | 90 || 4 | 曹孟德 | 67 || 5 | 刘玄德 | 45 || 6 | 孙权 | 78 || 7 | 宋公明 | 30 |+----+-----------+--------+7 rows in set (0.00 sec)查询字段为表达式
-- 表达式不包含字段SELECT id, name, 10 FROM exam_result;+----+-----------+----+| id | name | 10 |+----+-----------+----+| 1 | 唐三藏 | 10 || 2 | 孙悟空 | 10 || 3 | 猪悟能 | 10 || 4 | 曹孟德 | 10 || 5 | 刘玄德 | 10 || 6 | 孙权 | 10 || 7 | 宋公明 | 10 |+----+-----------+----+7 rows in set (0.00 sec)-- 表达式包含(1个/)多个字段SELECT id, name, chinese + math + english FROM exam_result;+----+-----------+-------------------------+| id | name | chinese + math + english |+----+-----------+-------------------------+| 1 | 唐三藏 | 221 || 2 | 孙悟空 | 242 || 3 | 猪悟能 | 276 || 4 | 曹孟德 | 233 || 5 | 刘玄德 | 185 || 6 | 孙权 | 221 || 7 | 宋公明 | 170 |+----+-----------+-------------------------+7 rows in set (0.00 sec)为查询结果指定别名
语法:
SELECT column [AS] alias_name [...] FROM table_name;SELECT id, name, chinese + math + english 总分 FROM exam_result;+----+-----------+--------+| id | name | 总分 |+----+-----------+--------+| 1 | 唐三藏 | 221 || 2 | 孙悟空 | 242 || 3 | 猪悟能 | 276 || 4 | 曹孟德 | 233 || 5 | 刘玄德 | 185 || 6 | 孙权 | 221 || 7 | 宋公明 | 170 |+----+-----------+--------+7 rows in set (0.00 sec)结果去重 DISTINCT
SELECT DISTINCT math FROM exam_result;+--------+| math |+--------+| 98 || 78 || 84 || 85 || 73 || 65 |+--------+6 rows in set (0.00 sec)2.2 WHERE 条件
比较运算符:
案例:
英语不及格的同学及英语成绩 ( < 60 )SELECT name, english FROM exam_result WHERE english < 60;语文成绩在 [80, 90] 分的同学及语文成绩-- 使用 AND 进行条件连接SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese <= 90;-- 使用 BETWEEN ... AND ... 条件SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90;数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99);姓孙的同学 及 孙某同学SELECT name FROM exam_result WHERE name LIKE ' 孙 %';总分在 200 分以下的同学SELECT name, chinese + math + english 总分 FROM exam_resultWHERE chinese + math + english < 200;语文成绩 > 80 并且不姓孙的同学ELECT name, chinese FROM exam_resultWHERE chinese > 80 AND name NOT LIKE ' 孙 %';孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80SELECT name, chinese, math, english, chinese + math + english 总分FROM exam_resultWHERE name LIKE ' 孙 _' OR (chinese + math + english > 200 AND chinese < math AND english > 80);NULL 的查询
-- 查询 students 表+-----+-------+-----------+-------+| id | sn | name | qq |+-----+-------+-----------+-------+| 100 | 10010 | 唐大师 | NULL || 101 | 10001 | 孙悟空 | 11111 || 103 | 20002 | 孙仲谋 | NULL || 104 | 20001 | 曹阿瞒 | NULL |+-----+-------+-----------+-------+4 rows in set (0.00 sec)-- 查询 qq 号已知的同学姓名SELECT name, qq FROM students WHERE qq IS NOT NULL;+-----------+-------+| name | qq |+-----------+-------+| 孙悟空 | 11111 |+-----------+-------+1 row in set (0.00 sec)-- NULL 和 NULL 的比较,= 和 <=> 的区别SELECT NULL = NULL, NULL = 1, NULL = 0;+-------------+----------+----------+| NULL = NULL | NULL = 1 | NULL = 0 |+-------------+----------+----------+| NULL | NULL | NULL |+-------------+----------+----------+1 row in set (0.00 sec)SELECT NULL <=> NULL, NULL <=> 1, NULL <=> 0;+---------------+------------+------------+| NULL <=> NULL | NULL <=> 1 | NULL <=> 0 |+---------------+------------+------------+| 1 | 0 | 0 |+---------------+------------+------------+1 row in set (0.00 sec)(比较null要用 <> <=>)2.3 结果排序
