您现在的位置是:首页 >学无止境 >夜莺(Flashcat)V6监控(五):夜莺监控k8s组件(上)网站首页学无止境
夜莺(Flashcat)V6监控(五):夜莺监控k8s组件(上)
目录
(1)我们先创建一个namespace来专门做夜莺监控采集指标
(1)配置Prometheus-agent configmap配置文件
(2)配置kubelet的service和endpoints
(1)配置Prometheus-agent configmap配置文件
(3)更改kube-proxy的metricsbindAddress
这一期我们讲一下夜莺来监控k8s组件的监控,因为k8s的组件复杂,内容多,所以我们分成上下两部分来学习,这一期我们先学习监控k8s的几大组件。首先我们先来了解认识一下k8s的架构和监控概述
(一)Kubernetest监控体系
当我们谈及 Kubernetes 监控的时候,我们在谈论什么?显然是 Kubernetes 架构下的各个内容的监控,Kubernetes 所跑的环境、Kubernetes 本身、跑在 Kubernetes 上面的应用等等。Kubernetes 所跑的环境,可能是物理机、虚拟机,并且依赖底层的基础网络,Kubernetes 上面的应用,可能是业务应用程序,也可能是各类中间件、数据库,Kubernetes 本身,则包含很多组件,我们通过一张 Kubernetes 架构图来说明 。
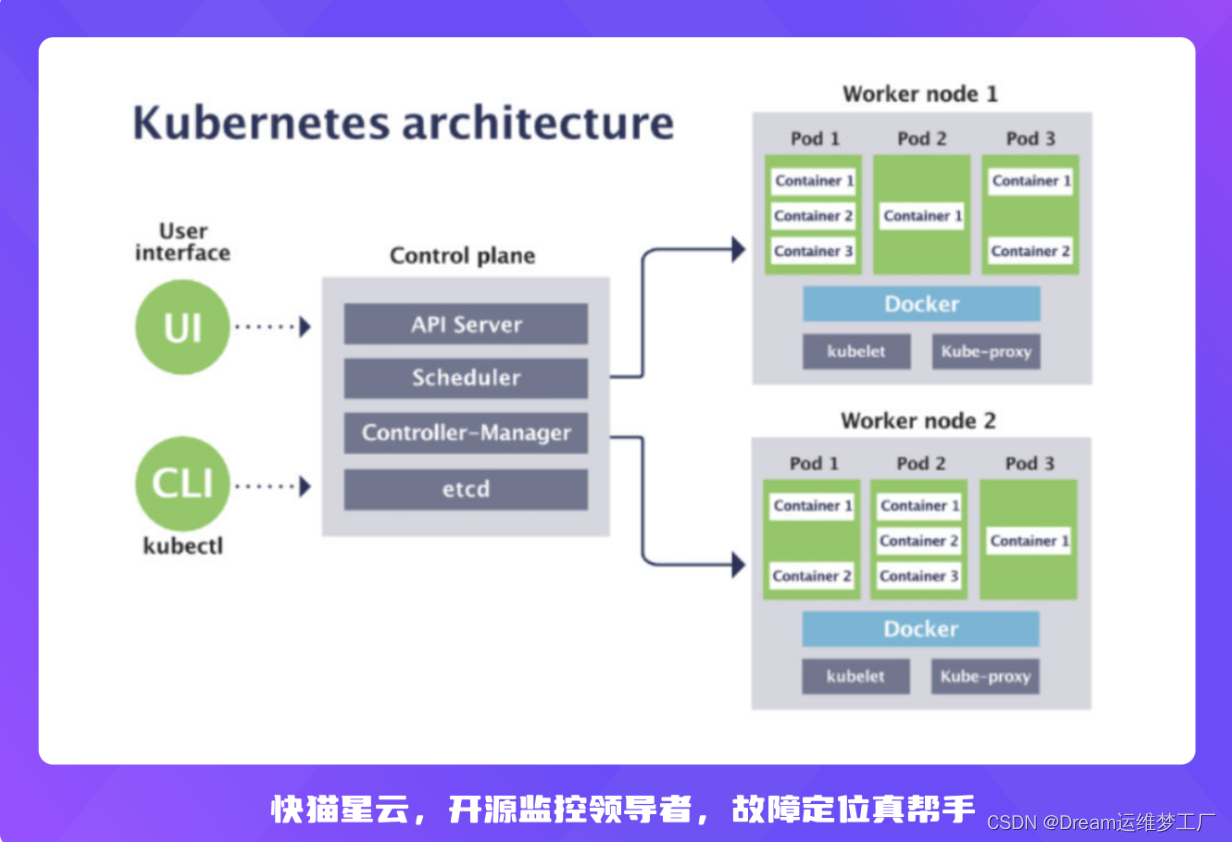
最左侧是 UI 层,包括页面 UI 以及命令行工具 kubectl,中间部分是 Kubernetes 控制面组件,右侧部分是工作负载节点,包含两个工作覆盖节点。
k8s的这个架构我们可以大致分为两个模块来理解:
1.Master组件
apiserver: 是Kubernetes集群中所有组件之间通信的中心组件,也是集群的前端接口。kube-apiserver负责验证和处理API请求,并将它们转发给其他组件。
scheduler: Kubernetes Scheduler负责在Kubernetes集群中选择最合适的Node来运行新创建的Pod,考虑到节点的资源利用率、Pod的调度限制、网络位置等因素。
controller-manager: Kubernetes Controller Manager包含多个控制器,负责监视并确保集群状态符合预期。例如,ReplicationController、NamespaceController、ServiceAccountController等等。
etcd:etcd是Kubernetes的后端数据库,用于存储和管理Kubernetes集群状态信息,例如Pod、Service、ConfigMap等对象的配置和状态信息。
2.Slave-node组件
kubelet:Kubelet是在每个Node上运行的代理服务,负责管理和监视该Node上的容器,并与kube-apiserver进行通信以保持节点状态最新。
kube-proxy:Kubernetes Proxy负责为容器提供网络代理和负载均衡功能,使得容器可以访问其他Pod、Service等网络资源。
Container Runtime:如Docker,rkt,runc等提供容器运行时环境
1.Kubernetes监控策略
Kubernetes作为开源的容器编排工具,为用户提供了一个可以统一调度,统一管理的云操作系统。其解决如用户应用程序如何运行的问题。而一旦在生产环境中大量基于Kubernetes部署和管理应用程序后,作为系统管理员,还需要充分了解应用程序以及Kubernetes集群服务运行质量如何,通过对应用以及集群运行状态数据的收集和分析,持续优化和改进,从而提供一个安全可靠的生产运行环境。 这一小节中我们将讨论当使用Kubernetes时的监控策略该如何设计。
从物理结构上讲Kubernetes主要用于整合和管理底层的基础设施资源,对外提供应用容器的自动化部署和管理能力,这些基础设施可能是物理机、虚拟机、云主机等等。因此,基础资源的使用直接影响当前集群的容量和应用的状态。在这部分,我们需要关注集群中各个节点的主机负载,CPU使用率、内存使用率、存储空间以及网络吞吐等监控指标。
从自身架构上讲,kube-apiserver是Kubernetes提供所有服务的入口,无论是外部的客户端还是集群内部的组件都直接与kube-apiserver进行通讯。因此,kube-apiserver的并发和吞吐量直接决定了集群性能的好坏。其次,对于外部用户而言,Kubernetes是否能够快速的完成pod的调度以及启动,是影响其使用体验的关键因素。而这个过程主要由kube-scheduler负责完成调度工作,而kubelet完成pod的创建和启动工作。因此在Kubernetes集群本身我们需要评价其自身的服务质量,主要关注在Kubernetes的API响应时间,以及Pod的启动时间等指标上。
Kubernetes的最终目标还是需要为业务服务,因此我们还需要能够监控应用容器的资源使用情况。对于内置了对Prometheus支持的应用程序,也要支持从这些应用程序中采集内部的监控指标。最后,结合黑盒监控模式,对集群中部署的服务进行探测,从而当应用发生故障后,能够快速处理和恢复。
综上所述,我们需要综合使用白盒监控和黑盒监控模式,建立从基础设施,Kubernetes核心组件,应用容器等全面的监控体系。
在白盒监控层面我们需要关注:
- 基础设施层(Node):为整个集群和应用提供运行时资源,需要通过各节点的kubelet获取节点的基本状态,同时通过在节点上部署Node Exporter获取节点的资源使用情况;
- 容器基础设施(Container):为应用提供运行时环境,Kubelet内置了对cAdvisor的支持,用户可以直接通过Kubelet组件获取给节点上容器相关监控指标;
- 用户应用(Pod):Pod中会包含一组容器,它们一起工作,并且对外提供一个(或者一组)功能。如果用户部署的应用程序内置了对Prometheus的支持,那么我们还应该采集这些Pod暴露的监控指标;
- Kubernetes组件:获取并监控Kubernetes核心组件的运行状态,确保平台自身的稳定运行。
而在黑盒监控层面,则主要需要关注以下:
- 内部服务负载均衡(Service):在集群内,通过Service在集群暴露应用功能,集群内应用和应用之间访问时提供内部的负载均衡。通过Blackbox Exporter探测Service的可用性,确保当Service不可用时能够快速得到告警通知;
- 外部访问入口(Ingress):通过Ingress提供集群外的访问入口,从而可以使外部客户端能够访问到部署在Kubernetes集群内的服务。因此也需要通过Blackbox Exporter对Ingress的可用性进行探测,确保外部用户能够正常访问集群内的功能;
说这么大家肯定有了一点初步的了解k8s的监控,那我们接下来趁热打铁,直接上实践,我们用夜莺来监控k8s的六大组件。
(二)K8s-ApiServer组件监控
ApiServer 是 Kubernetes 架构中的核心,是所有 API 是入口,它串联所有的系统组件。
为了方便监控管理 ApiServer,设计者们为它暴露了一系列的指标数据。当你部署完集群,默认会在default名称空间下创建一个名叫kubernetes的 service,它就是 ApiServer 的地址,当然也可以查看本机暴露的apiserver的端口ss -tlnp
[root@k8s-master ~]# kubectl get service -A | grep kubernetes
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 52d
[root@k8s-master ~]# ss -tlpn | grep apiserver
LISTEN 0 128 [::]:6443 [::]:* users:(("kube-apiserver",pid=2287,fd=7))
但是当我们想要去获取抓紧metrics数据的时候,会发现我们抓紧不了,没有权限证书
[root@k8s-master ~]# curl -s -k https://localhost:6443/metrics
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "forbidden: User "system:anonymous" cannot get path "/metrics"",
