您现在的位置是:首页 >技术杂谈 >多模态:BLIP-2论文讲解网站首页技术杂谈
多模态:BLIP-2论文讲解
多模态:BLIP-2论文讲解
Introduction
多模态学习在近两年我们已经见证了他的快速发展,由于它是视觉-语言的交叉领域,我们自然地期待可以借助目前风头正盛的LLM来辅助完成多模态任务。
在这篇论文中,作者提出了一个通用、高效的方法通过预训练的视觉模型与语言模型。
视觉模型可以提供高质量的视觉表示,语言模型可以一共强大的语言生成与zero-shot迁移能力。 为了防止在后续的训练中二者counteract,所以作者选择冻结二者的参数。
想利用这二者的优点,一个关键要素就是使它们alignment,于是作者提出了Querying Transformer(Q- former)。如下图:
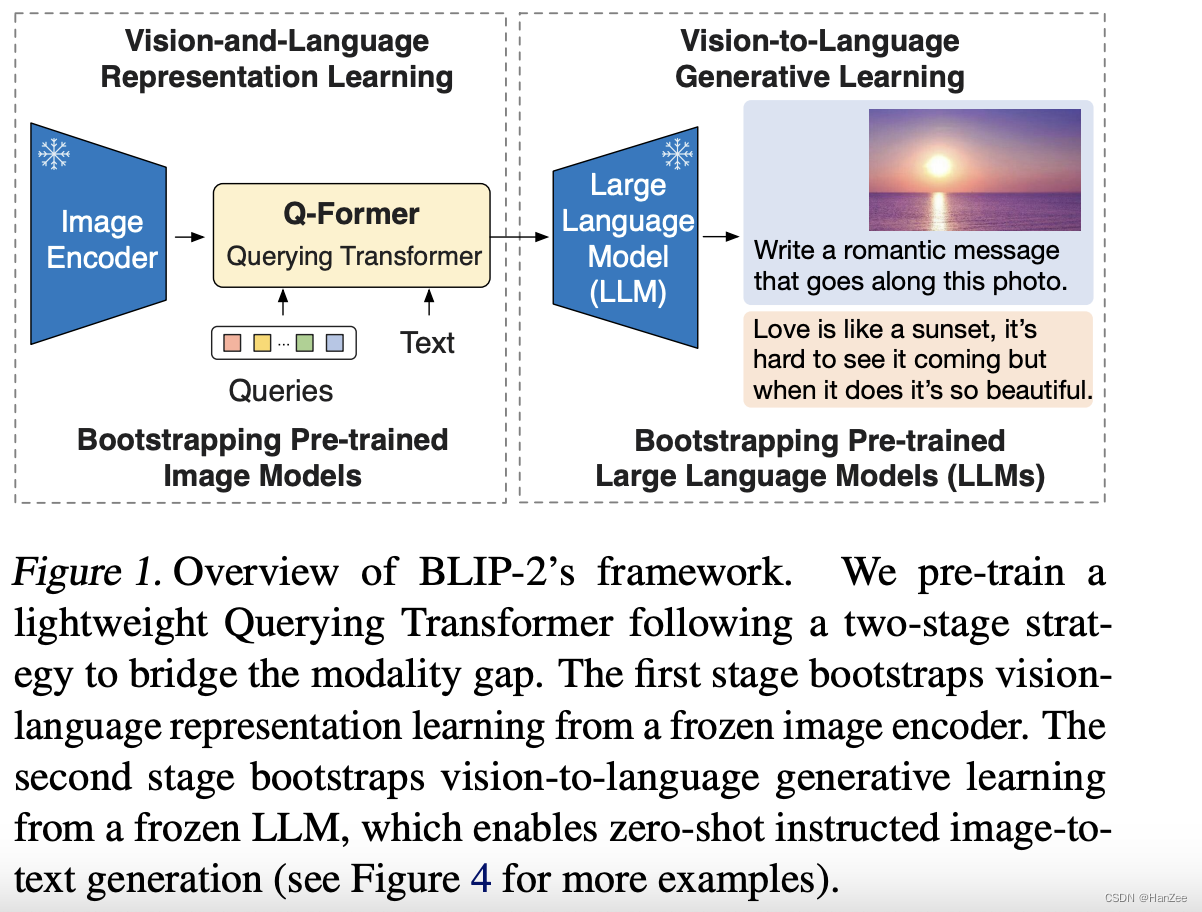
它可以看作冻结后语言模型与视觉模型之间的强梁,可以把视觉信息中对语言模型有用的信息喂给语言模型,让语言模型生成我们想要的文本。
Method
该方法分为两个阶段:
- 通过一个冻结的image- encoder 学习 vision- language表征 model。
- 通过一个冻结的LLM学习vision - language 生成文本。
第一阶段
关于模型架构,就是视觉模型与语言模型中间多了个q- former用来做alignment:
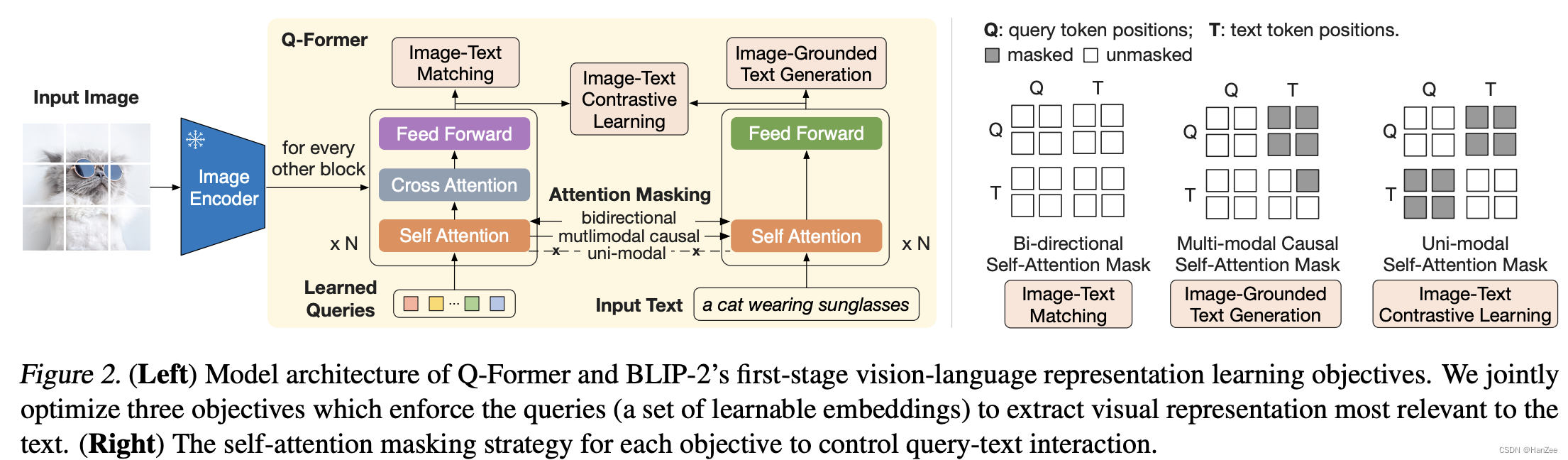
这部分的输入是 object query 与 input text 的concatnate,其中self- attention层共享参数。
然后分别计算3个loss,来初步的对text与image结合。
Image- Text Contrastive Learning(ITC):
通过image transformer 得到输出的query 特征,text通过 text transformer 得到 text 特征,然后用每一个query 与text 特征中的cls token计算相似度,求出最相似的一个。
在此期间,为了防止信息泄漏,采用uni-attention mask.