语法
-- ASC 为升序(从小到大)-- DESC 为降序(从大到小)-- 默认为 ASCSELECT ... FROM table_name [WHERE ...]ORDER BY column [ASC|DESC], [...];注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序样例
同学及 qq 号,按 qq 号排序显示SELECT name, qq FROM students ORDER BY qq;查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示SELECT name, math, english, chinese FROM exam_resultORDER BY math DESC, english, chinese;查询同学及总分,由高到低SELECT name, chinese + english + math FROM exam_resultORDER BY chinese + english + math DESC;查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示SELECT name, math FROM exam_resultWHERE name LIKE ' 孙 %' OR name LIKE ' 曹 %'ORDER BY math DESC;2.4 筛选分页结果
语法
-- 起始下标为 0-- 从 0 开始,筛选 n 条结果SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;-- 从 s 开始,筛选 n 条结果SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;建议:对未知表进行查询时,最好加一条 LIMIT 1 ,避免因为表中数据过大,查询全表数据导致数据库卡死。样例按 id 进行分页,每页 3 条记录,分别显示 第 1 、 2 、 3 页-- 第 1 页SELECT id, name, math, english, chinese FROM exam_resultORDER BY id LIMIT 3 OFFSET 0;-- 第 2 页SELECT id, name, math, english, chinese FROM exam_resultORDER BY id LIMIT 3 OFFSET 3;-- 第 3 页,如果结果不足 3 个,不会有影响SELECT id, name, math, english, chinese FROM exam_resultORDER BY id LIMIT 3 OFFSET 6;3. Update(更新)
语法:
UPDATE table_name SET column = expr [, column = expr ...][WHERE ...] [ORDER BY ...] [LIMIT ...]对查询到的结果进行列值更新案例:将孙悟空同学的数学成绩变更为 80 分UPDATE exam_result SET math = 80 WHERE name = ' 孙悟空 ';将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分UPDATE exam_result SET math = 60, chinese = 70 WHERE name = ' 曹孟德 ';将总成绩倒数前三的 3 位同学的数学成绩加上 30 分SELECT name, math, chinese + math + english 总分 FROM exam_resultORDER BY 总分 LIMIT 3;UPDATE exam_result SET math = math + 30ORDER BY chinese + math + english LIMIT 3;将所有同学的语文成绩更新为原来的 2 倍UPDATE exam_result SET chinese = chinese * 2;4. Delete(删除)
4.1 删除数据
语法:DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]案例:删除孙悟空同学的考试成绩DELETE FROM exam_result WHERE name = ' 孙悟空 ';删除整张表数据注意:删除整表操作要慎用!DELETE FROM for_delete;4.2 截断表
TRUNCATE [TABLE] table_name //也就是删除表数据,类似重新创建一个完全的空表注意:这个操作慎用1. 只能对整表操作,不能像 DELETE 一样针对部分数据操作;2. 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是 TRUNCATE 在删除数据的时候,并不经过真正的事物,所以无法回滚。3. 会重置 AUTO_INCREMENT 项。4.3 插入查询结果