"reason": "Forbidden",
"details": {},
"code": 403
}[root@k8s-master ~]#
所以,要监控 ApiServer,采集到对应的指标,就需要先授权。为此,我们先准备认证信息。
(1)我们先创建一个namespace来专门做夜莺监控采集指标
[root@k8s-master ~]# kubectl create namespace flashcat
(2)创建认证授权信息rbac
这个yaml文件的意思就是我们创建一个账号sa名为categraf,然后给他绑定resources的verbs权限,让categraf这个账号有足够的权限来获取k8s的各个组件的指标采集
vim apiserver-auth.yaml
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: categraf
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/metrics
- nodes/stats
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
- networking.k8s.io
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics", "/metrics/cadvisor"]
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: categraf
namespace: flashcat
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: categraf
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: categraf
subjects:
- kind: ServiceAccount
name: categraf
namespace: flashcat(3)使用prometheus-agent进行指标采集
支持 Kubernetes 服务发现的 agent 有不少,但是要说最原汁原味的还是 Prometheus 自身,Prometheus 新版本(v2.32.0)支持了 agent mode 模式,即把 Prometheus 进程当做采集器 agent,采集了数据之后通过 remote write 方式传给中心(这里使用早就准备好的 Nightingale 作为数据接收服务端)。那这里我就使用 Prometheus 的 agent mode 方式来采集 APIServer。
① 创建Prometheus的配置文件
这里给大家解释一下这个配置文件的一些内容,给一些对普罗米修斯还不是很了解的小伙伴参考:
global:第一部分定义的一个名为global的模块
scrape_interval: 采集间隔
evaluation_interval: 评估间隔,用于控制数据的收集和处理频率
scrape_config: 第二部分定义的模块,用来配置Prometheus要监控的目标
job_name: 表示该配置是用于监控Kubernetets APIserver的
kubernetes_sd_configs: 表示指定了从kubernetest Service Discovery中获取目录对象的方式
此处使用了 role: endpoints 获取endpoint对象,也就是API server的ip地址和端口信息。
scheme:指定了网络通信协议是HTTPS
tls_config:参数指定了TLS证书的相关配置,包括是否验证服务器端证书等。
insecure_skip_verify:是一个bool类型的参数,如果为true,表示跳过对服务器端证书的验证。在生产环境中,不应该使用,因为会导致通信的不安全。正常情况下。我们需要在客户端上配置ca证书来验证服务器端证书的合法性。
authorization: 指定了认证信息的来源,这里使用了默认的kubernetest服务账号的Token。
relabel_configs:用于将原始数据标签进行变换,筛选出需要的目标数据
source_labels:定义了三个规则用来匹配标签。其中__meta_kubernetes_namespace表示Kubernetes命名空间,__meta_kubernetes_service_name表示服务名称,__meta_kubernetes_endpoint_port_name表示端口名称
action:指定该操作是保留keep,也就是保留符合指定正则表达式的标签
regex:使用正则表达式来对标签进行过滤,这里的正则表达式为default;kubernetes;http,表示要保留的目标是default命名空间下的kubernetes服务,并且端口是http。
通过这个relabel_configs块,Prometheus将采集到的来自default命名空间下的kubernetes服务,并且端口是http的数据进行保留,并将这些数据推送给后续的n9e夜莺
remote_write: 用于将普罗米修斯采集的数据写入外部存储。这里我们定义的是夜莺的地址。prometheus/v1/write是外部存储的接口路径。
vim prometheus-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-agent-conf
labels:
name: prometheus-agent-conf
namespace: flashcat
data:
prometheus.yml: |-
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
remote_write:
- url: 'http://192.168.120.17:17000/prometheus/v1/write'② 部署Prometehus Agent
这里我们使用deployment的方式部署
其中--enable-feature=agent表示启动的是 agent 模式。
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-agent
namespace: flashcat
labels:
app: prometheus-agent
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-agent
template:
metadata:
labels:
app: prometheus-agent
spec:
serviceAccountName: categraf
containers:
- name: prometheus
image: prom/prometheus
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--web.enable-lifecycle"
- "--enable-feature=agent"
ports:
- containerPort: 9090
resources:
requests:
cpu: 500m
memory: 500M
limits:
cpu: 1
memory: 1Gi
volumeMounts:
- name: prometheus-config-volume
mountPath: /etc/prometheus/
- name: prometheus-storage-volume
mountPath: /prometheus/
volumes:
- name: prometheus-config-volume
configMap:
defaultMode: 420
name: prometheus-agent-conf
- name: prometheus-storage-volume
emptyDir: {}查看是否部署成功
[root@k8s-master ~]# kubectl get pod -n flashcat
NAME READY STATUS RESTARTS AGE
prometheus-agent-7c8d7bc7bb-42djw 1/1 Running 0 115m
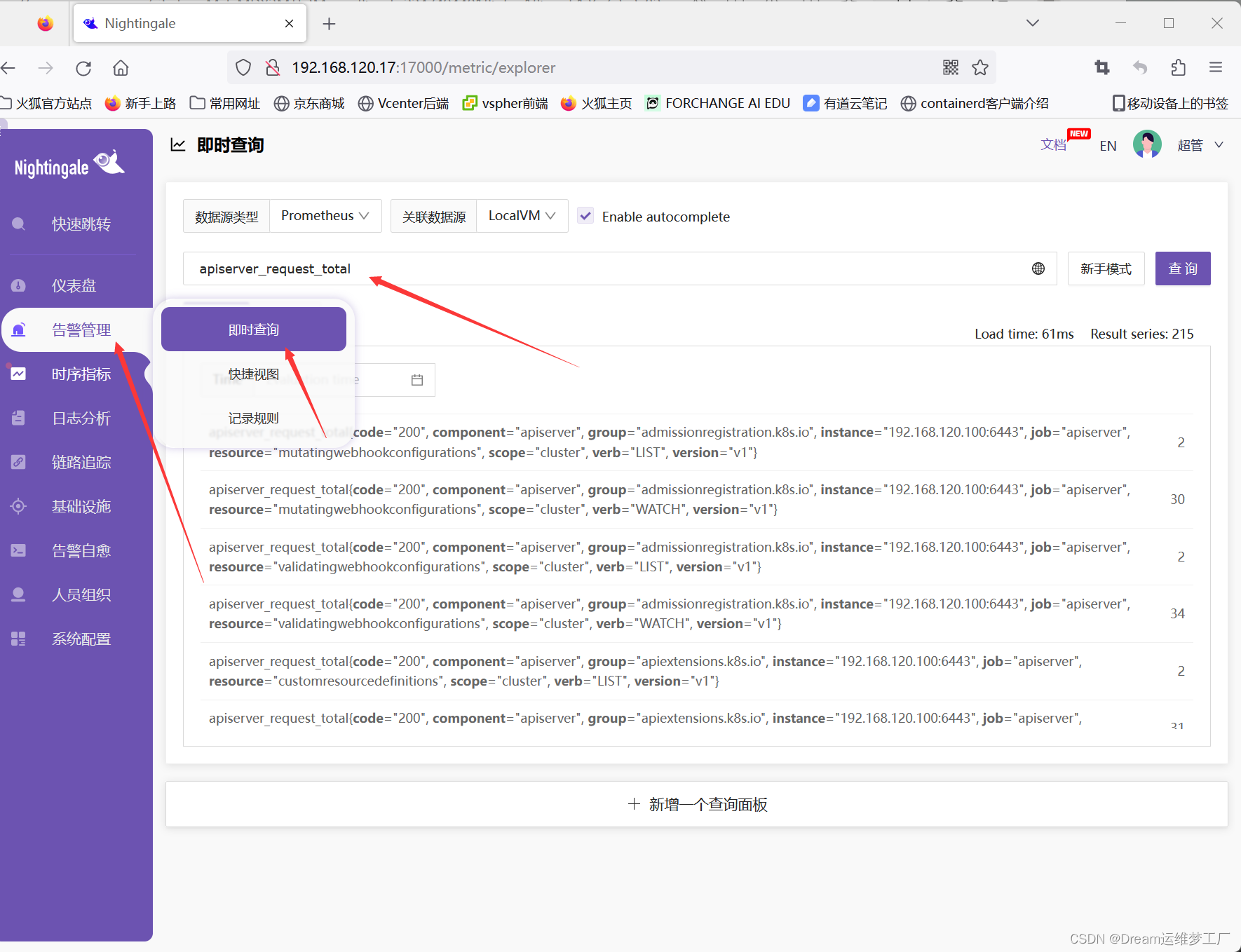