Image- grounded text generation:
通过 q- former去生成文本,与GPT的损失类似,由于text transformer是不能与image encoding直接交互的,所以作者采取的策略是通过 query 去生成文字,query 之间计算attention 是双向的,生成文字时不能看见后面的内容。
把文本的第一关token从cls换成dec,用来告诉解码器开始解码。
Image-Text Matching:
通过Bi- directional self- attention mask,然后执行 cross attention 与feed forward,然后输出层为 binary classification。
第二阶段

通过第一阶段训练的q- former,可以初步的align 视觉 与 文本,为了进一步的alignment,当q-former输出 query 后, 在后面链接一层linear,然后送入LLM(也可以加上prompt),损失函数采用gpt 预训练阶段的文字接龙损失。
encoder- decoder 不在说明
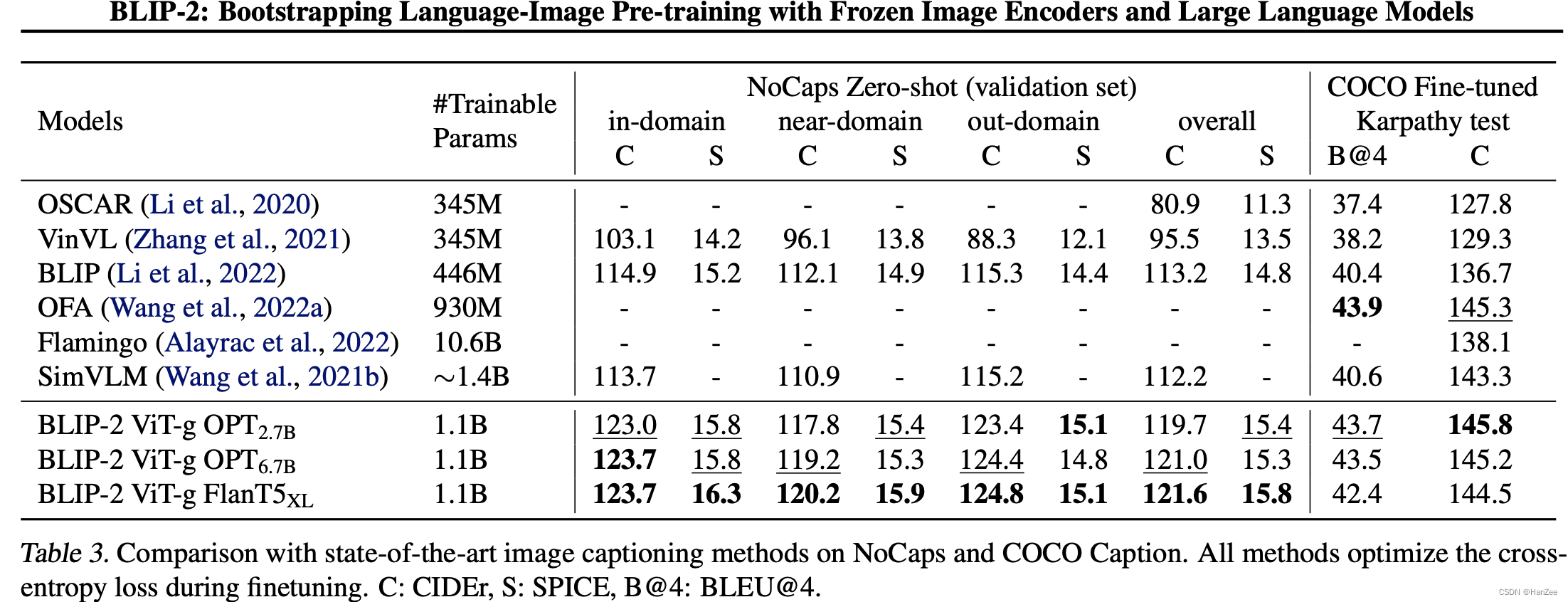
实验






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结