语法:INSERT INTO table_name [(column [, column ...])] SELECT ...案例:删除表中的的重复复记录,重复的数据只能有一份-- 创建原数据表CREATE TABLE duplicate_table (id int, name varchar(20));Query OK, 0 rows affected (0.01 sec)-- 插入测试数据INSERT INTO duplicate_table VALUES(100, 'aaa'),(100, 'aaa'),(200, 'bbb'),(200, 'bbb'),(200, 'bbb'),(300, 'ccc');Query OK, 6 rows affected (0.00 sec)Records: 6 Duplicates: 0 Warnings: 0思路:-- 创建一张空表 no_duplicate_table ,结构和 duplicate_table 一样CREATE TABLE no_duplicate_table LIKE duplicate_table;Query OK, 0 rows affected (0.00 sec)-- 将 duplicate_table 的去重数据插入到 no_duplicate_tableINSERT INTO no_duplicate_table SELECT DISTINCT * FROM duplicate_table;Query OK, 3 rows affected (0.00 sec)Records: 3 Duplicates: 0 Warnings: 0-- 通过重命名表,实现原子的去重操作RENAME TABLE duplicate_table TO old_duplicate_table,no_duplicate_table TO duplicate_table;Query OK, 0 rows affected (0.00 sec)-- 查看最终结果SELECT * FROM duplicate_table;+------+------+| id | name |+------+------+| 100 | aaa || 200 | bbb || 300 | ccc |+------+------+3 rows in set (0.00 sec)
5. 聚合函数
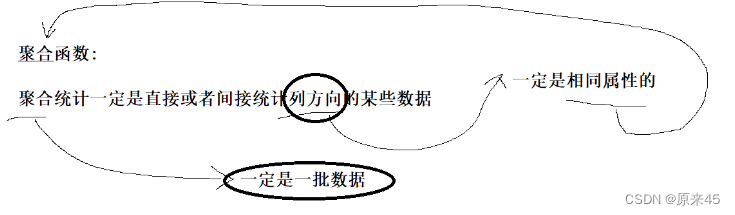 案例:统计班级共有多少同学-- 使用 * 做统计,不受 NULL 影响SELECT COUNT(*) FROM students;统计班级收集的 qq 号有多少-- NULL 不会计入结果SELECT COUNT(qq) FROM students;统计本次考试的数学成绩分数个数-- COUNT(math) 统计的是全部成绩SELECT COUNT(math) FROM exam_result;-- COUNT(DISTINCT math) 统计的是去重成绩数量SELECT COUNT(DISTINCT math) FROM exam_result;统计数学成绩总分SELECT SUM(math) FROM exam_result;-- 不及格 < 60 的总分,没有结果,返回 NULLSELECT SUM(math) FROM exam_result WHERE math < 60;统计平均总分SELECT AVG(chinese + math + english) 平均总分 FROM exam_result;返回英语最高分SELECT MAX(english) FROM exam_result;返回 > 70 分以上的数学最低分SELECT MIN(math) FROM exam_result WHERE math > 70;
案例:统计班级共有多少同学-- 使用 * 做统计,不受 NULL 影响SELECT COUNT(*) FROM students;统计班级收集的 qq 号有多少-- NULL 不会计入结果SELECT COUNT(qq) FROM students;统计本次考试的数学成绩分数个数-- COUNT(math) 统计的是全部成绩SELECT COUNT(math) FROM exam_result;-- COUNT(DISTINCT math) 统计的是去重成绩数量SELECT COUNT(DISTINCT math) FROM exam_result;统计数学成绩总分SELECT SUM(math) FROM exam_result;-- 不及格 < 60 的总分,没有结果,返回 NULLSELECT SUM(math) FROM exam_result WHERE math < 60;统计平均总分SELECT AVG(chinese + math + english) 平均总分 FROM exam_result;返回英语最高分SELECT MAX(english) FROM exam_result;返回 > 70 分以上的数学最低分SELECT MIN(math) FROM exam_result WHERE math > 70;group by子句的使用
在 select 中使用 group by 子句可以对指定列进行分组查询select column1, column2, .. from table group by column;案例:准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)EMP 员工表DEPT 部门表SALGRADE 工资等级表如何显示每个部门的平均工资和最高工资select deptno,avg(sal),max(sal) from EMP group by deptno;显示每个部门的每种岗位的平均工资和最低工资select avg(sal),min(sal),job, deptno from EMP group by deptno, job;显示平均工资低于2000的部门和它的平均工资统计各个部门的平均工资select avg(sal) from EMP group by deptno;having 和 group by 配合使用,对 group by 结果进行过滤select avg(sal) as myavg from EMP group by deptno having myavg<2000;--having 经常和 group by 搭配使用,作用是对分组进行筛选,作用有些像 where 。顺序总结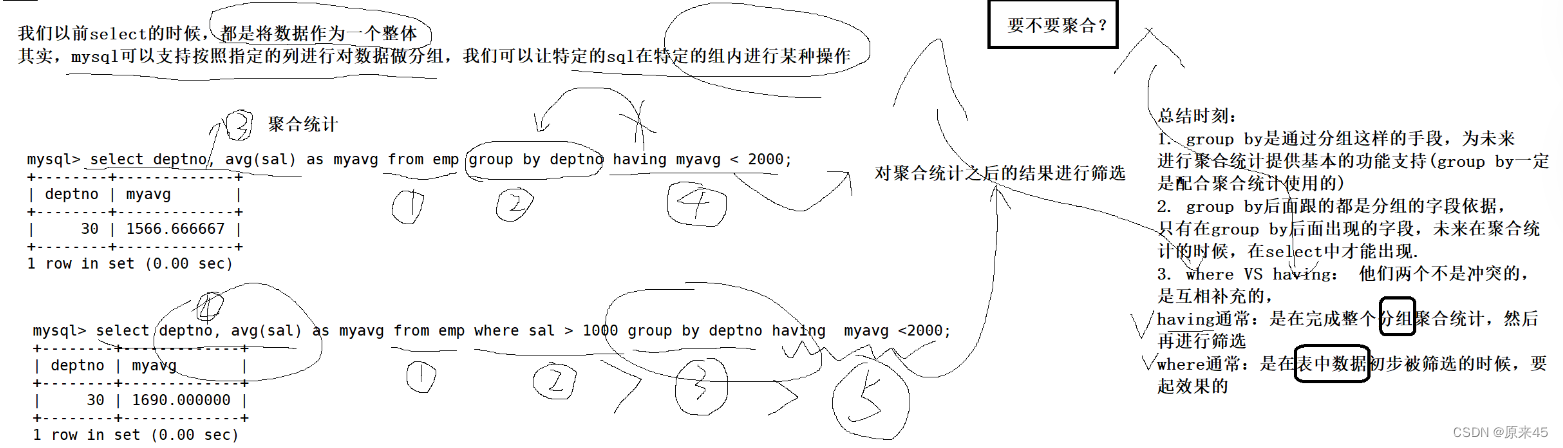
SQL查询中各个关键字的执行先后顺序
from > on> join > where > group by > with > having > select > distinct > order by > limit
最后的最后,创作不易,希望读者三连支持?
赠人玫瑰,手有余香?
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结