然后可以到夜莺web页面查看指标 测试apiserver_request_total
获取到了指标数据,后面就是合理利用指标做其他动作,比如构建面板、告警处理等。
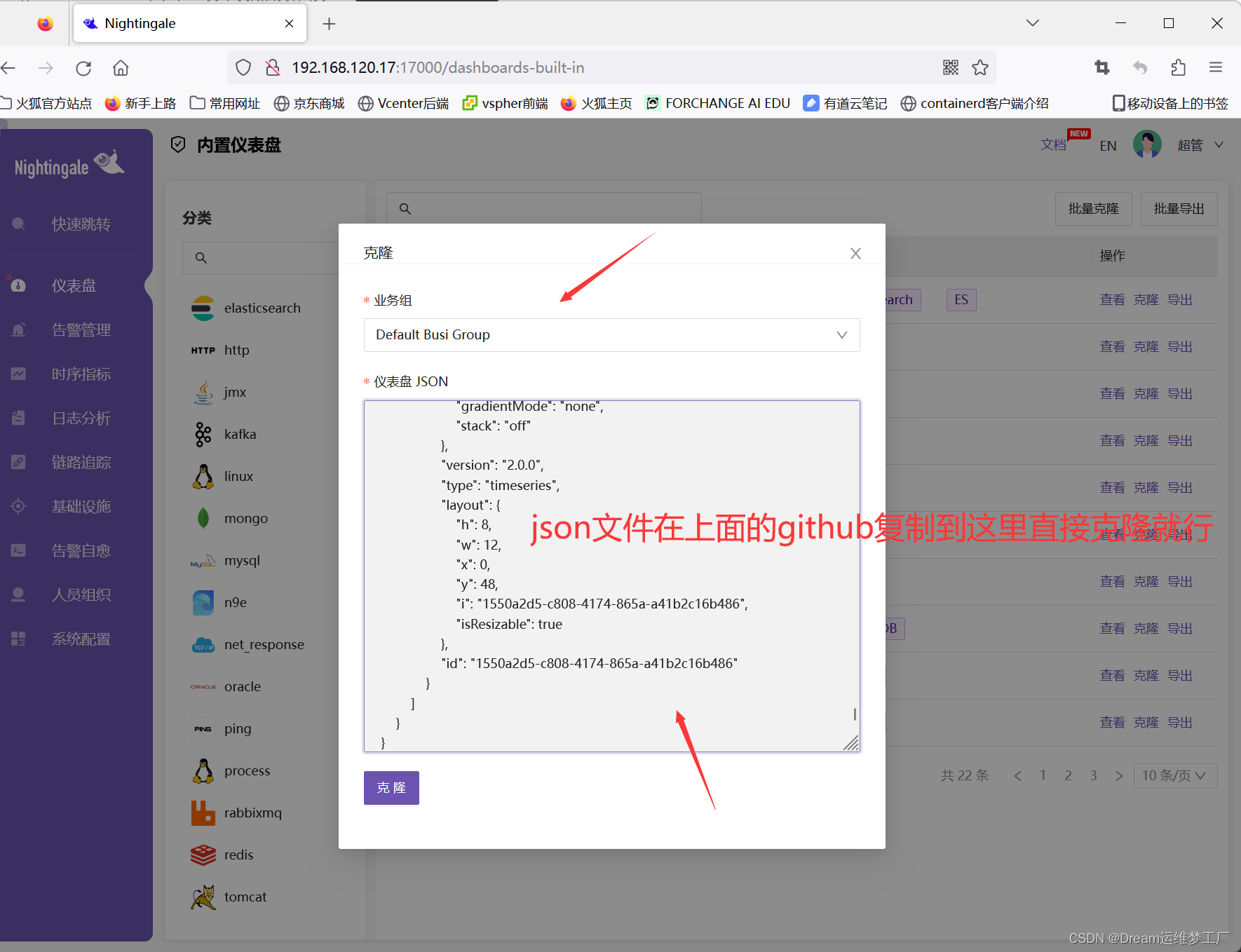
导入Apiserver的监控大盘,监控的json文件在categraf/apiserver-dash.json · GitHub
直接复制导入json文件的内容即可

另外,Apiserver 的关键指标的含义也贴出来
# HELP apiserver_request_duration_seconds [STABLE] Response latency distribution in seconds for each verb, dry run value, group, version, resource, subresource, scope and component.
# TYPE apiserver_request_duration_seconds histogram
apiserver响应的时间分布,按照url 和 verb 分类
一般按照instance和verb+时间 汇聚
# HELP apiserver_request_total [STABLE] Counter of apiserver requests broken out for each verb, dry run value, group, version, resource, scope, component, and HTTP response code.
# TYPE apiserver_request_total counter
apiserver的请求总数,按照verb、 version、 group、resource、scope、component、 http返回码分类统计
# HELP apiserver_current_inflight_requests [STABLE] Maximal number of currently used inflight request limit of this apiserver per request kind in last second.
# TYPE apiserver_current_inflight_requests gauge
最大并发请求数, 按mutating(非get list watch的请求)和readOnly(get list watch)分别限制
超过max-requests-inflight(默认值400)和max-mutating-requests-inflight(默认200)的请求会被限流
apiserver变更时要注意观察,也是反馈集群容量的一个重要指标
# HELP apiserver_response_sizes [STABLE] Response size distribution in bytes for each group, version, verb, resource, subresource, scope and component.
# TYPE apiserver_response_sizes histogram
apiserver 响应大小,单位byte, 按照verb、 version、 group、resource、scope、component分类统计
# HELP watch_cache_capacity [ALPHA] Total capacity of watch cache broken by resource type.
# TYPE watch_cache_capacity gauge
按照资源类型统计的watch缓存大小
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
每秒钟用户态和系统态cpu消耗时间, 计算apiserver进程的cpu的使用率
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
apiserver的内存使用量(单位:Byte)
# HELP workqueue_adds_total [ALPHA] Total number of adds handled by workqueue
# TYPE workqueue_adds_total counter
apiserver中包含的controller的工作队列,已处理的任务总数
# HELP workqueue_depth [ALPHA] Current depth of workqueue
# TYPE workqueue_depth gauge
apiserver中包含的controller的工作队列深度,表示当前队列中要处理的任务的数量,数值越小越好
例如APIServiceRegistrationController admission_quota_controller(三)K8s-ControllerManager组件监控
controller-manager 是 Kubernetes 控制面的组件,通常不太可能出问题,一般监控一下通用的进程指标就问题不大了,不过 controller-manager 确实也暴露了很多 /metrics 白盒指标,我们也一并梳理一下相关内容。
监控思路跟上面一样,也是用Prometheus-Agent的方式进行采集指标
(1)创建prometheus的配置文件
因为我们上面做apiserver的时候已经做了权限绑定和一些基础配置,所以这里我们直接添加Prometheus的配置文件添加job模块内容即可。
这里我们可以直接打开之前创建的prometheus-cm的configmap配置文件 添加一个job关于controller-manager的即可
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-agent-conf
labels:
name: prometheus-agent-conf
namespace: flashcat
data:
prometheus.yml: |-
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
## 这里添加即可以下内容即可
- job_name: 'controller-manager'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-controller-manager;https-metrics
remote_write:
- url: 'http://192.168.120.17:17000/prometheus/v1/write'(2)重新创建controller 的endpoints
先查看一下自己有没有对应的controller-manager的endpoint 如果没有创建一个servece即可
为什么要endpoint呢 因为我们上面Prometheus的采集规则role就是endpoint
[root@k8s-master ~]# kubectl get endpoints -A | grep controller
这里如果没有查询到就创建一个serveice文件
vim controller-manager-service.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
spec:
clusterIP: None
ports:
- name: https-metrics
port: 10257
protocol: TCP
targetPort: 10257
selector:
component: kube-controller-manager
sessionAffinity: None
type: ClusterIP
运行yaml: kubectl apply -f controller-manager-service.yaml (3)更改controller 的bind-address
注意:如果你使用的kubeadm安装的k8s集群,需要把controller-manager的bind-address改为0.0.0.0
[root@k8s-master ~]# vim /etc/kubernetes/manifests/kube-controller-manager.yaml
....
....
