您现在的位置是:首页 >技术杂谈 >C语言——数组网站首页技术杂谈
C语言——数组
哈喽,大家好,今天我们要学习的是数组的相关知识。
目录
1.什么是数组
数组是类型相同的数据元素的集合,是C语言中的一种构造数据类型,这些元素会顺序地储存在内存的某段区域。
简单来说:数组是一组相同类型元素的集合
2.一维数组
下面,我们开始学习一维数组:
2.1一维数组的创建和初始化
数组的创建
如何来创建一个一维数组呢?

根据上面的表达式,我们来创建一个int类型的数组吧:

字符型数组的创建:

在创建了简单的一维数组后,我们来看看下面的创建方法是否正确:

当我们在VS2022上运行时,编译器产生了报错,显然上面创建数组的方法是错误的。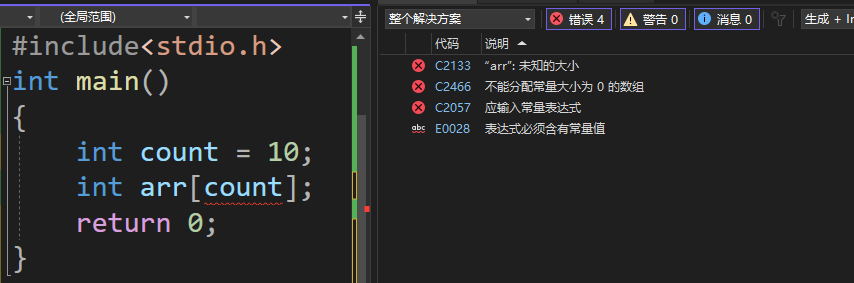
在上面报错中,显示“应输入常量表达式” ,因此数组后面方括号内的值不能使用变量表达式。
这里涉及到了C语言标准的问题:
在C99标准之前,数组的大小只能是常量表达式
在C99标准中引入了变长数组的概念,使得数组在创建的时候可以使用变量,带这样的数组不能初始化。
在VS2022编译器中不支持C99中的变长数组,因此会报错。
数组的初始化
数组的初始化是指,在创建数组的同时给数组的内容一些合理初始值(初始化)。例如:

数组在创建的时候如果想不指定数组的确定的大小就得初始化。数组的元素个数根据初始化的内容来确 定。 但是对于下面的代码要区分,内存中如何分配。
完全初始化:
![]()
不完全初始化,剩余元素默认都是0:

如果在创建数组的同时进行初始化,则可以省略数组大小,数组大小就是元素的个数

注意:省略数组大小,数组必须初始化。
字符数组的初始化方式:

arr1和arr2的大小有有所不同的:

2.2一维数组的使用
C语言规定,数组的每个元素都有对应的下标,而且下标都是从0开始的
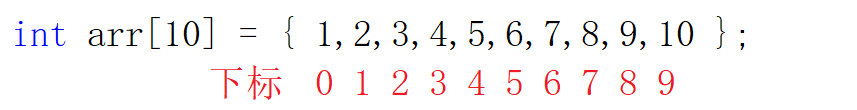
我们可以通过下标来访问数组元素,例如 arr[5] 的值就等于 6

用循环遍历所有下标,就可以打印出数组的所有元素:

程序走起:
总结:
1. 数组是使用下标来访问的,下标是从0开始。
2. 数组的大小可以通过计算得到。

2.3一位数组在内存中的存储
接下来我们探讨数组在内存中的存储:
#include<stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < sz; i++)
{
printf("&arr[%d]=%p
", i, &arr[i]);
}
return 0;
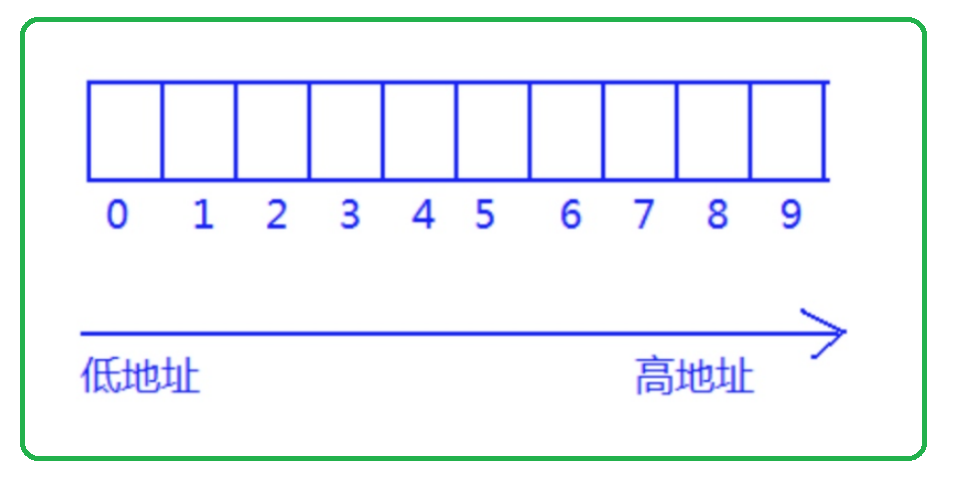
}通过上述代码,我们可以将一个整型数组中所有元素的地址打印出来:

仔细观察输出的结果,我们知道,随着数组下标的增长,元素的地址,也在有规律的递增。 由此可以得出结论:数组在内存中是连续存放的。
3.二维数组
学完一维数组,我们开始学习二维数组:
假如我们想要存放多组数据,我们就需要用到二维数组了
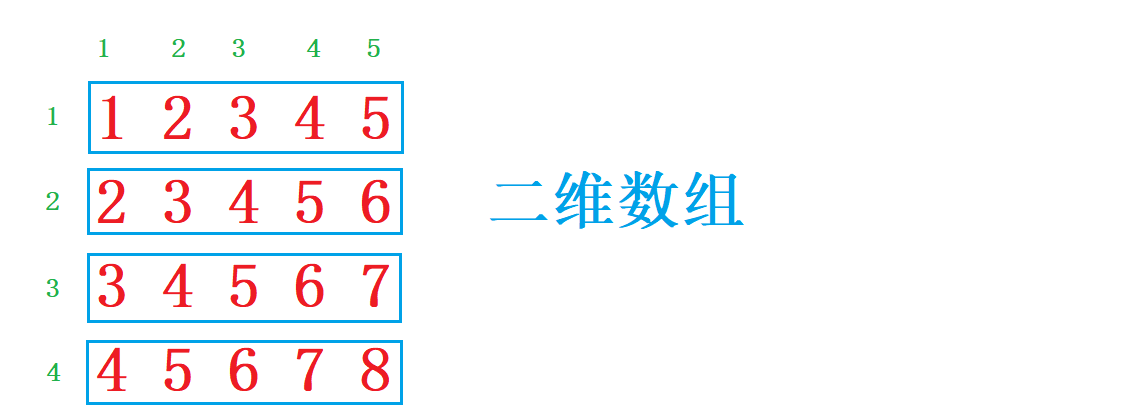
3.1二维数组的创建和初始化
创建二维数组:

二维数组的初始化:
在一维数组里我们已经知道,初始化就是在创建数组的同时给数组的内容一些合理初始值,二维数组也如此:

我们可以把每组大括号看成是一位数组。
当然,只用一组大括号也可以完成二维数组的初始化:


或者是这样初始化:


当然,不建议使用这种初始化方法,因为不便于我们直接观察数组元素的值。
二维数组初始化了,行是可以省略的,但列是不能省略的
行和列都省略编译器报错:

可以省略行,不能省略列:

4.2二维数组的使用
二维数组的行和列都是从0开始的,通过行号和列号可以访问数组中某个元素的值:

打印所有元素只需要两层for循环遍历:
#include<stdio.h>
int main()
{
int arr[4][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7},{4,5,6,7,8} };
int i = 0, j = 0;
for (i = 0; i < 4; i++)
{
for (j = 0; j < 5; j++)
{
printf("%d ", arr[i][j]);
}
printf("
");
}
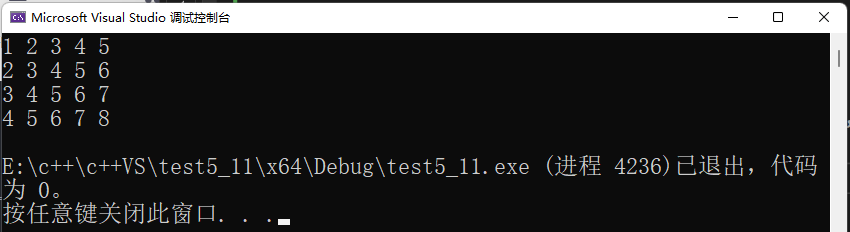
return 0;
}
4.3二位数组在内存中的存储
#include<stdio.h>
int main()
{
int arr[4][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7},{4,5,6,7,8} };
int i = 0, j = 0;
for (i = 0; i < 4; i++)
{
for (j = 0; j < 5; j++)
{
printf("&arr[%d][%d] = %p
",i,j, &arr[i][j]);
}
}
return 0;
}如果我们将上面二维数组每个元素的地址给打印出来,我们会得到下图的结果:
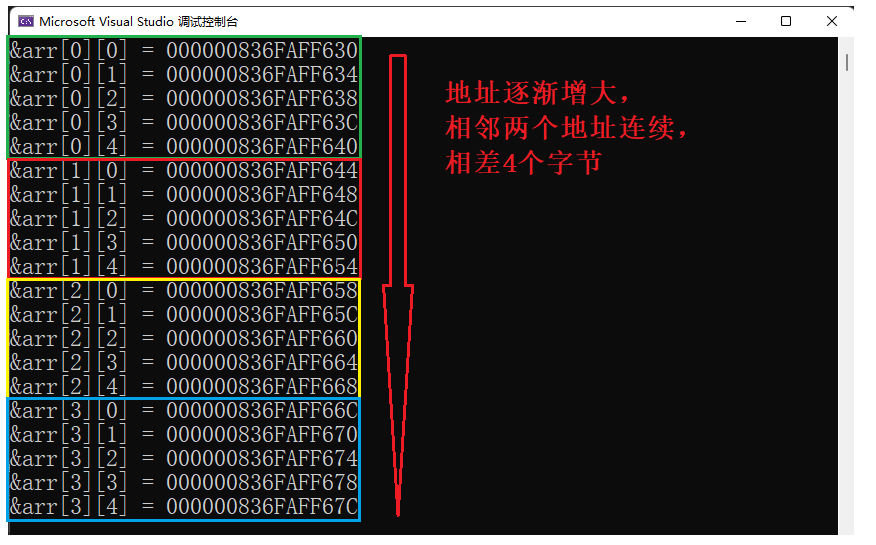
事实上,二维数组的每个元素在内存中都是连续存放的 ,列决定了每一行有多少个元素,所以 行可以省略的,列不能省略。

4.数组越界
数组的下标是有范围限制的。
数组的下标规定是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1。
所以数组的下标如果小于0,或者大于n-1,就是数组越界访问了,超出了数组合法空间的访问。
C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程序就 是正确的, 所以程序员写代码时,最好自己做越界的检查
这是数组越界访问的例子:
#include<stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int i = 0;
for (i = 0; i <= 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}程序输出的结果如下,其中最后一个值是是由于数组越界的结果

5.冒泡排序

含优化的代码献上:
#include<stdio.h>
//冒泡排序——升序
void bubble_sort(int arr[], int sz)
{
int i = 0, j = 0;
for (i = 0; i < sz - 1; i++)
{
//优化代码
int flag = 1;
for (j = 0; j < sz - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
//交换
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = 0;
}
}
if (flag == 1)
{
break;
}
}
}
int main()
{
int arr[10] = { 0 };
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
for (i = 0; i < sz; i++)
{
scanf("%d", &arr[i]);
}
//排序
bubble_sort(arr, sz);
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}对数组名的理解:
数组名通常情况下是数组首元素的地址,带是有两个例外:
- sizeof(数组名)数组名单独放在sizeof()内部,这里的数组名表示整个数组,计算的是整个数组的大小。
- &数组名,这里的数组名也表示整个数组,这里取出来的是整个数组的地址。
除此之外所有遇到的数组名都是表示数组首元素的地址。
总结:今天我们学习了一维数组和二维数组的相关知识,如果我写的有什么的不好之处,请在文章下方给出你宝贵的意见。如果觉得我写的好的话请点个赞赞和关注哦~?






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结