- --bind-address=0.0.0.0 ##找到bind-address 把127.0.0.1 改为 0.0.0.0
(4)指标测试
然后重启Prometheus-agent 的pod 重新加载Prometheus的配置文件的yaml
重启后先在夜莺的web页面查询指标,测试指标daemon_controller_rate_limiter_use

导入监控大盘,大盘链接:categraf/cm-dash.json at main · flashcatcloud/categraf · GitHub
查看仪表盘 (怎么导入仪表盘的操作跟上面导入apiserver的仪表盘一样的,把json文件克隆进行即可)
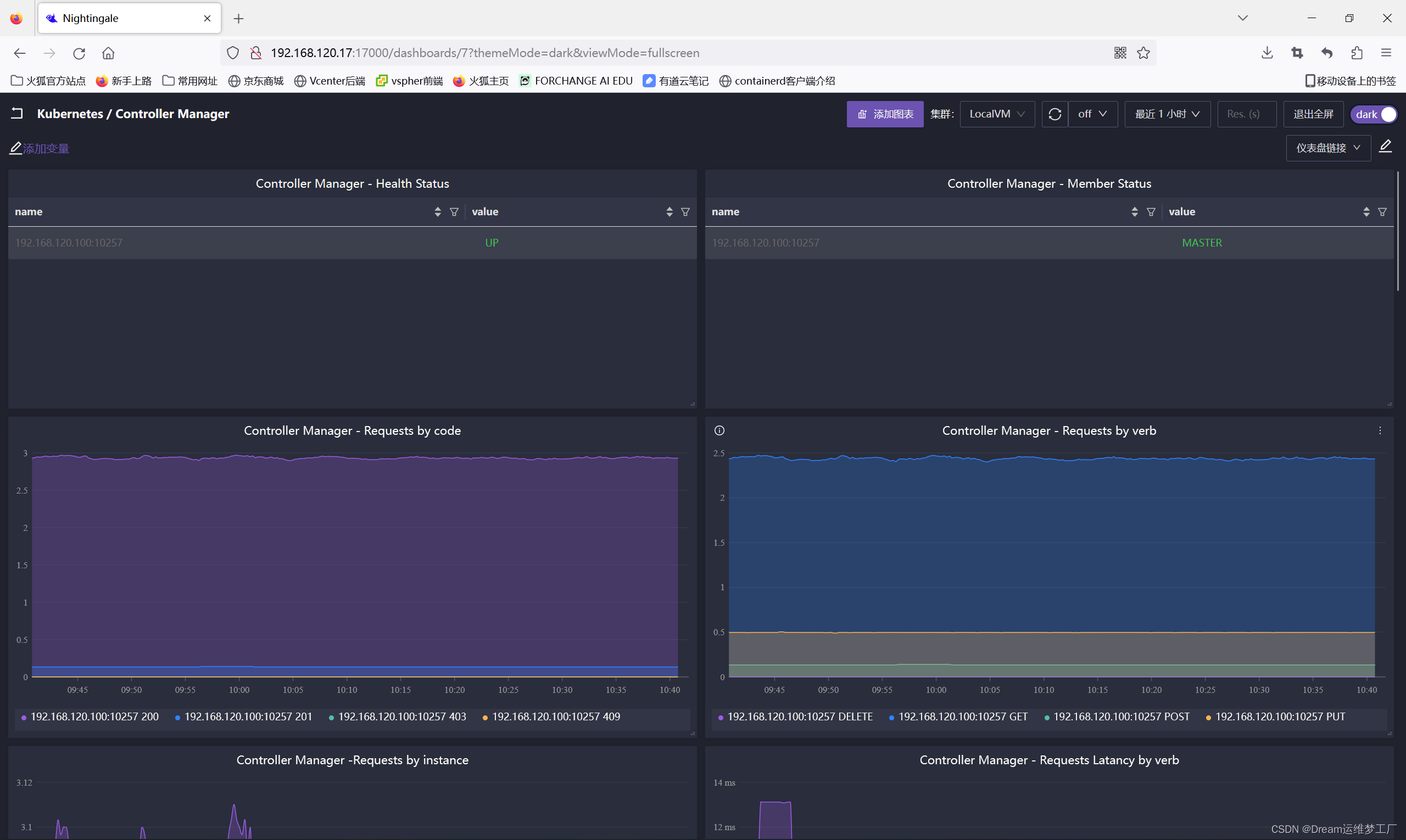
controller-manager关键指标意思也贴出来
# HELP rest_client_request_duration_seconds [ALPHA] Request latency in seconds. Broken down by verb and URL.
# TYPE rest_client_request_duration_seconds histogram
请求apiserver的耗时分布,按照url+verb统计
# HELP cronjob_controller_cronjob_job_creation_skew_duration_seconds [ALPHA] Time between when a cronjob is scheduled to be run, and when the corresponding job is created
# TYPE cronjob_controller_cronjob_job_creation_skew_duration_seconds histogram
cronjob 创建到运行的时间分布
# HELP leader_election_master_status [ALPHA] Gauge of if the reporting system is master of the relevant lease, 0 indicates backup, 1 indicates master. 'name' is the string used to identify the lease. Please make sure to group by name.
# TYPE leader_election_master_status gauge
控制器的选举状态,0表示backup, 1表示master
# HELP node_collector_zone_health [ALPHA] Gauge measuring percentage of healthy nodes per zone.
# TYPE node_collector_zone_health gauge
每个zone的健康node占比
# HELP node_collector_zone_size [ALPHA] Gauge measuring number of registered Nodes per zones.
# TYPE node_collector_zone_size gauge
每个zone的node数
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
cpu使用量(也可以理解为cpu使用率)
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
控制器打开的fd数
# HELP pv_collector_bound_pv_count [ALPHA] Gauge measuring number of persistent volume currently bound
# TYPE pv_collector_bound_pv_count gauge
当前绑定的pv数量
# HELP pv_collector_unbound_pvc_count [ALPHA] Gauge measuring number of persistent volume claim currently unbound
# TYPE pv_collector_unbound_pvc_count gauge
当前没有绑定的pvc数量
# HELP pv_collector_bound_pvc_count [ALPHA] Gauge measuring number of persistent volume claim currently bound
# TYPE pv_collector_bound_pvc_count gauge
当前绑定的pvc数量
# HELP pv_collector_total_pv_count [ALPHA] Gauge measuring total number of persistent volumes
# TYPE pv_collector_total_pv_count gauge
pv总数量
# HELP workqueue_adds_total [ALPHA] Total number of adds handled by workqueue
# TYPE workqueue_adds_total counter
各个controller已接受的任务总数
与apiserver的workqueue_adds_total指标类似
# HELP workqueue_depth [ALPHA] Current depth of workqueue
# TYPE workqueue_depth gauge
各个controller队列深度,表示一个controller中的任务的数量
与apiserver的workqueue_depth类似,这个是指各个controller中队列的深度,数值越小越好
# HELP workqueue_queue_duration_seconds [ALPHA] How long in seconds an item stays in workqueue before being requested.
# TYPE workqueue_queue_duration_seconds histogram
任务在队列中的等待耗时,按照控制器分别统计
# HELP workqueue_work_duration_seconds [ALPHA] How long in seconds processing an item from workqueue takes.
# TYPE workqueue_work_duration_seconds histogram
任务出队到被处理完成的时间,按照控制分别统计
# HELP workqueue_retries_total [ALPHA] Total number of retries handled by workqueue
# TYPE workqueue_retries_total counter
任务进入队列重试的次数
# HELP workqueue_longest_running_processor_seconds [ALPHA] How many seconds has the longest running processor for workqueue been running.
# TYPE workqueue_longest_running_processor_seconds gauge
正在处理的任务中,最长耗时任务的处理时间
# HELP endpoint_slice_controller_syncs [ALPHA] Number of EndpointSlice syncs
# TYPE endpoint_slice_controller_syncs counter
endpoint_slice 同步的数量(1.20以上)
# HELP get_token_fail_count [ALPHA] Counter of failed Token() requests to the alternate token source
# TYPE get_token_fail_count counter
获取token失败的次数
# HELP go_memstats_gc_cpu_fraction The fraction of this program's available CPU time used by the GC since the program started.
# TYPE go_memstats_gc_cpu_fraction gauge
controller gc的cpu使用率(四)K8s-Scheduler组件监控
scheduler 是 Kubernetes 的控制面组件,负责调度对象到合适的 node 上,会有一系列的规则计算和筛选,重点关注调度相关的指标。相关监控数据也是通过 /metrics 接口暴露,scheduler的暴露的端口是10259
接下来就是采集数据了,我们还是使用 prometheus agent 来拉取数据,原汁原味的,只要在上一篇文章提供的 configmap 中增加 scheduler 相关的配置job即可
(1)创建prometheus的配置文件
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-agent-conf
labels:
name: prometheus-agent-conf
namespace: flashcat
data:
prometheus.yml: |-
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'controller-manager'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-controller-manager;https-metrics
##添加以下scheduler的job即可
- job_name: 'scheduler'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-scheduler;https
remote_write:
- url: 'http://192.168.120.17:17000/prometheus/v1/write'(2)配置Scheduler的service
跟上面一样,首先我们要查看有没有相关的sheduler的endpoint,如果没有我们就要创建一个service来暴露
[root@k8s-master ~]# kubectl get endpoints -A | grep schedu
## 如果没有我们就创建一个service的yaml
vim scheduler-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
spec:
clusterIP: None
ports:
- name: https
port: 10259
protocol: TCP
targetPort: 10259
selector:
component: kube-scheduler
sessionAffinity: None
type: ClusterIP(3)重启prometheus-agent
配置更新完configmap后要重新去apply一下configmap或者你edit更改,更改完成后如果还是无法获取指标就重启一下Prometheus-agent的pod 重新apply一下就行 ,或者curl -X POST "http://<PROMETHEUS_IP>:9090/-/reload"重载 Prometheus,这里的prometheus的ip是pod的IP,这个ip你要查看Prometheus pod的IP 可以使用kubectl get pod -o wide -n flashcat 即可。
(注意这里如果你的k8s是kubeadm安装的,也要去scheduler的manifests文件把bind-address更改为0.0.0.0)
[root@k8s-master manifests]# vim /etc/kubernetes/manifests/kube-scheduler.yaml
......
......
......
- --bind-address=0.0.0.0 ##找到这行更改为0.0.0.0即可(4) 测试指标导入仪表盘
测试指标scheduler_scheduler_cache_size

导入监控大盘,大盘json链接: categraf/scheduler-dash.json at main · · GitHub
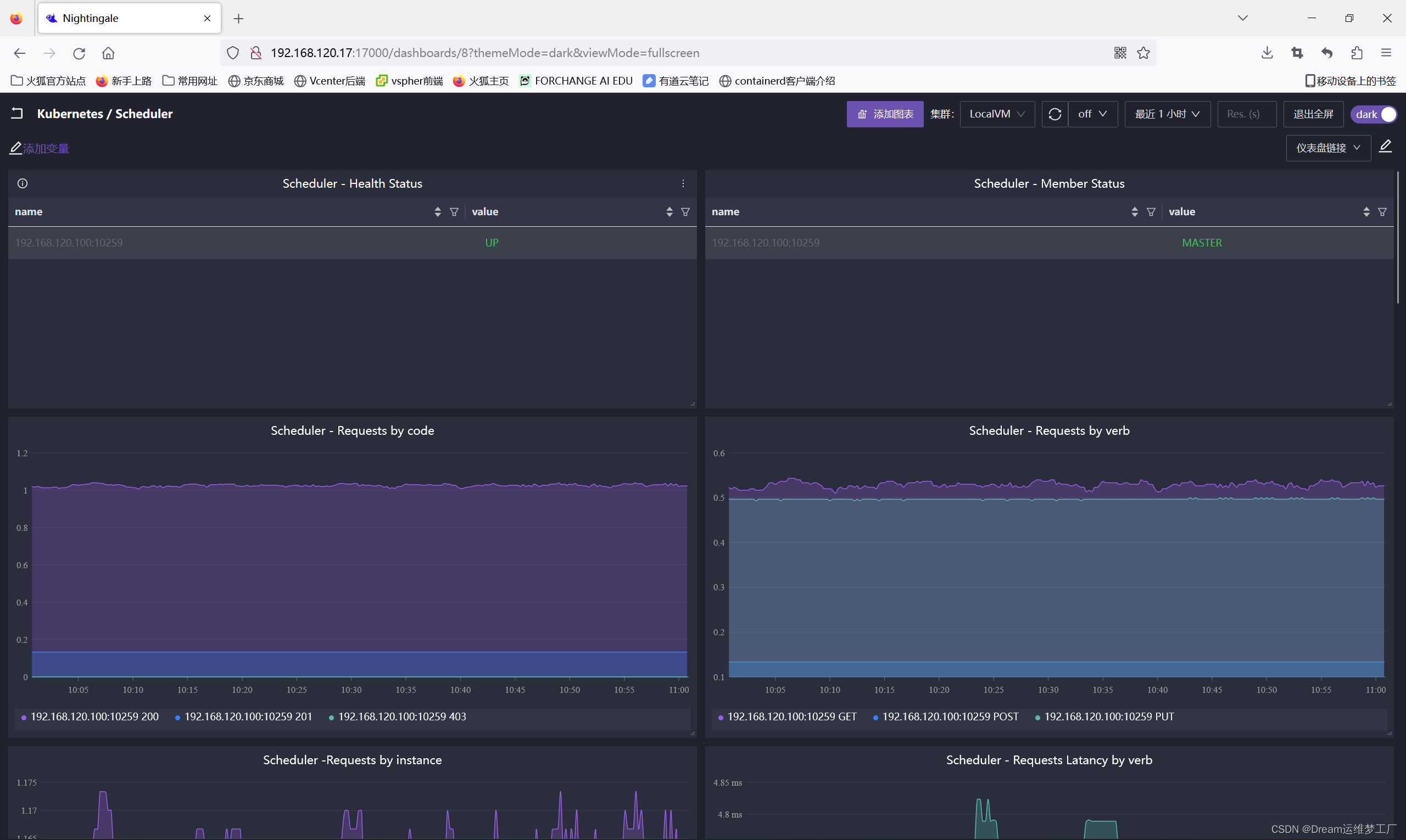
这里也贴出常用scheduler关键指标意思:
# HELP rest_client_request_duration_seconds [ALPHA] Request latency in seconds. Broken down by verb and URL.
# TYPE rest_client_request_duration_seconds histogram
请求apiserver的延迟分布
# HELP rest_client_requests_total [ALPHA] Number of HTTP requests, partitioned by status code, method, and host.
# TYPE rest_client_requests_total counter
请求apiserver的总数 ,按照host code method 统计
# HELP leader_election_master_status [ALPHA] Gauge of if the reporting system is master of the relevant lease, 0 indicates backup, 1 indicates master. 'name' is the string used to identify the lease. Please make sure to group by name.
# TYPE leader_election_master_status gauge
调度器的选举状态,0表示backup, 1表示master
# HELP scheduler_queue_incoming_pods_total [STABLE] Number of pods added to scheduling queues by event and queue type.
# TYPE scheduler_queue_incoming_pods_total counter
进入调度队列的pod数
# HELP scheduler_preemption_attempts_total [STABLE] Total preemption attempts in the cluster till now
# TYPE scheduler_preemption_attempts_total counter
调度器驱逐容器的次数
# HELP scheduler_scheduler_cache_size [ALPHA] Number of nodes, pods, and assumed (bound) pods in the scheduler cache.
# TYPE scheduler_scheduler_cache_size gauge
调度器cache中node pod和绑定pod的数目
# HELP scheduler_pending_pods [STABLE] Number of pending pods, by the queue type. 'active' means number of pods in activeQ; 'backoff' means number of pods in backoffQ; 'unschedulable' means number of pods in unschedulableQ.
# TYPE scheduler_pending_pods gauge
调度pending的pod数量,按照queue type分别统计
# HELP scheduler_plugin_execution_duration_seconds [ALPHA] Duration for running a plugin at a specific extension point.
# TYPE scheduler_plugin_execution_duration_seconds histogram
调度插件在每个扩展点的执行时间,按照extension_point+plugin+status 分别统计
# HELP scheduler_e2e_scheduling_duration_seconds [ALPHA] (Deprecated since 1.23.0) E2e scheduling latency in seconds (scheduling algorithm + binding). This metric is replaced by scheduling_attempt_duration_seconds.
# TYPE scheduler_e2e_scheduling_duration_seconds histogram
调度延迟分布,1.23.0 以后会被scheduling_attempt_duration_seconds替代
# HELP scheduler_framework_extension_point_duration_seconds [STABLE] Latency for running all plugins of a specific extension point.
# TYPE scheduler_framework_extension_point_duration_seconds histogram
调度框架的扩展点延迟分布,按extension_point(扩展点Bind Filter Permit PreBind/PostBind PreFilter/PostFilter Reseve)
+profile(调度器)+ status(调度成功) 统计
# HELP scheduler_pod_scheduling_attempts [STABLE] Number of attempts to successfully schedule a pod.
# TYPE scheduler_pod_scheduling_attempts histogram
pod调度成功前,调度重试的次数分布
# HELP scheduler_schedule_attempts_total [STABLE] Number of attempts to schedule pods, by the result. 'unschedulable' means a pod could not be scheduled, while 'error' means an internal scheduler problem.
# TYPE scheduler_schedule_attempts_total counter
按照调度结果统计的调度重试次数。 "unschedulable" 表示无法调度,"error"表示调度器内部错误
# HELP scheduler_scheduler_goroutines [ALPHA] Number of running goroutines split by the work they do such as binding.
# TYPE scheduler_scheduler_goroutines gauge
按照功能(binding filter之类)统计的goroutine数量
# HELP scheduler_scheduling_algorithm_duration_seconds [ALPHA] Scheduling algorithm latency in seconds
# TYPE scheduler_scheduling_algorithm_duration_seconds histogram
调度算法的耗时分布
# HELP scheduler_scheduling_attempt_duration_seconds [STABLE] Scheduling attempt latency in seconds (scheduling algorithm + binding)
# TYPE scheduler_scheduling_attempt_duration_seconds histogram
调度算法+binding的耗时分布
# HELP scheduler_scheduler_goroutines [ALPHA] Number of running goroutines split by the work they do such as binding.
# TYPE scheduler_scheduler_goroutines gauge
调度器的goroutines数目(五)K8s-Etcd组件监控
ETCD 是 Kubernetes 控制面的重要组件和依赖,Kubernetes 的各类信息都存储在 ETCD 中,所以监控 ETCD 就显得尤为重要。ETCD 在 Kubernetes 中的架构角色如下(只与 APIServer 交互):

ETCD 是一个类似 Zookeeper 的产品,通常由多个节点组成集群,节点之间使用 raft 协议保证一致性。ETCD 具有以下特点:
- 每个节点都有一个角色状态,Follower、Candidate、Leader
- 如果 Follower 找不到当前 Leader 节点的时候,就会变成 Candidate
- 选举系统会从 Candidate 中选出 Leader
- 所有的写操作都通过 Leader 进行
- 一旦 Leader 从大多数 Follower 拿到 ack,该写操作就被认为是“已提交”状态
- 只要大多数节点存活,整个 ETCD 就是存活的,个别节点挂掉不影响整个集群的可用性
- ETCD 使用 restful 风格的 HTTP API 来操作,这使得 ETCD 的使用非常方便,这也是 ETCD 流行的一个关键因素
ETCD 这么云原生的组件,显然是内置支持了 /metrics 接口的,不过 ETCD 很讲求安全性,默认的 2379 端口的访问是要用证书的,我来测试一下先:
[root@tt-fc-dev01.nj ~]# curl -k https://localhost:2379/metrics
curl: (35) error:14094412:SSL routines:ssl3_read_bytes:sslv3 alert bad certificate
[root@tt-fc-dev01.nj ~]# ls /etc/kubernetes/pki/etcd
ca.crt ca.key healthcheck-client.crt healthcheck-client.key peer.crt peer.key server.crt server.key
[root@tt-fc-dev01.nj ~]# curl -s --cacert /etc/kubernetes/pki/etcd/ca.crt --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key https://localhost:2379/metrics | head -n 6
# HELP etcd_cluster_version Which version is running. 1 for 'cluster_version' label with current cluster version
# TYPE etcd_cluster_version gauge
etcd_cluster_version{cluster_version="3.5"} 1
# HELP etcd_debugging_auth_revision The current revision of auth store.
# TYPE etcd_debugging_auth_revision gauge
etcd_debugging_auth_revision 1 使用 kubeadm 安装的 Kubernetes 集群,相关证书是在 /etc/kubernetes/pki/etcd 目录下,为 curl 命令指定相关证书,是可以访问的通的。后面使用 Categraf 的 prometheus 插件直接采集相关数据即可。
不过指标数据实在没必要做这么强的安全管控,整的挺麻烦,实际上,ETCD 也确实提供了另一个端口来获取指标数据,无需走这套证书认证机制。
(1)更改etcd配置文件监听地址为0.0.0.0
这里我们首先去etcd的manifests文件更改监听metrics地址
[root@k8s-master manifests]# vim /etc/kubernetes/manifests/etcd.yaml
......
......
- --listen-metrics-urls=http://0.0.0.0:2381 ##找到lisetn这行,把地址改为0.0.0.0
这样改完以后我们就能直接通过2381端口来抓取metrics数据
[root@tt-fc-dev01.nj ~]# curl -s localhost:2381/metrics | head -n 6
# HELP etcd_cluster_version Which version is running. 1 for 'cluster_version' label with current cluster version
# TYPE etcd_cluster_version gauge
etcd_cluster_version{cluster_version="3.5"} 1
# HELP etcd_debugging_auth_revision The current revision of auth store.
# TYPE etcd_debugging_auth_revision gauge
etcd_debugging_auth_revision 1(2)数据采集
ETCD 的数据采集通常使用 3 种方式:
- 使用 ETCD 所在宿主的 agent 直接来采集,因为 ETCD 是个静态 Pod,采用的 hostNetwork,所以 agent 直接连上去采集即可
- 把采集器和 ETCD 做成 sidecar 的模式,ETCD 的使用其实已经越来越广泛,不只是给 Kubernetes 使用,很多业务也在使用,在 Kubernetes 里创建和管理 ETCD 也是很常见的做法,sidecar 这种模式非常干净,随着 ETCD 创建而创建,随着其销毁而销毁,省事
- 使用服务发现机制,在中心端部署采集器,就像之前的文章中介绍的 APIServer、Controller-manager、Scheduler 等的做法,使用 Prometheus agent mode 采集监控数据,当然,这种方式的话需要有对应的 etcd endpoint,你可以自行检查一下
kubectl get endpoints -n kube-system,如果没有,创建一下即可
[root@k8s-master manifests]# kubectl get endpoints -A | grep etcd
##如果没有对应的endpoint 就创建一个service
vim etcd-service.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: etcd
labels:
k8s-app: etcd
spec:
selector:
component: etcd
type: ClusterIP
clusterIP: None
ports:
- name: http
port: 2381
targetPort: 2381
protocol: TCP更改我们直接写的configmap的Prometheus的配置文件,添加etcd job字段模块即可
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-agent-conf
labels:
name: prometheus-agent-conf
namespace: flashcat
data:
prometheus.yml: |-
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'controller-manager'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-controller-manager;https-metrics
- job_name: 'scheduler'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-scheduler;https
## 添加以下etcd字段
- job_name: 'etcd'
kubernetes_sd_configs:
- role: endpoints
scheme: http
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;etcd;http
remote_write:
- url: 'http://192.168.120.17:17000/prometheus/v1/write'(3)指标测试
更改完成后 重新加载yaml文件和Prometheus-agent,然后打开夜莺的web页面指标查询,测试指标是否查询得到:etcd_cluster_version

查询到指标后,导入监控仪表盘,仪表盘json地址:categraf/etcd-dash. · fl/categraf · GitHub
复制json文件克隆到仪表盘

ETCD关键指标意思含义:
# HELP etcd_server_is_leader Whether or not this member is a leader. 1 if is, 0 otherwise.
# TYPE etcd_server_is_leader gauge
etcd leader 表示 ,1 leader 0 learner
# HELP etcd_server_health_success The total number of successful health checks
# TYPE etcd_server_health_success counter
etcd server 健康检查成功次数
# HELP etcd_server_health_failures The total number of failed health checks
# TYPE etcd_server_health_failures counter
etcd server 健康检查失败次数
# HELP etcd_disk_defrag_inflight Whether or not defrag is active on the member. 1 means active, 0 means not.
# TYPE etcd_disk_defrag_inflight gauge
是否启动数据压缩,1表示压缩,0表示没有启动压缩
# HELP etcd_server_snapshot_apply_in_progress_total 1 if the server is applying the incoming snapshot. 0 if none.
# TYPE etcd_server_snapshot_apply_in_progress_total gauge
是否再快照中,1 快照中,0 没有
# HELP etcd_server_leader_changes_seen_total The number of leader changes seen.
# TYPE etcd_server_leader_changes_seen_total counter
集群leader切换的次数
# HELP grpc_server_handled_total Total number of RPCs completed on the server, regardless of success or failure.
# TYPE grpc_server_handled_total counter
grpc 调用总数
# HELP etcd_disk_wal_fsync_duration_seconds The latency distributions of fsync called by WAL.
# TYPE etcd_disk_wal_fsync_duration_seconds histogram
etcd wal同步耗时
# HELP etcd_server_proposals_failed_total The total number of failed proposals seen.
# TYPE etcd_server_proposals_failed_total counter
etcd proposal(提议)失败总次数(proposal就是完成raft协议的一次请求)
# HELP etcd_server_proposals_pending The current number of pending proposals to commit.
# TYPE etcd_server_proposals_pending gauge
etcd proposal(提议)pending总次数(proposal就是完成raft协议的一次请求)
# HELP etcd_server_read_indexes_failed_total The total number of failed read indexes seen.
# TYPE etcd_server_read_indexes_failed_total counter
读取索引失败的次数统计(v3索引为所有key都建了索引,索引是为了加快range操作)
# HELP etcd_server_slow_read_indexes_total The total number of pending read indexes not in sync with leader's or timed out read index requests.
# TYPE etcd_server_slow_read_indexes_total counter
读取到过期索引或者读取超时的次数
# HELP etcd_server_quota_backend_bytes Current backend storage quota size in bytes.
# TYPE etcd_server_quota_backend_bytes gauge
当前后端的存储quota(db大小的上限)
通过参数quota-backend-bytes调整大小,默认2G,官方建议不超过8G
# HELP etcd_mvcc_db_total_size_in_bytes Total size of the underlying database physically allocated in bytes.
# TYPE etcd_mvcc_db_total_size_in_bytes gauge
etcd 分配的db大小(使用量大小+空闲大小)
# HELP etcd_mvcc_db_total_size_in_use_in_bytes Total size of the underlying database logically in use in bytes.
# TYPE etcd_mvcc_db_total_size_in_use_in_bytes gauge
etcd db的使用量大小
# HELP etcd_mvcc_range_total Total number of ranges seen by this member.
# TYPE etcd_mvcc_range_total counter
etcd执行range的数量
# HELP etcd_mvcc_put_total Total number of puts seen by this member.
# TYPE etcd_mvcc_put_total counter
etcd执行put的数量
# HELP etcd_mvcc_txn_total Total number of txns seen by this member.
# TYPE etcd_mvcc_txn_total counter
etcd实例执行事务的数量
# HELP etcd_mvcc_delete_total Total number of deletes seen by this member.
# TYPE etcd_mvcc_delete_total counter
etcd实例执行delete操作的数量
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
etcd cpu使用量
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
etcd 内存使用量
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
etcd 打开的fd数目(六)K8s-kubelet组件监控
接下来我们监控的就是k8s第二个模块salve-node的组件,kubelet监听有两个固定的端口,一个是10248,一个是10250,可以用ss -ntlp | grep kubelet命令查看。
10248是健康检测的端口,检测节点状态,可以使用curl localhost:10248/healthz查看
[root@k8s-master ~]# curl localhost:10248/healthz
ok
10250是kubelet默认的端口,/metrics接口就是在这个端口下,但是你不能直接通过这个端口获取metrics的数据,因为他有认证机制。 这一期我们还是讲使用Prometheus-agent的方式来采集metrics数据,下一期我们来通过认证使用daemonset的方式部署categraf来采集。
(1)配置Prometheus-agent configmap配置文件
跟上面的操作一样,在configmap下面添加名为kubelet的job字段即可,然后重新加载configmap的yaml文件
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-agent-conf
labels:
name: prometheus-agent-conf
namespace: flashcat
data:
prometheus.yml: |-
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'controller-manager'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-controller-manager;https-metrics
- job_name: 'scheduler'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-scheduler;https
- job_name: 'etcd'
kubernetes_sd_configs:
- role: endpoints
scheme: http
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;etcd;http
## 以下为添加的kubelete内容
- job_name: 'kubelet'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-kubelet;https
remote_write:
- url: 'http://192.168.120.17:17000/prometheus/v1/write'(2)配置kubelet的service和endpoints
跟之前一样我们要先查看本地有没有kubelet的endpoints如果没有就要添加。
[root@k8s-master ~]# kubectl get endpoints -A | grep kubelet
##如果没有就添加
vim kubelet-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: kubelet
name: kube-kubelet
namespace: kube-system
spec:
clusterIP: None
ports:
- name: https
port: 10250
protocol: TCP
targetPort: 10250
sessionAffinity: None
type: ClusterIP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kubelet
name: kube-kubelet
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.120.101
- ip: 192.168.120.102 ##这里我们自定义的endpoint,这里添加的是需要监控的k8s节点,这里我写的是master的ip地址和node的IP地址
ports:
- name: https
port: 10250
protocol: TCP(3)测试指标
然后打开夜莺的web页面,查看指标是否采集上。 测试指标:kubelet_running_pods

导入仪表盘,仪表盘地址:categraf/dashboard-by-ident.json at main · · GitHub

kubelet相关指标意思:
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
gc的时间统计(summary指标)
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
goroutine 数量
# HELP go_threads Number of OS threads created.
# TYPE go_threads gauge
线程数量
# HELP kubelet_cgroup_manager_duration_seconds [ALPHA] Duration in seconds for cgroup manager operations. Broken down by method.
# TYPE kubelet_cgroup_manager_duration_seconds histogram
操作cgroup的时长分布,按照操作类型统计
# HELP kubelet_containers_per_pod_count [ALPHA] The number of containers per pod.
# TYPE kubelet_containers_per_pod_count histogram
pod中container数量的统计(spec.containers的数量)
# HELP kubelet_docker_operations_duration_seconds [ALPHA] Latency in seconds of Docker operations. Broken down by operation type.
# TYPE kubelet_docker_operations_duration_seconds histogram
操作docker的时长分布,按照操作类型统计
# HELP kubelet_docker_operations_errors_total [ALPHA] Cumulative number of Docker operation errors by operation type.
# TYPE kubelet_docker_operations_errors_total counter
操作docker的错误累计次数,按照操作类型统计
# HELP kubelet_docker_operations_timeout_total [ALPHA] Cumulative number of Docker operation timeout by operation type.
# TYPE kubelet_docker_operations_timeout_total counter
操作docker的超时统计,按照操作类型统计
# HELP kubelet_docker_operations_total [ALPHA] Cumulative number of Docker operations by operation type.
# TYPE kubelet_docker_operations_total counter
操作docker的累计次数,按照操作类型统计
# HELP kubelet_eviction_stats_age_seconds [ALPHA] Time between when stats are collected, and when pod is evicted based on those stats by eviction signal
# TYPE kubelet_eviction_stats_age_seconds histogram
驱逐操作的时间分布,按照驱逐信号(原因)分类统计
# HELP kubelet_evictions [ALPHA] Cumulative number of pod evictions by eviction signal
# TYPE kubelet_evictions counter
驱逐次数统计,按照驱逐信号(原因)统计
# HELP kubelet_http_inflight_requests [ALPHA] Number of the inflight http requests
# TYPE kubelet_http_inflight_requests gauge
请求kubelet的inflight请求数,按照method path server_type统计, 注意与每秒的request数区别开
# HELP kubelet_http_requests_duration_seconds [ALPHA] Duration in seconds to serve http requests
# TYPE kubelet_http_requests_duration_seconds histogram
请求kubelet的请求时间统计, 按照method path server_type统计
# HELP kubelet_http_requests_total [ALPHA] Number of the http requests received since the server started
# TYPE kubelet_http_requests_total counter
请求kubelet的请求数统计,按照method path server_type统计
# HELP kubelet_managed_ephemeral_containers [ALPHA] Current number of ephemeral containers in pods managed by this kubelet. Ephemeral containers will be ignored if disabled by the EphemeralContainers feature gate, and this number will be 0.
# TYPE kubelet_managed_ephemeral_containers gauge
当前kubelet管理的临时容器数量
# HELP kubelet_network_plugin_operations_duration_seconds [ALPHA] Latency in seconds of network plugin operations. Broken down by operation type.
# TYPE kubelet_network_plugin_operations_duration_seconds histogram
网络插件的操作耗时分布 ,按照操作类型(operation_type)统计, 如果 --feature-gates=EphemeralContainers=false, 否则一直为0
# HELP kubelet_network_plugin_operations_errors_total [ALPHA] Cumulative number of network plugin operation errors by operation type.
# TYPE kubelet_network_plugin_operations_errors_total counter
网络插件累计操作错误数统计,按照操作类型(operation_type)统计
# HELP kubelet_network_plugin_operations_total [ALPHA] Cumulative number of network plugin operations by operation type.
# TYPE kubelet_network_plugin_operations_total counter
网络插件累计操作数统计,按照操作类型(operation_type)统计
# HELP kubelet_node_name [ALPHA] The node's name. The count is always 1.
# TYPE kubelet_node_name gauge
node name
# HELP kubelet_pleg_discard_events [ALPHA] The number of discard events in PLEG.
# TYPE kubelet_pleg_discard_events counter
PLEG(pod lifecycle event generator) 丢弃的event数统计
# HELP kubelet_pleg_last_seen_seconds [ALPHA] Timestamp in seconds when PLEG was last seen active.
# TYPE kubelet_pleg_last_seen_seconds gauge
PLEG上次活跃的时间戳
# HELP kubelet_pleg_relist_duration_seconds [ALPHA] Duration in seconds for relisting pods in PLEG.
# TYPE kubelet_pleg_relist_duration_seconds histogram
PLEG relist pod时间分布
# HELP kubelet_pleg_relist_interval_seconds [ALPHA] Interval in seconds between relisting in PLEG.
# TYPE kubelet_pleg_relist_interval_seconds histogram
PLEG relist 间隔时间分布
# HELP kubelet_pod_start_duration_seconds [ALPHA] Duration in seconds for a single pod to go from pending to running.
# TYPE kubelet_pod_start_duration_seconds histogram
pod启动时间(从pending到running)分布, kubelet watch到pod时到pod中contianer都running后, watch各种source channel的pod变更
# HELP kubelet_pod_worker_duration_seconds [ALPHA] Duration in seconds to sync a single pod. Broken down by operation type: create, update, or sync
# TYPE kubelet_pod_worker_duration_seconds histogram
pod状态变化的时间分布, 按照操作类型(create update sync)统计, worker就是kubelet中处理一个pod的逻辑工作单位
# HELP kubelet_pod_worker_start_duration_seconds [ALPHA] Duration in seconds from seeing a pod to starting a worker.
# TYPE kubelet_pod_worker_start_duration_seconds histogram
kubelet watch到pod到worker启动的时间分布
# HELP kubelet_run_podsandbox_duration_seconds [ALPHA] Duration in seconds of the run_podsandbox operations. Broken down by RuntimeClass.Handler.
# TYPE kubelet_run_podsandbox_duration_seconds histogram
启动sandbox的时间分布
# HELP kubelet_run_podsandbox_errors_total [ALPHA] Cumulative number of the run_podsandbox operation errors by RuntimeClass.Handler.
# TYPE kubelet_run_podsandbox_errors_total counter
启动sanbox出现error的总数
# HELP kubelet_running_containers [ALPHA] Number of containers currently running
# TYPE kubelet_running_containers gauge
当前containers运行状态的统计, 按照container状态统计,created running exited
# HELP kubelet_running_pods [ALPHA] Number of pods that have a running pod sandbox
# TYPE kubelet_running_pods gauge
当前处于running状态pod数量
# HELP kubelet_runtime_operations_duration_seconds [ALPHA] Duration in seconds of runtime operations. Broken down by operation type.
# TYPE kubelet_runtime_operations_duration_seconds histogram
容器运行时的操作耗时(container在create list exec remove stop等的耗时)
# HELP kubelet_runtime_operations_errors_total [ALPHA] Cumulative number of runtime operation errors by operation type.
# TYPE kubelet_runtime_operations_errors_total counter
容器运行时的操作错误数统计(按操作类型统计)
# HELP kubelet_runtime_operations_total [ALPHA] Cumulative number of runtime operations by operation type.
# TYPE kubelet_runtime_operations_total counter
容器运行时的操作总数统计(按操作类型统计)
# HELP kubelet_started_containers_errors_total [ALPHA] Cumulative number of errors when starting containers
# TYPE kubelet_started_containers_errors_total counter
kubelet启动容器错误总数统计(按code和container_type统计)
code包括ErrImagePull ErrImageInspect ErrImagePull ErrRegistryUnavailable ErrInvalidImageName等
container_type一般为"container" "podsandbox"
# HELP kubelet_started_containers_total [ALPHA] Cumulative number of containers started
# TYPE kubelet_started_containers_total counter
kubelet启动容器总数
# HELP kubelet_started_pods_errors_total [ALPHA] Cumulative number of errors when starting pods
# TYPE kubelet_started_pods_errors_total counter
kubelet启动pod遇到的错误总数(只有创建sandbox遇到错误才会统计)
# HELP kubelet_started_pods_total [ALPHA] Cumulative number of pods started
# TYPE kubelet_started_pods_total counter
kubelet启动的pod总数
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
统计cpu使用率
# HELP process_max_fds Maximum number of open file descriptors.
# TYPE process_max_fds gauge
允许进程打开的最大fd数
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
当前打开的fd数量
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
进程驻留内存大小
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
进程启动时间
# HELP rest_client_request_duration_seconds [ALPHA] Request latency in seconds. Broken down by verb and URL.
# TYPE rest_client_request_duration_seconds histogram
请求apiserver的耗时统计(按照url和请求类型统计verb)
# HELP rest_client_requests_total [ALPHA] Number of HTTP requests, partitioned by status code, method, and host.
# TYPE rest_client_requests_total counter
请求apiserver的总次数(按照返回码code和请求类型method统计)
# HELP storage_operation_duration_seconds [ALPHA] Storage operation duration
# TYPE storage_operation_duration_seconds histogram
存储操作耗时(按照存储plugin(configmap emptydir hostpath 等 )和operation_name分类统计)
# HELP volume_manager_total_volumes [ALPHA] Number of volumes in Volume Manager
# TYPE volume_manager_total_volumes gauge
本机挂载的volume数量统计(按照plugin_name和state统计
plugin_name包括"host-path" "empty-dir" "configmap" "projected")
state(desired_state_of_world期状态/actual_state_of_world实际状态)cadivisor指标梳理
# HELP container_cpu_cfs_periods_total Number of elapsed enforcement period intervals.
# TYPE container_cpu_cfs_periods_total counter
cfs时间片总数, 完全公平调度的时间片总数(分配到cpu的时间片数)
# HELP container_cpu_cfs_throttled_periods_total Number of throttled period intervals.
# TYPE container_cpu_cfs_throttled_periods_total counter
容器被throttle的时间片总数
# HELP container_cpu_cfs_throttled_seconds_total Total time duration the container has been throttled.
# TYPE container_cpu_cfs_throttled_seconds_total counter
容器被throttle的时间
# HELP container_file_descriptors Number of open file descriptors for the container.
# TYPE container_file_descriptors gauge
容器打开的fd数
# HELP container_memory_usage_bytes Current memory usage in bytes, including all memory regardless of when it was accessed
# TYPE container_memory_usage_bytes gauge
容器内存使用量,单位byte
# HELP container_network_receive_bytes_total Cumulative count of bytes received
# TYPE container_network_receive_bytes_total counter
容器入方向的流量
# HELP container_network_transmit_bytes_total Cumulative count of bytes transmitted
# TYPE container_network_transmit_bytes_total counter
容器出方向的流量
# HELP container_spec_cpu_period CPU period of the container.
# TYPE container_spec_cpu_period gauge
容器的cpu调度单位时间
# HELP container_spec_cpu_quota CPU quota of the container.
# TYPE container_spec_cpu_quota gauge
容器的cpu规格 ,除以单位调度时间可以计算核数
# HELP container_spec_memory_limit_bytes Memory limit for the container.
# TYPE container_spec_memory_limit_bytes gauge
容器的内存规格,单位byte
# HELP container_threads Number of threads running inside the container
# TYPE container_threads gauge
容器当前的线程数
# HELP container_threads_max Maximum number of threads allowed inside the container, infinity if value is zero
# TYPE container_threads_max gauge
允许容器启动的最大线程数(七)K8s-KubeProxy组件监控
KubeProxy 主要负责节点的网络管理,它在每个节点都会存在,是通过10249端口暴露监控指标。
这里指标采集我们也用上面的方法,使用Prometheus-agent的方式
(1)配置Prometheus-agent configmap配置文件
在之前的configmap的yaml文件中添加名为kube-proxy的job模块字段,添加完记得重新加载yaml文件和Prometheus-agent的pod
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-agent-conf
labels:
name: prometheus-agent-conf
namespace: flashcat
data:
prometheus.yml: |-
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'controller-manager'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-controller-manager;https-metrics
- job_name: 'scheduler'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-scheduler;https
- job_name: 'etcd'
kubernetes_sd_configs:
- role: endpoints
scheme: http
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;etcd;http
- job_name: 'kubelet'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-kubelet;https
##这里是添加的模块
- job_name: 'kube-proxy'
kubernetes_sd_configs:
- role: endpoints
scheme: http
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-proxy;http
remote_write:
- url: 'http://192.168.120.17:17000/prometheus/v1/write'(2)配置kube-proxy的endpoints
跟之前一样,先查看有没有这个kube-proxy的endpoints如果没有添加。
[root@k8s-master ~]# kubectl get endpoints -A | grep kube-pro
## 如果没有 添加service
vim kube-proxy-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: proxy
name: kube-proxy
namespace: kube-system
spec:
clusterIP: None
selector:
k8s-app: kube-proxy
ports:
- name: http
port: 10249
protocol: TCP
targetPort: 10249
sessionAffinity: None
type: ClusterIP(3)更改kube-proxy的metricsbindAddress
查看 kube-proxy 的10249端口是否绑定到127.0.0.1了,如果是就修改成0.0.0.0,通过kubectl edit cm -n kube-system kube-proxy修改metricsBindAddress即可
[root@k8s-master ~]# kubectl edit cm -n kube-system kube-proxy
......
......
......
kind: KubeProxyConfiguration
metricsBindAddress: "0.0.0.0" ## 这里修改为0.0.0.0 即可
mode: ""
nodePortAddresses: null
oomScoreAdj: nul(4)指标测试
在夜莺的web页面输入指标测试:
kubeproxy_network_programming_duration_seconds_bucket

导入监控大盘, 仪表盘json文件:https://github.com/flin/inputs/kube_proxy/dashboard-by-ident.json
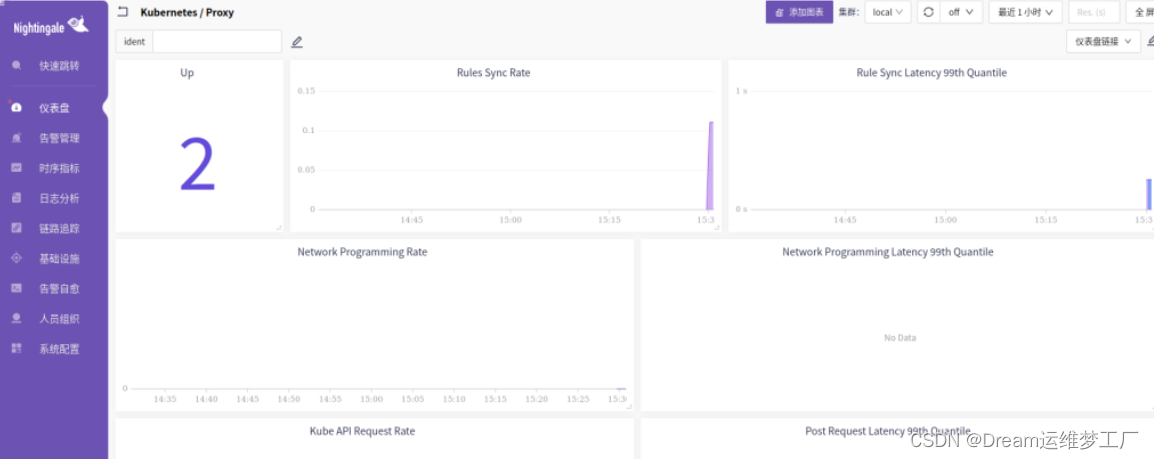
kube-proxy关键指标含义:
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
gc时间
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
goroutine数量
# HELP go_threads Number of OS threads created.
# TYPE go_threads gauge
线程数量
# HELP kubeproxy_network_programming_duration_seconds [ALPHA] In Cluster Network Programming Latency in seconds
# TYPE kubeproxy_network_programming_duration_seconds histogram
service或者pod发生变化到kube-proxy规则同步完成时间指标含义较复杂,参照https://github.com/kubernetes/community/blob/master/sig-scalability/slos/network_programming_latency.md
# HELP kubeproxy_sync_proxy_rules_duration_seconds [ALPHA] SyncProxyRules latency in seconds
# TYPE kubeproxy_sync_proxy_rules_duration_seconds histogram
规则同步耗时
# HELP kubeproxy_sync_proxy_rules_endpoint_changes_pending [ALPHA] Pending proxy rules Endpoint changes
# TYPE kubeproxy_sync_proxy_rules_endpoint_changes_pending gauge
endpoint 发生变化后规则同步pending的次数
# HELP kubeproxy_sync_proxy_rules_endpoint_changes_total [ALPHA] Cumulative proxy rules Endpoint changes
# TYPE kubeproxy_sync_proxy_rules_endpoint_changes_total counter
endpoint 发生变化后规则同步的总次数
# HELP kubeproxy_sync_proxy_rules_iptables_restore_failures_total [ALPHA] Cumulative proxy iptables restore failures
# TYPE kubeproxy_sync_proxy_rules_iptables_restore_failures_total counter
本机上 iptables restore 失败的总次数
# HELP kubeproxy_sync_proxy_rules_last_queued_timestamp_seconds [ALPHA] The last time a sync of proxy rules was queued
# TYPE kubeproxy_sync_proxy_rules_last_queued_timestamp_seconds gauge
最近一次规则同步的请求时间戳,如果比下一个指标 kubeproxy_sync_proxy_rules_last_timestamp_seconds 大很多,那说明同步 hung 住了
# HELP kubeproxy_sync_proxy_rules_last_timestamp_seconds [ALPHA] The last time proxy rules were successfully synced
# TYPE kubeproxy_sync_proxy_rules_last_timestamp_seconds gauge
最近一次规则同步的完成时间戳
# HELP kubeproxy_sync_proxy_rules_service_changes_pending [ALPHA] Pending proxy rules Service changes
# TYPE kubeproxy_sync_proxy_rules_service_changes_pending gauge
service变化引起的规则同步pending数量
# HELP kubeproxy_sync_proxy_rules_service_changes_total [ALPHA] Cumulative proxy rules Service changes
# TYPE kubeproxy_sync_proxy_rules_service_changes_total counter
service变化引起的规则同步总数
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
利用这个指标统计cpu使用率
# HELP process_max_fds Maximum number of open file descriptors.
# TYPE process_max_fds gauge
进程可以打开的最大fd数
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
进程当前打开的fd数
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
统计内存使用大小
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
进程启动时间戳
# HELP rest_client_request_duration_seconds [ALPHA] Request latency in seconds. Broken down by verb and URL.
# TYPE rest_client_request_duration_seconds histogram
请求 apiserver 的耗时(按照url和verb统计)
# HELP rest_client_requests_total [ALPHA] Number of HTTP requests, partitioned by status code, method, and host.
# TYPE rest_client_requests_total counter
请求 apiserver 的总数(按照code method host统计)最后的最后
夜莺监控k8s的方法夜莺的官网也做了合计专栏,有兴趣的伙伴可以去看看Kubernetes监控专栏,无论是指标还是原理,都做了解释初识Kubernetes -(flashcat.cloud)。如果在部署中遇到问题欢迎在本文章留言,24小时内必回复。
看完这一期肯定会有小伙伴会有疑问,我业务都跑pod上面,光监控这些组件没啥大用啊,我想知道总共有几个 Namespace,有几个 Service、Deployment、Statefulset,某个 Deployment 期望有几个 Pod 要运行,实际有几个 Pod 在运行,这些既有的指标就无法回答了。当然这一点肯定重中之重,这个问题我们下一期详细讲解使用使用 kube-state-metrics (KSM)监控 Kubernetes 对象,俗称KSM来监听各个Kubernetes对象的状态,生产指标暴露出来让我们查看。 还有下一期还会讲用daemonset的最佳实践方案来采集监控。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结